In Andrew Ng's Deep Learning Coursera classes, there's an assignment on trigger word detection (example, not mine: jupyter notebook).
In the assignment, they simply provided the trained model because they claim it took several hours to train using the 4000+ training examples with GPUs.
Instead of just using the provided model, I tried creating my own training examples using their functions, and then training the model from scratch. The raw audio files remain unchanged. There were 2 background files, so I made sure that there were 2000 training examples for each background:
n_train_per_bg = 2000
n_train = len(backgrounds)*n_train_per_bg
orig_X_train = np.empty((n_train, Tx, n_freq))
orig_Y_train = np.empty((n_train, Ty , 1))
for bg in range(len(backgrounds)):
for n in range(n_train_per_bg):
print("bg: {}, n: {}".format(bg, n))
x, y = create_training_example(backgrounds[bg], activates, negatives)
orig_X_train[bg*n_train_per_bg + n, :, :] = x.T
orig_Y_train[bg*n_train_per_bg + n, :, :] = y.T
np.save('./XY_train/orig_X_train.npy', orig_X_train)
np.save('./XY_train/orig_Y_train.npy', orig_Y_train)
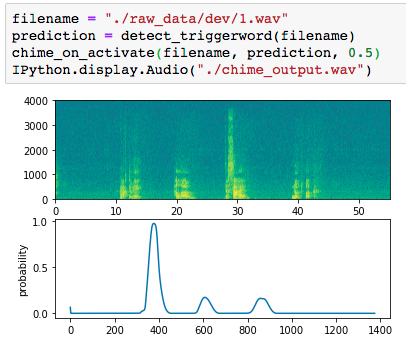
However, after running for an hour, the results I got were quite disappointing. One of the later examples in the same exercise shows their properly functioning model displaying a probability spike when the trigger word "activate" is being detected around the 400 mark on the x-axis:
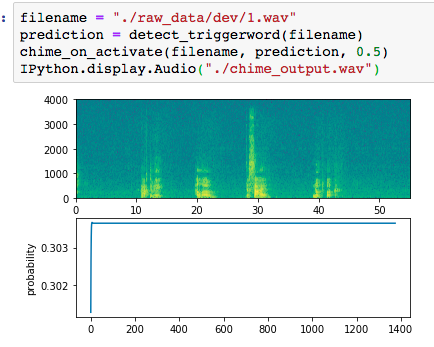
and here's mine, which not only isn't detecting anything, but is simply flatlining!:
The only modifications I made were:
- changing the learning rate for the Adam optimizer from 0.0001 to 0.0010
- setting the
batch_sizeto 600
I understand that I probably still need to incorporate many more epochs, but am quite surprised that the output probability would be flat with no change. Am I doing something horribly wrong or do I just have to trust that the model will converge to something that makes more sense?