UPDATE :
Based on your updated question, I see why the file deletions occur. It seems like an unusual combination of circumstances to me. Most interesting point is that the revert of a merge is a more dangerous operation than it seemed to me at first glance. Undoing the merge (by resetting to clear it from history before it's been pushed) is the typical procedure and would avoid this kind of problem - if the problem had been caught prior to the push. But that's not much help here and now.
The clarifications notwithstanding, I still recommend against the history edit you propose and all of my advice relative to that edit is contained in my original answer. Keep in mind that if you rebase master in a way that edits commits from release, release will still have the original commits and you will have a weird, splintered history prone to conflicts on certain merge operations (because of duplicate commits doing the same things).
If you want to put all the changes from M1 back into the history, you can do that with fewer headaches by reverting W1. You still may get a handful of conflicts, but it's a much simpler procedure to begin with; doesn't create upstream rebase problems; and exposes you to fewer conflicted merges down the road.
It sounds like you're considering editing the history of the release branch. I recommend against it both for short-term reasons (the "upstream rebase" resoultion that will be required) and long-term reasons (the release branch would no longer document what was released). Of course I may have misunderstood what you're proposing, so let's get to a common starting point:
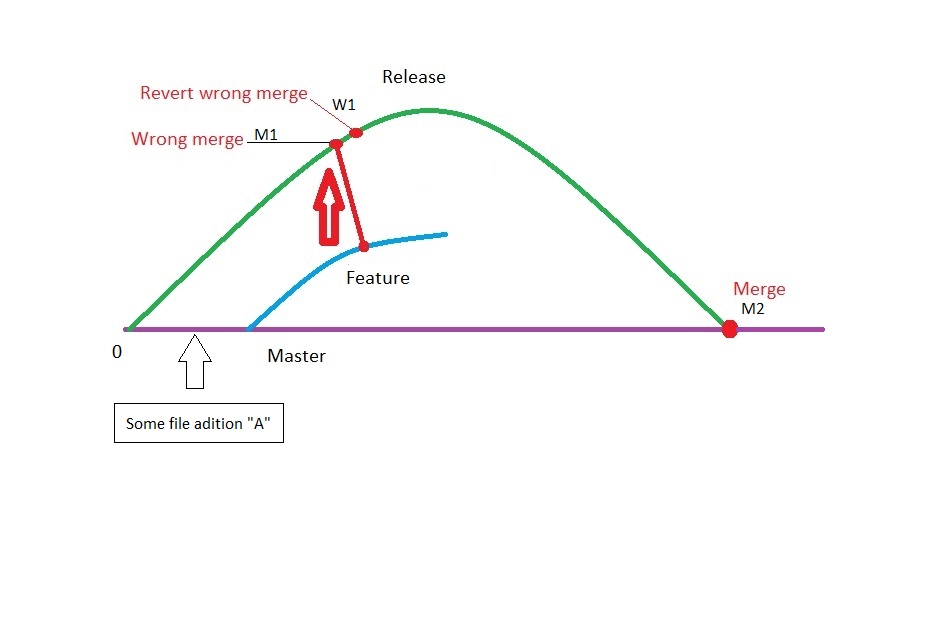
You currently have something like
O --- x --- x --- x --- M2 <--(master)
\ \ /
\ x --- M1 --- W1 <--(release)
\ /
A ----- B --- C --- D <--(feature)
where M1 was a mistaken merge of feature into release, W1 reverted M1, and M2 was the eventual merge of release into master.
As I understand it, all of that has been pushed, some of it is reflected in the history of your release version, and the "problem" commits are also already part of the shared history of master. So if it were me I'd consider nearly all of it "written in stone".
If you do ultimately decide to use rebase to "fix" the release branch, two things to consider:
1) It would be best to remove M1 and W1 from the release branch history, so that at least its resultant tree is a correct reflection of what you released. (I realize that eventually the work from M1 will be re-introduced, but that's not what you released.)
2) Having done that, you'd have to redo the M2 merge (creating M2') using the new release ref, and then rebase master, and anything else that has been branched from master since M2, to M2'. It can spiderweb quickly if this is an active repo.
And that's why I just wouldn't. So what else could you do?
It sounds like the release came out looking as it should, and so it's unclear to me why this would have any ill effects on master until you try to merge feature. After all, if removal of a file was done in W1 then that file must've been added (from perspective of release) by M1, so there would not normally be any net change when applying this to master. If master is messed up even though it doesn't contain feature, more info may be needed to understand why (and what to do about it).
(Or OTOH, if feature has already been merged to master at the time you started trying to merge release to master - which would explain why the merge looked like a mess - then that would require a different resolution that what I've suggested below.)
But if, as it sounds from the question, you haven't yet merged feature, then when you do try to merge feature to master, I would expect git to think A and B (which ultimately added the file) have already been applied through M1. (Subsequent changes in W1 then happen to undo it, but git doesn't much care.)
What I guess you need are new commits that do what A and B did. You can get that with relatively little headache by rebasing feature to M2 (or later on master). The problem is that if you tell rebase that master is your upstream, it will skip A and B (because those are reachable from master); so you have to force the upstream to be commit O.
So you could look up the SHA value for O, or put a tag on it (say feature-root) and then
git rebase --onto master feature-root feature
yielding
A' --- B' --- C' --- D' <--(feature)
/
O --- x --- x --- x --- M2 <--(master)
\ \ /
\ x --- M1 --- W1 <--(release)
\ /
A ----- B --- C --- D
So C and D don't matter (gc will eventually reclaim them), A and B (and M1) are left alone in history (avoiding the most problematic upstream rebases), and only users who are sharing the feature ref need to worry about upstream rebase recovery.