Possible explanation is here in the comment
In SQL Server 2014 Enterprise Edition (64-bit) - I am trying to read from a View. A standard query contains just an ORDER BYand OFFSET-FETCH clause like this.
Approach 1
SELECT
*
FROM Metadata
ORDER BY
AgeInHours ASC,
RankingPoint DESC,
PublishDate DESC
OFFSET 150000 ROWS
FETCH NEXT 40 ROWS ONLY
However, this fairly simple query performs almost 9 times slower (noticable when skipping large number of rows like 150k) than the following query which returns the same result.
In this case I am reading the primary key first and then using that as a parameter for WHERE...IN function
Approach 2
SELECT
*
FROM Metadata
WHERE NewsId IN (
SELECT
NewsId
FROM Metadata
ORDER BY
AgeInHours ASC,
RankingPoint DESC,
PublishDate DESC
OFFSET 150000 ROWS
FETCH NEXT 40 ROWS ONLY
)
ORDER BY
AgeInHours ASC,
RankingPoint DESC,
PublishDate DESC
Bench-marking these two shows this difference
(40 row(s) affected)
SQL Server Execution Times:
CPU time = 14748 ms, elapsed time = 3329 ms.
(40 row(s) affected)
SQL Server Execution Times:
CPU time = 3828 ms, elapsed time = 469 ms.
I have indexes on the primary key, PubilshDate and their fragmentation is very low. I have also tried to run similar queries against the database table, but in every cases the second approach yields great performance gains. I have also tested this on SQL Server 2012.
Can someone explain what is going on?
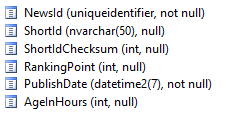
Schema
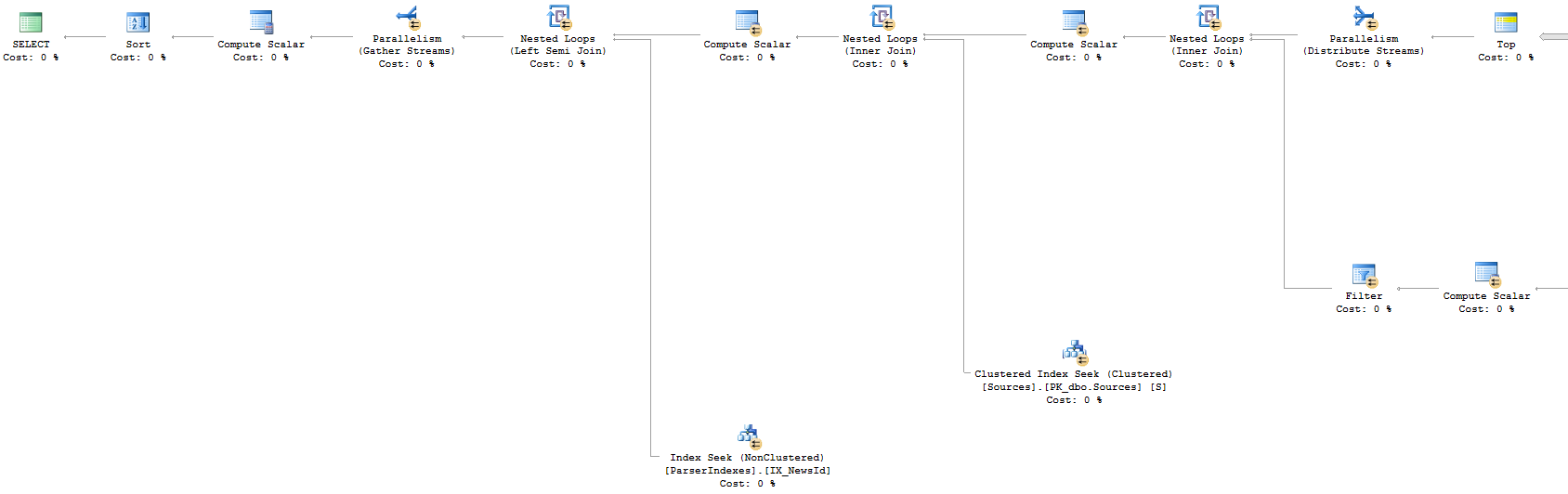
Approach 1: Execution Plan

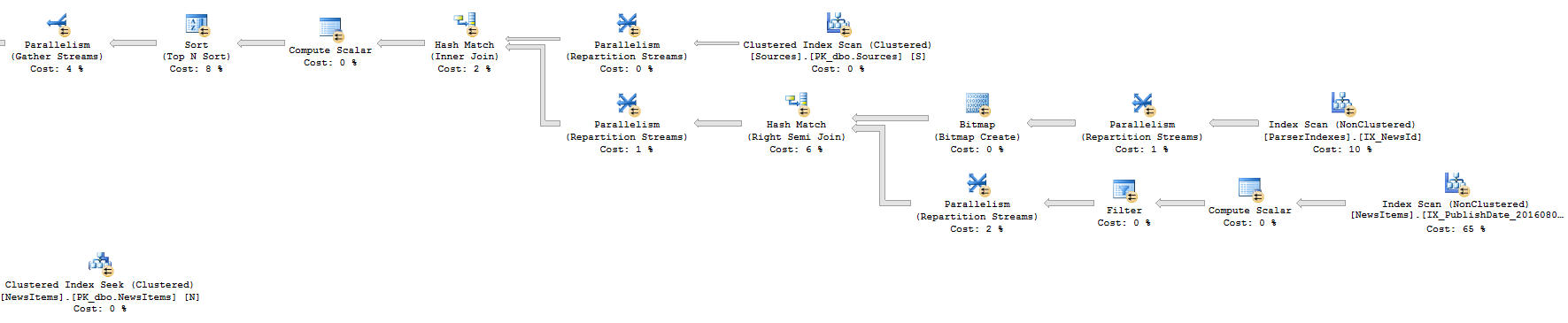
Approach 2: Execution Plan (Left part)
Approach 2: Execution Plan (Right part)
IDcolumn, what happens? I suspect the*asterisk slows down the query because it forces it to scan the entire columns . – MilitaryId). The puzzling thing is, in the second query it is still reading the same amount of data when I usedWHERE-INclause - but isn't taking time. What is happening behind the scene? – SplintNewsId, i referred this toIdfor simplification (updated the post). – Splint*), the query slows down. – Splint*, the query slows down. BTW, I am doing the same in the second query. – SplintORDER BYcolumn, the execution time went down to289ms. Does this mean - in such situation (large datasets, manyORDER BYcolumns) - we should always read the primary key and pass it in theWHERE...INclause, instead of running a simpleSELECT * FROM ... ORDER BYquery?. Is there any article you'd recommend for further reading? – Splint