I think in terms of relational algebra you are asking for the set of ActorContent minus the set of ActorContent constrained by actor = actor and meanOfPayment = meanOfPayment and createDate < createDate. So, the way to think of it is to get the second set from a cross product of ActorContent with ac1.meanOfPayment = ac2.meanOfPayment and ac1.actor = ac2.actor and ac1.createDate < ac2.createDate. Then subtract this set from the set of ActorContent. I haven't looked to see if it is more efficient than using MAX and Group By By example:
@Query("select ac from ActorContent ac where ac.id not in (select ac1.id from ActorContent ac1, ActorContent ac2 where ac1.meanOfPayment = ac2.meanOfPayment and ac1.actor = ac2.actor and ac1.createDate < ac2.createDate)")
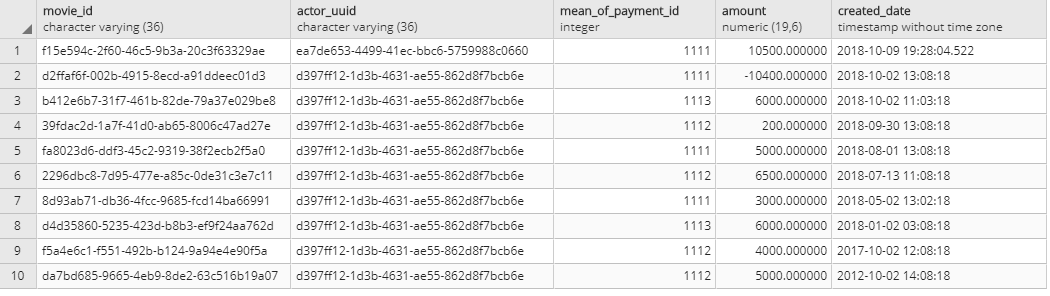
This gives me the first four rows in the UPPER table representing the first actor and his only meanOfPayment and the second actor and his most recent payments for all three meanOfPayments.
ActorContent [id=1, actor=Actor [id=1], meanOfPayment=MeanOfPayment [id=1], amount=10500.00, createDate=2018-10-09 00:00:00.887]
ActorContent [id=2, actor=Actor [id=2], meanOfPayment=MeanOfPayment [id=1], amount=-10400.00, createDate=2018-10-02 00:00:00.887]
ActorContent [id=3, actor=Actor [id=2], meanOfPayment=MeanOfPayment [id=3], amount=6000.00, createDate=2018-10-02 00:00:00.887]
ActorContent [id=4, actor=Actor [id=2], meanOfPayment=MeanOfPayment [id=2], amount=200.00, createDate=2018-09-30 00:00:00.887]
After that you may want to optimize the query by join fetching the Actor and MeanOfPayment instances. By Example:
@Query("select ac from ActorContent ac left outer join fetch ac.actor left outer join fetch ac.meanOfPayment where ac.id not in (select ac1.id from ActorContent ac1, ActorContent ac2 where ac1.meanOfPayment = ac2.meanOfPayment and ac1.actor = ac2.actor and ac1.createDate < ac2.createDate)")
This results in the following hibernate generated SQL query:
select actorconte0_.id as id1_1_0_, actor1_.id as id1_0_1_, meanofpaym2_.id as id1_2_2_, actorconte0_.actor_id as actor_id4_1_0_, actorconte0_.amount as amount2_1_0_, actorconte0_.create_date as create_d3_1_0_, actorconte0_.mean_of_payment_id as mean_of_5_1_0_ from actor_content actorconte0_ left outer join actor actor1_ on actorconte0_.actor_id=actor1_.id left outer join mean_of_payment meanofpaym2_ on actorconte0_.mean_of_payment_id=meanofpaym2_.id where actorconte0_.id not in (select actorconte3_.id from actor_content actorconte3_ cross join actor_content actorconte4_ where actorconte3_.mean_of_payment_id=actorconte4_.mean_of_payment_id and actorconte3_.actor_id=actorconte4_.actor_id and actorconte3_.create_date<actorconte4_.create_date)
Of course if you want a specific Actor then just add that to the where clause.
@Query("select ac from ActorContent ac left outer join fetch ac.actor left outer join fetch ac.meanOfPayment where ac.actor.id = :actorId and ac.id not in (select ac1.id from ActorContent ac1, ActorContent ac2 where ac1.meanOfPayment = ac2.meanOfPayment and ac1.actor = ac2.actor and ac1.createDate < ac2.createDate)")
public List<ActorContent> findLatestForActor(@Param("actorId") Integer actorId);
and that gives me the "top three rows"
ActorContent [id=2, actor=Actor [id=2], meanOfPayment=MeanOfPayment [id=1], amount=-10400.00, createDate=2018-10-02 00:00:00.066]
ActorContent [id=3, actor=Actor [id=2], meanOfPayment=MeanOfPayment [id=3], amount=6000.00, createDate=2018-10-02 00:00:00.066]
ActorContent [id=4, actor=Actor [id=2], meanOfPayment=MeanOfPayment [id=2], amount=200.00, createDate=2018-09-30 00:00:00.066]
If you have an issue with having the same createDate for an Actor and MeanOfPayment combination then you can deal with in a few different ways. First if you have a logical constraint such that you don't want to process those duplicates then you should probably have a database constraint as well so you don't get them and ensure you don't create them in the first place. Another things is you can manually check the result list and remove them. Finally you can use a distinct in your query but you have to leave out the ActorContent id field since it will not be unique. You can do this with a DTO but JPA can't handle projection and join fetch at the same time so you will only be getting actor.id and meanOfPayment.id or you will be doing multiple selects. Multiple selects probably not a deal killer in this use case but you have to decide all that for yourself. Of course you could also make the primary key of ActorContent a combination of actor.id, meanOfPayment.id, and createDate and that would have the added benefit of being the constraint mentioned above.
These are the Entities I worked with.
@Entity
public class Actor {
@Id @GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id;
@Entity
public class MeanOfPayment {
@Id @GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id;
@Entity
public class ActorContent {
@Id @GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id;
@ManyToOne
private Actor actor;
@ManyToOne
private MeanOfPayment meanOfPayment;
private BigDecimal amount;
@Temporal(TemporalType.TIMESTAMP)
private Date createDate;