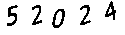Im using this piece of code from the website but its not accurate enough
const worker1 = createWorker();
const worker2 = createWorker();
await worker1.load();
await worker2.load();
await worker1.loadLanguage("eng");
await worker2.loadLanguage("eng");
await worker1.initialize("eng");
await worker2.initialize("eng");
scheduler.addWorker(worker1);
scheduler.addWorker(worker2);
/** Add 10 recognition jobs */
const {
data: { text }
} = await scheduler.addJob("recognize", image);
this is the type of image i'm trying to read its text:

thou it seems simple and easy ,sometimes tesseract fails to read it . is there any better alternatives to tesseract.js or any way to improve the accuracy?