I'm trying a very simple optimization in Tensorflow- the problem of matrix factorization. Given a matrix V (m X n), decompose it into W (m X r) and H (r X n). I'm borrowing a gradient descent based tensorflow based implementation for matrix factorization from here.
Details about the matrix V. In its original form, the histogram of entries would be as follows:

To bring the entries on a scale of [0, 1], I perform the following preprocessing.
f(x) = f(x)-min(V)/(max(V)-min(V))
After normalization, the histogram of data would look like the following:
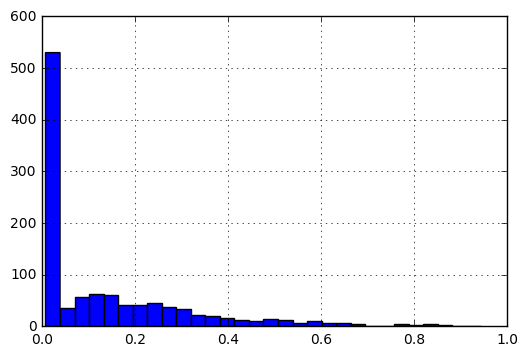
My questions are:
- Given the nature of data: between 0 and 1 and most entries closer to 0 than 1, what would be the optimal initialisation for
WandH? - How should the learning rates be defined based on different cost function:
|A-WH|_Fand|(A-WH)/A|?
The minimal working example would be as follows:
import tensorflow as tf
import numpy as np
import pandas as pd
V_df = pd.DataFrame([[3, 4, 5, 2],
[4, 4, 3, 3],
[5, 5, 4, 4]], dtype=np.float32).T
Thus, V_df looks like:
0 1 2
0 3.0 4.0 5.0
1 4.0 4.0 5.0
2 5.0 3.0 4.0
3 2.0 3.0 4.0
Now, the code defining W, H
V = tf.constant(V_df.values)
shape = V_df.shape
rank = 2 #latent factors
initializer = tf.random_normal_initializer(mean=V_df.mean().mean()/5,stddev=0.1 )
#initializer = tf.random_uniform_initializer(maxval=V_df.max().max())
H = tf.get_variable("H", [rank, shape[1]],
initializer=initializer)
W = tf.get_variable(name="W", shape=[shape[0], rank],
initializer=initializer)
WH = tf.matmul(W, H)
Defining the cost and optimizer:
f_norm = tf.reduce_sum(tf.pow(V - WH, 2))
lr = 0.01
optimize = tf.train.AdagradOptimizer(lr).minimize(f_norm)
Running the session:
max_iter=10000
display_step = 50
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in xrange(max_iter):
loss, _ = sess.run([f_norm, optimize])
if i%display_step==0:
print loss, i
W_out = sess.run(W)
H_out = sess.run(H)
WH_out = sess.run(WH)
I realized that when I used something like initializer = tf.random_uniform_initializer(maxval=V_df.max().max()), I got matrices W and H such that their product was much greater than V. I also realised that keeping learning rate (lr) to be .0001 was probably too slow.
I was wondering if there are any rules of thumb for defining good initializations and learning rate for the problem of matrix factorization.
Wand/orHor canWandHbe arbitrary matrices? – Disproportion