I have a 3 node SolrCloud setup (replication factor 3), running on Ubuntu 14.04 Solr 6.0 on SSDs. Much indexing taking place, only softCommits. After some time, indexing speed becomes really slow, but when i restart the solr service on the node that became slow, everything gets back to normal. Problem is that i need to guess which node becomes slow.
I have 5 collections, but only one collection (mostly used) is getting slow. Total data size is 144G including tlogs.
Said core/collection is 99G including tlogs, tlog is just 313M. Heap size is 16G, Total memory is 32G, data is stored on SSD. Every node is configured the same.
What appears to be strange is that i have literally hundreds or thousands of log lines per second on both slaves when this hits:
2016-09-16 10:00:30.476 INFO (qtp1190524793-46733) [c:mycollection s:shard1 r:core_node2 x:mycollection_shard1_replica1] o.a.s.u.p.LogUpdateProcessorFactory [mycollection_shard1_replica1] webapp=/solr path=/update params={update.distrib=FROMLEADER&update.chain=add-unknown-fields-to-the-schema&distrib.from=http://192.168.0.3:8983/solr/mycollection_shard1_replica3/&wt=javabin&version=2}{add=[ka2PZAqO_ (1545622027473256450)]} 0 0
2016-09-16 10:00:30.477 INFO (qtp1190524793-46767) [c:mycollection s:shard1 r:core_node2 x:mycollection_shard1_replica1] o.a.s.u.p.LogUpdateProcessorFactory [mycollection_shard1_replica1] webapp=/solr path=/update params={update.distrib=FROMLEADER&update.chain=add-unknown-fields-to-the-schema&distrib.from=http://192.168.0.3:8983/solr/mycollection_shard1_replica3/&wt=javabin&version=2}{add=[nlFpoYNt_ (1545622027474305024)]} 0 0
2016-09-16 10:00:30.477 INFO (qtp1190524793-46766) [c:mycollection s:shard1 r:core_node2 x:mycollection_shard1_replica1] o.a.s.u.p.LogUpdateProcessorFactory [mycollection_shard1_replica1] webapp=/solr path=/update params={update.distrib=FROMLEADER&update.chain=add-unknown-fields-to-the-schema&distrib.from=http://192.168.0.3:8983/solr/mycollection_shard1_replica3/&wt=javabin&version=2}{add=[tclMjXH6_ (1545622027474305025), 98OPJ3EJ_ (1545622027476402176)]} 0 0
2016-09-16 10:00:30.478 INFO (qtp1190524793-46668) [c:mycollection s:shard1 r:core_node2 x:mycollection_shard1_replica1] o.a.s.u.p.LogUpdateProcessorFactory [mycollection_shard1_replica1] webapp=/solr path=/update params={update.distrib=FROMLEADER&update.chain=add-unknown-fields-to-the-schema&distrib.from=http://192.168.0.3:8983/solr/mycollection_shard1_replica3/&wt=javabin&version=2}{add=[btceXK4M_ (1545622027475353600)]} 0 0
2016-09-16 10:00:30.479 INFO (qtp1190524793-46799) [c:mycollection s:shard1 r:core_node2 x:mycollection_shard1_replica1] o.a.s.u.p.LogUpdateProcessorFactory [mycollection_shard1_replica1] webapp=/solr path=/update params={update.distrib=FROMLEADER&update.chain=add-unknown-fields-to-the-schema&distrib.from=http://192.168.0.3:8983/solr/mycollection_shard1_replica3/&wt=javabin&version=2}{add=[3ndK3HzB_ (1545622027476402177), riCqrwPE_ (1545622027477450753)]} 0 1
2016-09-16 10:00:30.479 INFO (qtp1190524793-46820) [c:mycollection s:shard1 r:core_node2 x:mycollection_shard1_replica1] o.a.s.u.p.LogUpdateProcessorFactory [mycollection_shard1_replica1] webapp=/solr path=/update params={update.distrib=FROMLEADER&update.chain=add-unknown-fields-to-the-schema&distrib.from=http://192.168.0.3:8983/solr/mycollection_shard1_replica3/&wt=javabin&version=2}{add=[wr5k3mfk_ (1545622027477450752)]} 0 0
In this case 192.168.0.3 is the master.
My workflow is that i insert batches of 2500 docs with ~10 threads at the same time which works perfectly fine for most of the time but sometimes it becomes slow as described. Ocassionally there are updates / indexing calls from other sources, but it's less than a percent.
UPDATE
Complete config (output from Config API) is http://pastebin.com/GtUdGPLG
UPDATE 2
These are the command line args:
-DSTOP.KEY=solrrocks
-DSTOP.PORT=7983
-Dhost=192.168.0.1
-Djetty.home=/opt/solr/server
-Djetty.port=8983
-Dlog4j.configuration=file:/var/solr/log4j.properties
-Dsolr.install.dir=/opt/solr
-Dsolr.solr.home=/var/solr/data
-Duser.timezone=UTC
-DzkClientTimeout=15000
-DzkHost=192.168.0.1:2181,192.168.0.2:2181,192.168.0.3:2181
-XX:+CMSParallelRemarkEnabled
-XX:+CMSScavengeBeforeRemark
-XX:+ParallelRefProcEnabled
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintGCDateStamps
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintHeapAtGC
-XX:+PrintTenuringDistribution
-XX:+UseCMSInitiatingOccupancyOnly
-XX:+UseConcMarkSweepGC
-XX:+UseParNewGC
-XX:CMSInitiatingOccupancyFraction=50
-XX:CMSMaxAbortablePrecleanTime=6000
-XX:ConcGCThreads=4
-XX:MaxTenuringThreshold=8
-XX:NewRatio=3
-XX:OnOutOfMemoryError=/opt/solr/bin/oom_solr.sh 8983 /var/solr/logs
-XX:ParallelGCThreads=4
-XX:PretenureSizeThreshold=64m
-XX:SurvivorRatio=4
-XX:TargetSurvivorRatio=90-Xloggc:/var/solr/logs/solr_gc.log
-Xms16G
-Xmx16G
-Xss256k
-verbose:gc
UPDATE 3
Happened again, these are some Sematext Graphs:
Sematext Dashboard for Master:
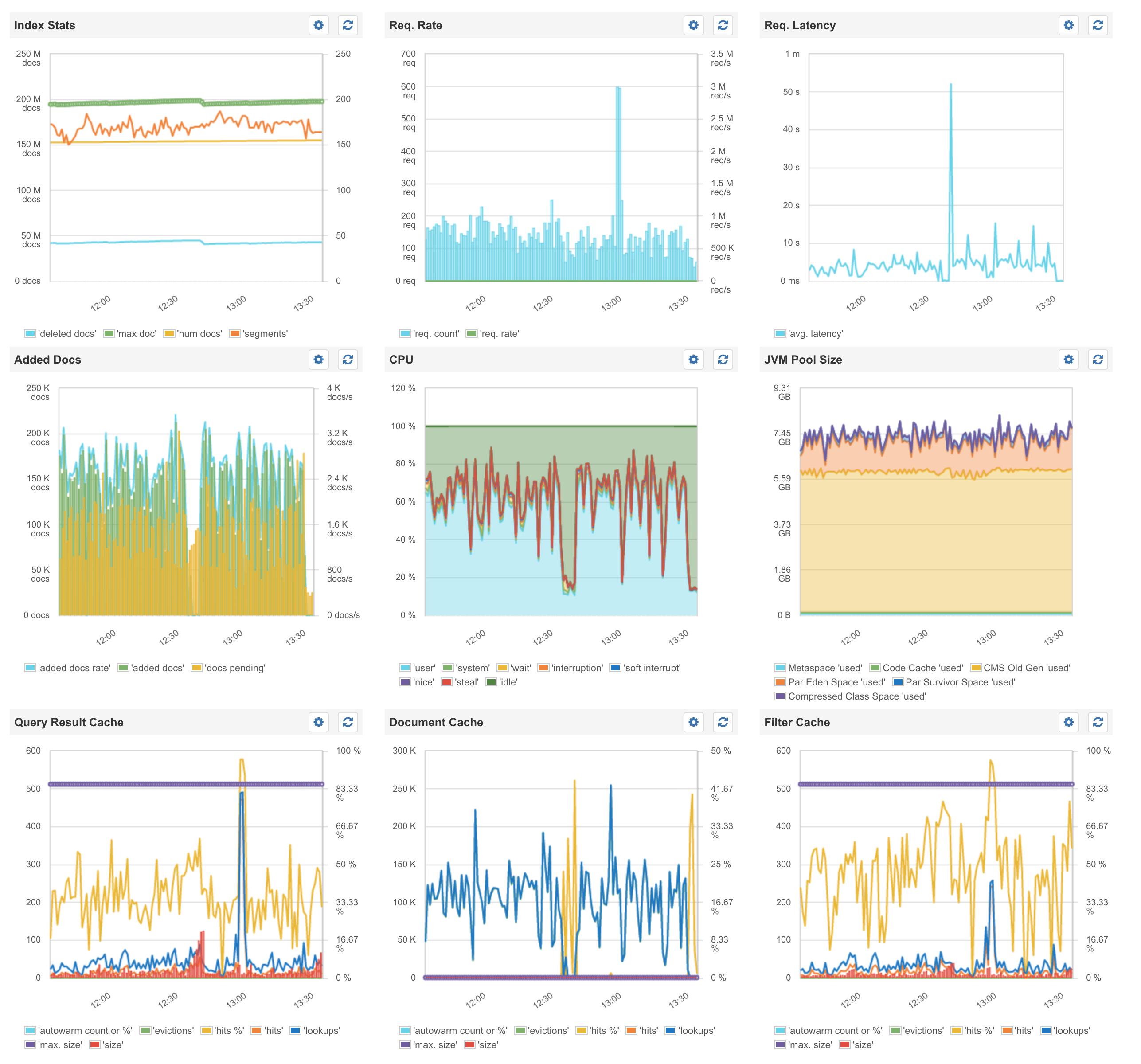
Sematext Dashboard for Secondary 1:
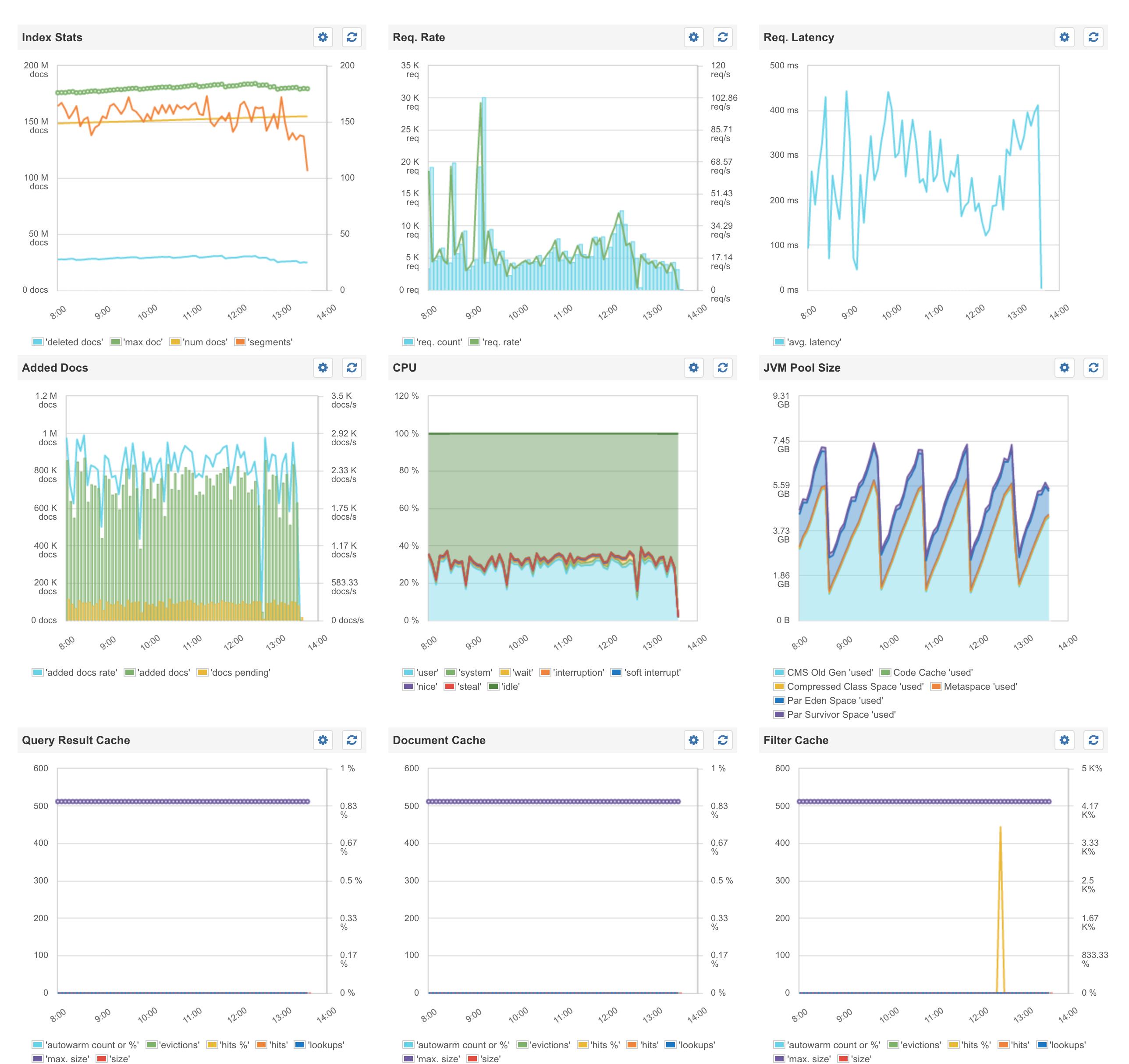
Sematext Dashboard for Secondary 2:
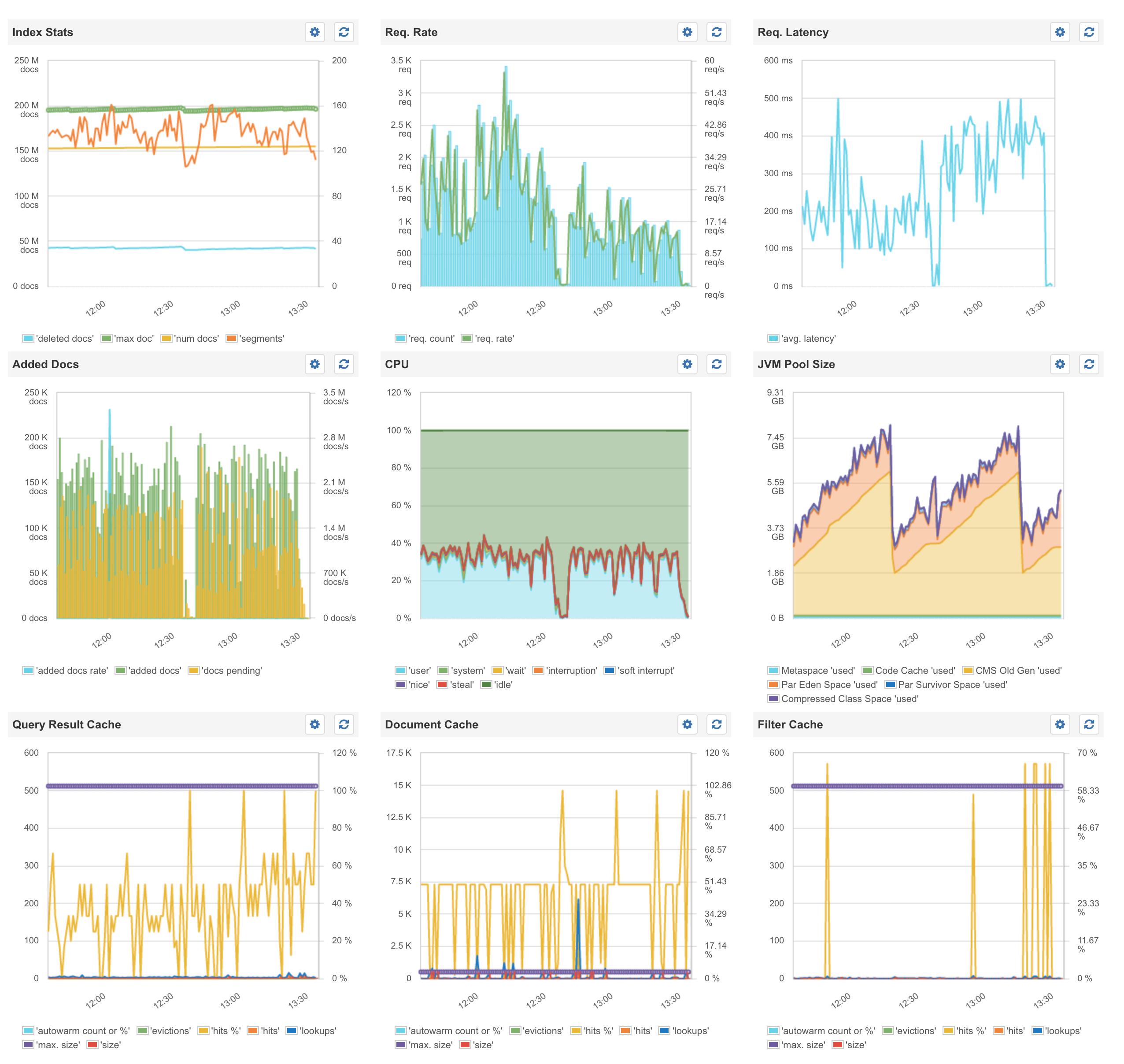
Sematext GC for Master:
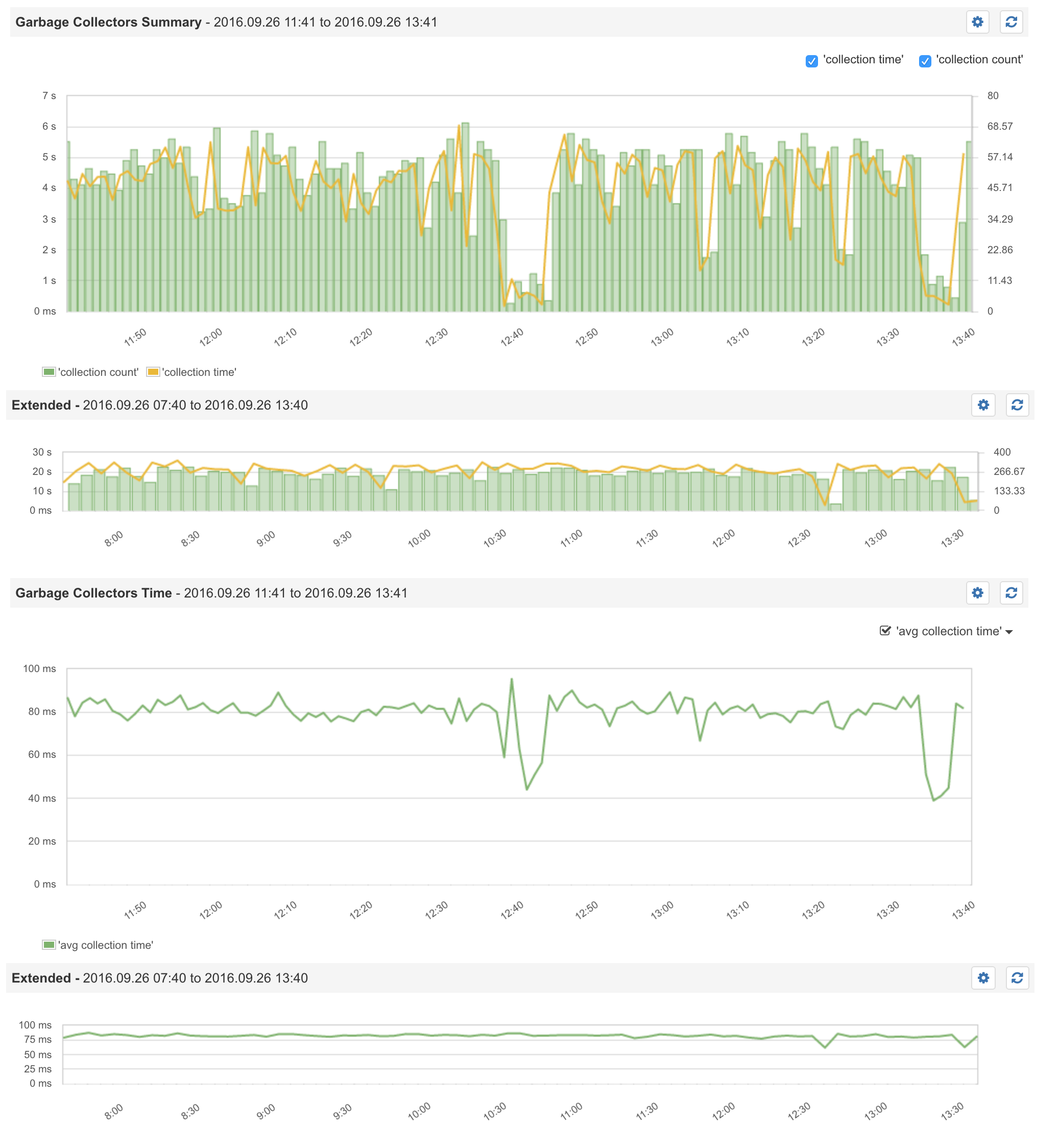
Sematext GC for Secondary 1:
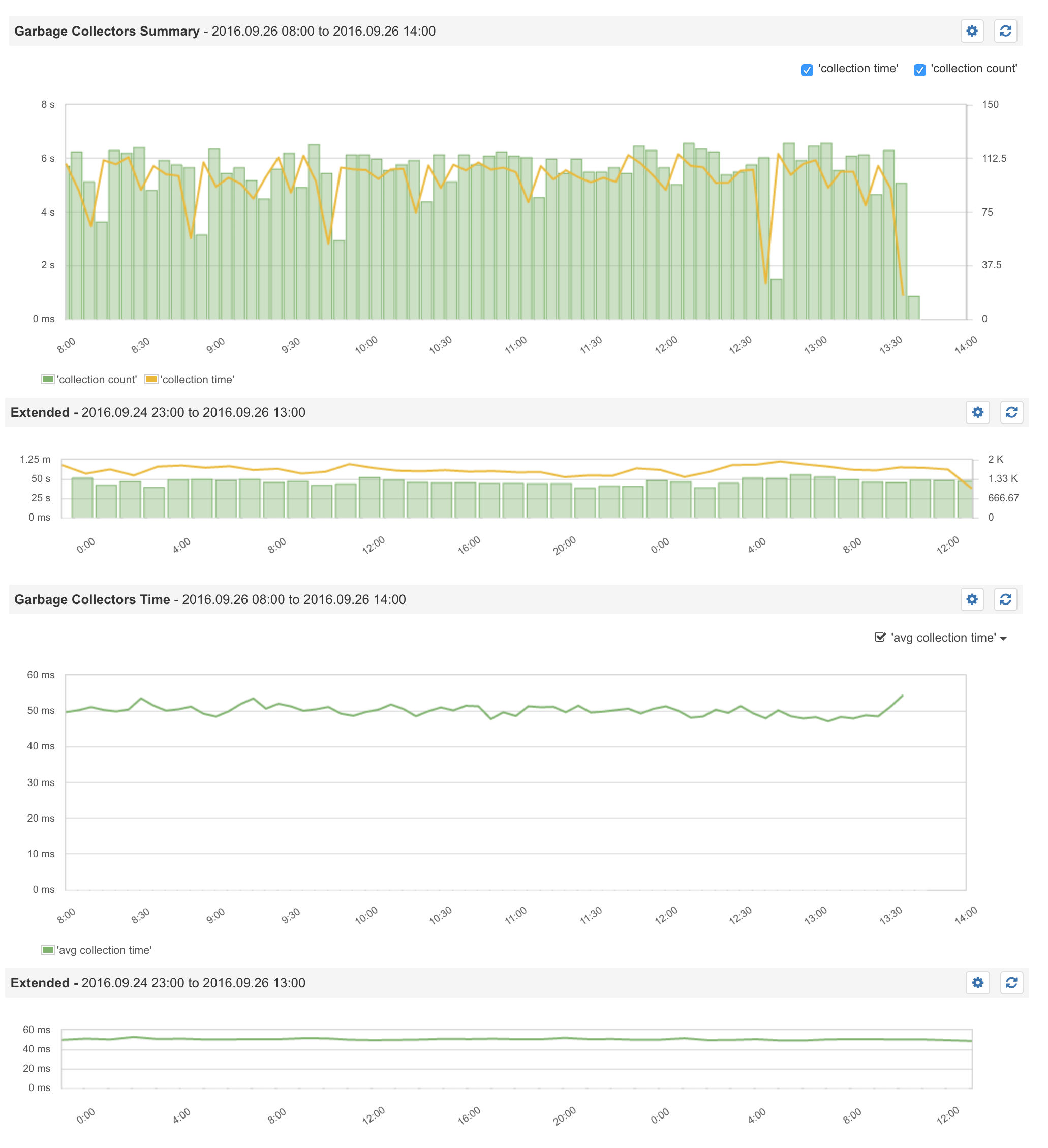
Sematext GC for Secondary 2:
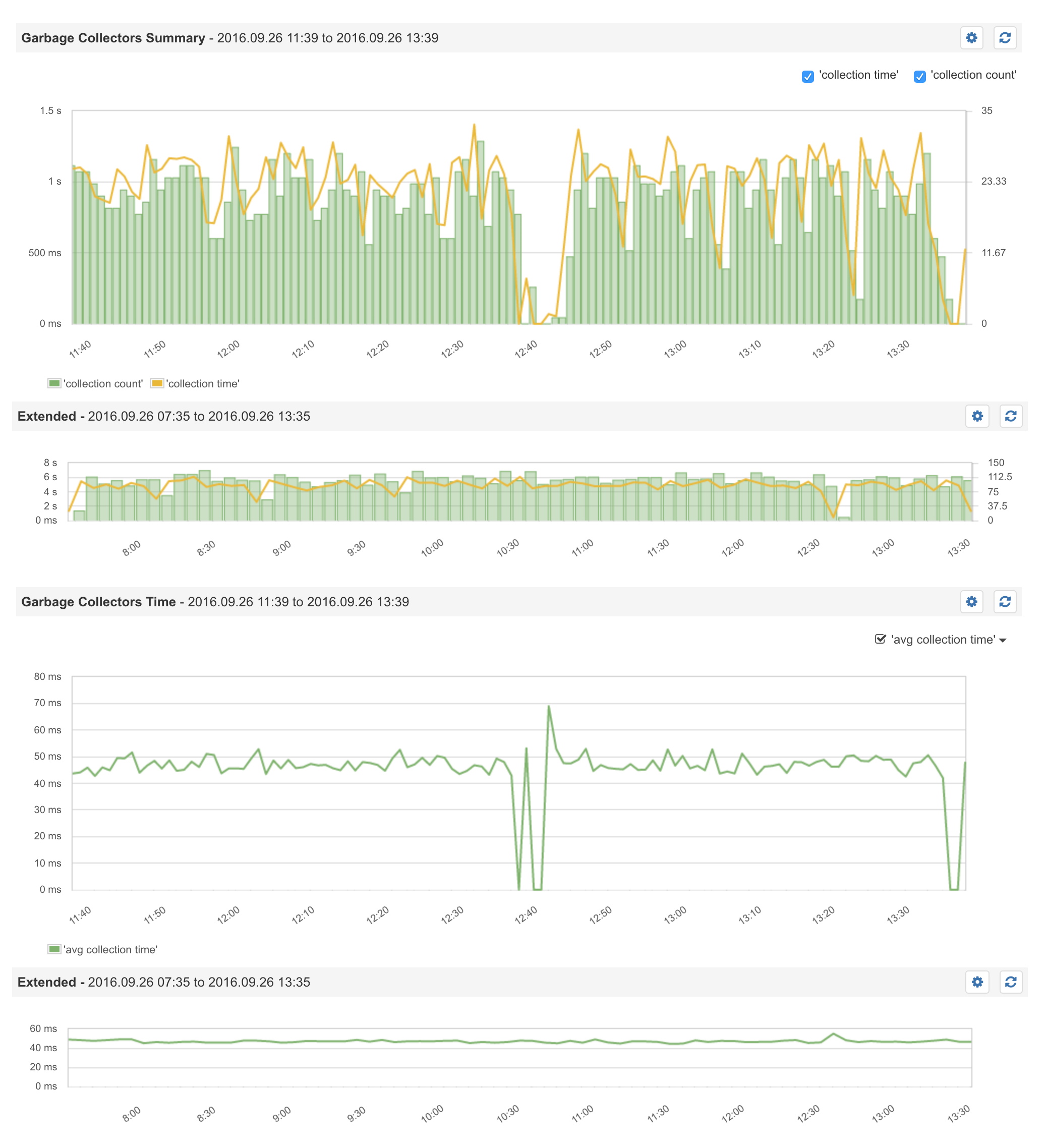
UPDATE 4 (2018-01-10)
This is a quite old question, but i recently discovered that someone installed a cryptocoin miner on all of my solr machines using CVE-2017-12629 which i fixed with an upgrade to 6.6.2.
If you're not sure if your system is infiltrated check the processes for user solr using ps aux | grep solr. If you see two or more processes, especially a non-java process, you might be running a miner.
topshows around2-4. GC Pauses have not been monitored yet, will do when this happens next time. – Molotovbin/solr bootstrap– Molotov32Gand no OutOfMemory errors. Heap Size is set to16Gmax, but at most10Gis used. GC isUseConcMarkSweepGC– Molotov