I'm trying to go seq2seq with a Transformer model. My input and output are the same shape (torch.Size([499, 128]) where 499 is the sequence length and 128 is the number of features.
My input looks like:
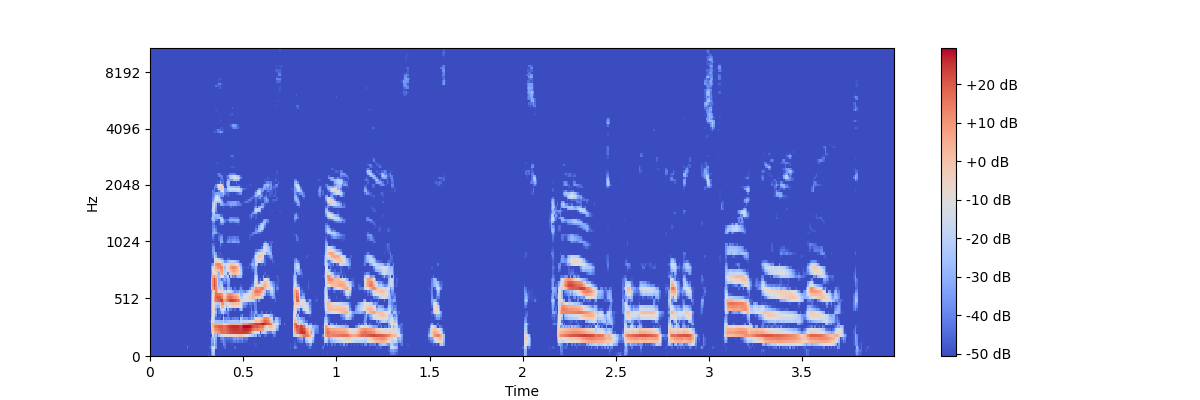
My output looks like:
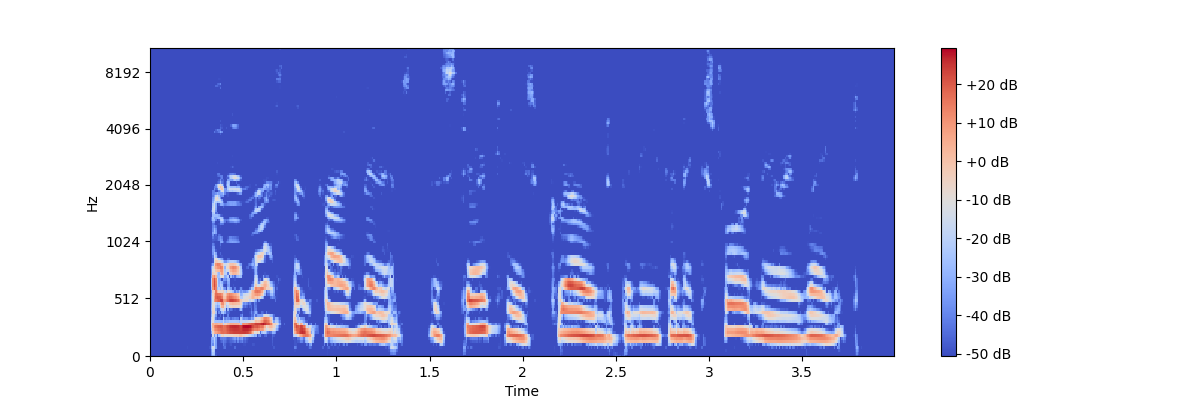
My training loop is:
for batch in tqdm(dataset):
optimizer.zero_grad()
x, y = batch
x = x.to(DEVICE)
y = y.to(DEVICE)
pred = model(x, torch.zeros(x.size()).to(DEVICE))
loss = loss_fn(pred, y)
loss.backward()
optimizer.step()
My model is:
import math
from typing import final
import torch
import torch.nn as nn
class Reconstructor(nn.Module):
def __init__(self, input_dim, output_dim, dim_embedding, num_layers=4, nhead=8, dim_feedforward=2048, dropout=0.5):
super(Reconstructor, self).__init__()
self.model_type = 'Transformer'
self.src_mask = None
self.pos_encoder = PositionalEncoding(d_model=dim_embedding, dropout=dropout)
self.transformer = nn.Transformer(d_model=dim_embedding, nhead=nhead, dim_feedforward=dim_feedforward, num_encoder_layers=num_layers, num_decoder_layers=num_layers)
self.decoder = nn.Linear(dim_embedding, output_dim)
self.decoder_act_fn = nn.PReLU()
self.init_weights()
def init_weights(self):
initrange = 0.1
nn.init.zeros_(self.decoder.weight)
nn.init.uniform_(self.decoder.weight, -initrange, initrange)
def forward(self, src, tgt):
pe_src = self.pos_encoder(src.permute(1, 0, 2)) # (seq, batch, features)
transformer_output = self.transformer_encoder(pe_src)
decoder_output = self.decoder(transformer_output.permute(1, 0, 2)).squeeze(2)
decoder_output = self.decoder_act_fn(decoder_output)
return decoder_output
My output has a shape of torch.Size([32, 499, 128]) where 32 is batch, 499 is my sequence length and 128 is the number of features. But the output has the same values:
tensor([[[0.0014, 0.0016, 0.0017, ..., 0.0018, 0.0021, 0.0017],
[0.0014, 0.0016, 0.0017, ..., 0.0018, 0.0021, 0.0017],
[0.0014, 0.0016, 0.0017, ..., 0.0018, 0.0021, 0.0017],
...,
[0.0014, 0.0016, 0.0017, ..., 0.0018, 0.0021, 0.0017],
[0.0014, 0.0016, 0.0017, ..., 0.0018, 0.0021, 0.0017],
[0.0014, 0.0016, 0.0017, ..., 0.0018, 0.0021, 0.0017]]],
grad_fn=<PreluBackward>)
What am I doing wrong? Thank you so much for any help.
self.transformer_encoder()is undefined. Do you meantransformer_output = self.transformer()(apparently unused)? – Victorious