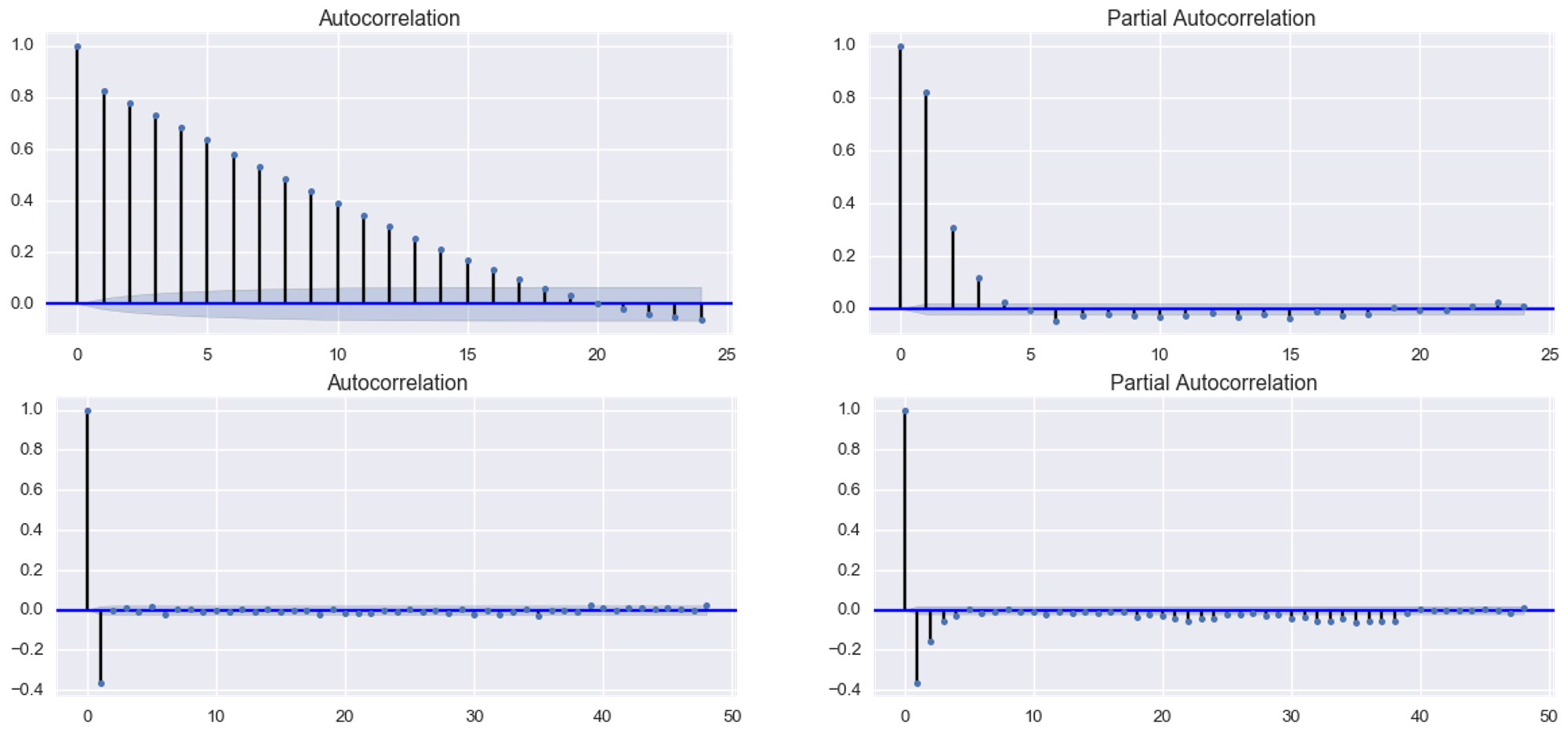
In the model you specify (5, 1, 2), you set d = 1. This means that you are differencing the data by 1, or in other words, performing a shift of your entire range of time-related observations so as to minimize the residuals of the fitted model.
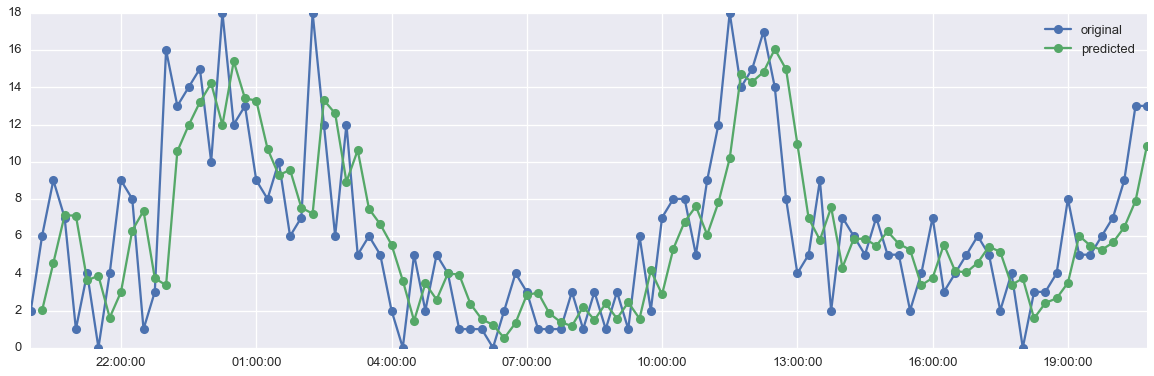
Sometimes, setting d to 1 will result in a ACF / PACF plot with fewer and / or less dramatic spikes (i.e. less extreme residuals). In such cases, if you use the model you have fitted to predict future values, your predictions will deviate less dramatically from the observations you have if you apply differencing.
Differencing is accomplished through Y(differenced) = Y(t) - Y(t-d), where Y(t) refers to observed value Y at timeindex t, and d refers to the order of differencing you apply. When you use differencing, your entire range of observations basically shifts to the right. This means you lose some data at the left edge of your time series. How many time points you lose depends on the order of differencing d you use. This is where your observed shift comes from.
This page may offer a more elaborate explanation (make sure to click around a bit and explore the other pages on there if you want a treatment of the whole process of fitting an ARIMA model).
Hope this helps (or at least puts your mind at ease about the shift)!
Bests,
Evert
{kind=link}
{kind=link}