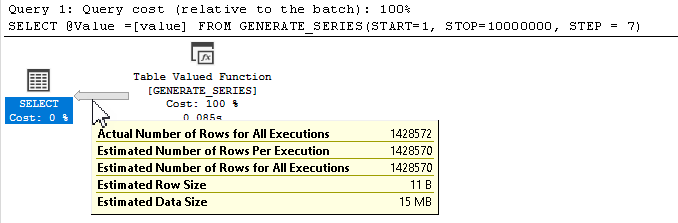
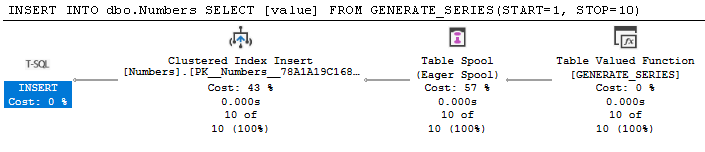
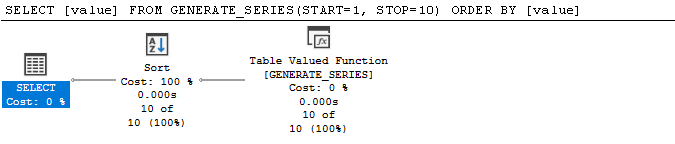
Heh... sorry I'm so late responding to an old post. And, yeah, I had to respond because the most popular answer (at the time, the Recursive CTE answer with the link to 14 different methods) on this thread is, ummm... performance challenged at best.
First, the article with the 14 different solutions is fine for seeing the different methods of creating a Numbers/Tally table on the fly but as pointed out in the article and in the cited thread, there's a very important quote...
"suggestions regarding efficiency and
performance are often subjective.
Regardless of how a query is being
used, the physical implementation
determines the efficiency of a query.
Therefore, rather than relying on
biased guidelines, it is imperative
that you test the query and determine
which one performs better."
Ironically, the article itself contains many subjective statements and "biased guidelines" such as "a recursive CTE can generate a number listing pretty efficiently" and "This is an efficient method of using WHILE loop from a newsgroup posting by Itzik Ben-Gen" (which I'm sure he posted just for comparison purposes). C'mon folks... Just mentioning Itzik's good name may lead some poor slob into actually using that horrible method. The author should practice what (s)he preaches and should do a little performance testing before making such ridiculously incorrect statements especially in the face of any scalablility.
With the thought of actually doing some testing before making any subjective claims about what any code does or what someone "likes", here's some code you can do your own testing with. Setup profiler for the SPID you're running the test from and check it out for yourself... just do a "Search'n'Replace" of the number 1000000 for your "favorite" number and see...
--===== Test for 1000000 rows ==================================
GO
--===== Traditional RECURSIVE CTE method
WITH Tally (N) AS
(
SELECT 1 UNION ALL
SELECT 1 + N FROM Tally WHERE N < 1000000
)
SELECT N
INTO #Tally1
FROM Tally
OPTION (MAXRECURSION 0);
GO
--===== Traditional WHILE LOOP method
CREATE TABLE #Tally2 (N INT);
SET NOCOUNT ON;
DECLARE @Index INT;
SET @Index = 1;
WHILE @Index <= 1000000
BEGIN
INSERT #Tally2 (N)
VALUES (@Index);
SET @Index = @Index + 1;
END;
GO
--===== Traditional CROSS JOIN table method
SELECT TOP (1000000)
ROW_NUMBER() OVER (ORDER BY (SELECT 1)) AS N
INTO #Tally3
FROM Master.sys.All_Columns ac1
CROSS JOIN Master.sys.ALL_Columns ac2;
GO
--===== Itzik's CROSS JOINED CTE method
WITH E00(N) AS (SELECT 1 UNION ALL SELECT 1),
E02(N) AS (SELECT 1 FROM E00 a, E00 b),
E04(N) AS (SELECT 1 FROM E02 a, E02 b),
E08(N) AS (SELECT 1 FROM E04 a, E04 b),
E16(N) AS (SELECT 1 FROM E08 a, E08 b),
E32(N) AS (SELECT 1 FROM E16 a, E16 b),
cteTally(N) AS (SELECT ROW_NUMBER() OVER (ORDER BY N) FROM E32)
SELECT N
INTO #Tally4
FROM cteTally
WHERE N <= 1000000;
GO
--===== Housekeeping
DROP TABLE #Tally1, #Tally2, #Tally3, #Tally4;
GO
While we're at it, here's the numbers I get from SQL Profiler for the values of 100, 1000, 10000, 100000, and 1000000...
SPID TextData Dur(ms) CPU Reads Writes
---- ---------------------------------------- ------- ----- ------- ------
51 --===== Test for 100 rows ============== 8 0 0 0
51 --===== Traditional RECURSIVE CTE method 16 0 868 0
51 --===== Traditional WHILE LOOP method CR 73 16 175 2
51 --===== Traditional CROSS JOIN table met 11 0 80 0
51 --===== Itzik's CROSS JOINED CTE method 6 0 63 0
51 --===== Housekeeping DROP TABLE #Tally 35 31 401 0
51 --===== Test for 1000 rows ============= 0 0 0 0
51 --===== Traditional RECURSIVE CTE method 47 47 8074 0
51 --===== Traditional WHILE LOOP method CR 80 78 1085 0
51 --===== Traditional CROSS JOIN table met 5 0 98 0
51 --===== Itzik's CROSS JOINED CTE method 2 0 83 0
51 --===== Housekeeping DROP TABLE #Tally 6 15 426 0
51 --===== Test for 10000 rows ============ 0 0 0 0
51 --===== Traditional RECURSIVE CTE method 434 344 80230 10
51 --===== Traditional WHILE LOOP method CR 671 563 10240 9
51 --===== Traditional CROSS JOIN table met 25 31 302 15
51 --===== Itzik's CROSS JOINED CTE method 24 0 192 15
51 --===== Housekeeping DROP TABLE #Tally 7 15 531 0
51 --===== Test for 100000 rows =========== 0 0 0 0
51 --===== Traditional RECURSIVE CTE method 4143 3813 800260 154
51 --===== Traditional WHILE LOOP method CR 5820 5547 101380 161
51 --===== Traditional CROSS JOIN table met 160 140 479 211
51 --===== Itzik's CROSS JOINED CTE method 153 141 276 204
51 --===== Housekeeping DROP TABLE #Tally 10 15 761 0
51 --===== Test for 1000000 rows ========== 0 0 0 0
51 --===== Traditional RECURSIVE CTE method 41349 37437 8001048 1601
51 --===== Traditional WHILE LOOP method CR 59138 56141 1012785 1682
51 --===== Traditional CROSS JOIN table met 1224 1219 2429 2101
51 --===== Itzik's CROSS JOINED CTE method 1448 1328 1217 2095
51 --===== Housekeeping DROP TABLE #Tally 8 0 415 0
As you can see, the Recursive CTE method is the second worst only to the While Loop for Duration and CPU and has 8 times the memory pressure in the form of logical reads than the While Loop. It's RBAR on steroids and should be avoided, at all cost, for any single row calculations just as a While Loop should be avoided. There are places where recursion is quite valuable but this ISN'T one of them.
As a side bar, Mr. Denny is absolutely spot on... a correctly sized permanent Numbers or Tally table is the way to go for most things. What does correctly sized mean? Well, most people use a Tally table to generate dates or to do splits on VARCHAR(8000). If you create an 11,000 row Tally table with the correct clustered index on "N", you'll have enough rows to create more than 30 years worth of dates (I work with mortgages a fair bit so 30 years is a key number for me) and certainly enough to handle a VARCHAR(8000) split. Why is "right sizing" so important? If the Tally table is used a lot, it easily fits in cache which makes it blazingly fast without much pressure on memory at all.
Last but not least, every one knows that if you create a permanent Tally table, it doesn't much matter which method you use to build it because 1) it's only going to be made once and 2) if it's something like an 11,000 row table, all of the methods are going to run "good enough". So why all the indigination on my part about which method to use???
The answer is that some poor guy/gal who doesn't know any better and just needs to get his or her job done might see something like the Recursive CTE method and decide to use it for something much larger and much more frequently used than building a permanent Tally table and I'm trying to protect those people, the servers their code runs on, and the company that owns the data on those servers. Yeah... it's that big a deal. It should be for everyone else, as well. Teach the right way to do things instead of "good enough". Do some testing before posting or using something from a post or book... the life you save may, in fact, be your own especially if you think a recursive CTE is the way to go for something like this. ;-)
Thanks for listening...