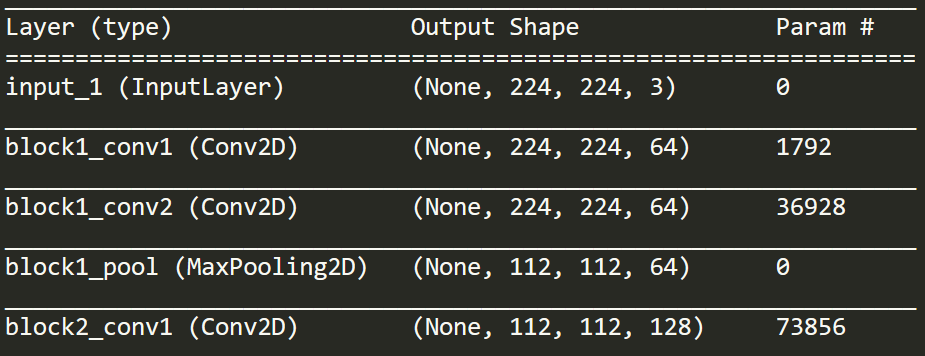
The "2D" part of a 2D convolution does not refer to the dimension of the convolution input, nor of dimension of the filter itself, but rather of the space in which the filter is allowed to move (2 directions only). Another way of thinking about this is that each of the RGB channels has its own 2D-array filter separately and the output is added at the end.
does the model run across the different channel/color representations separately from end to end?
Effectively it does this across each channel separately. For example, the first Conv2D layer takes in each of the 3 224x224 layers separately, and then applies different 2D-array filters to each one. But this isn't end-to-end across all model layers, only within the layer during the convolution step.
But, you might ask, there are 64 convolution filters for each channel, so why are there not 3*64 = 192 channels in the Conv2D output for the 3 channels? This prompts your question
Are the RGB channels combined (summed, or concatenated) at some point?
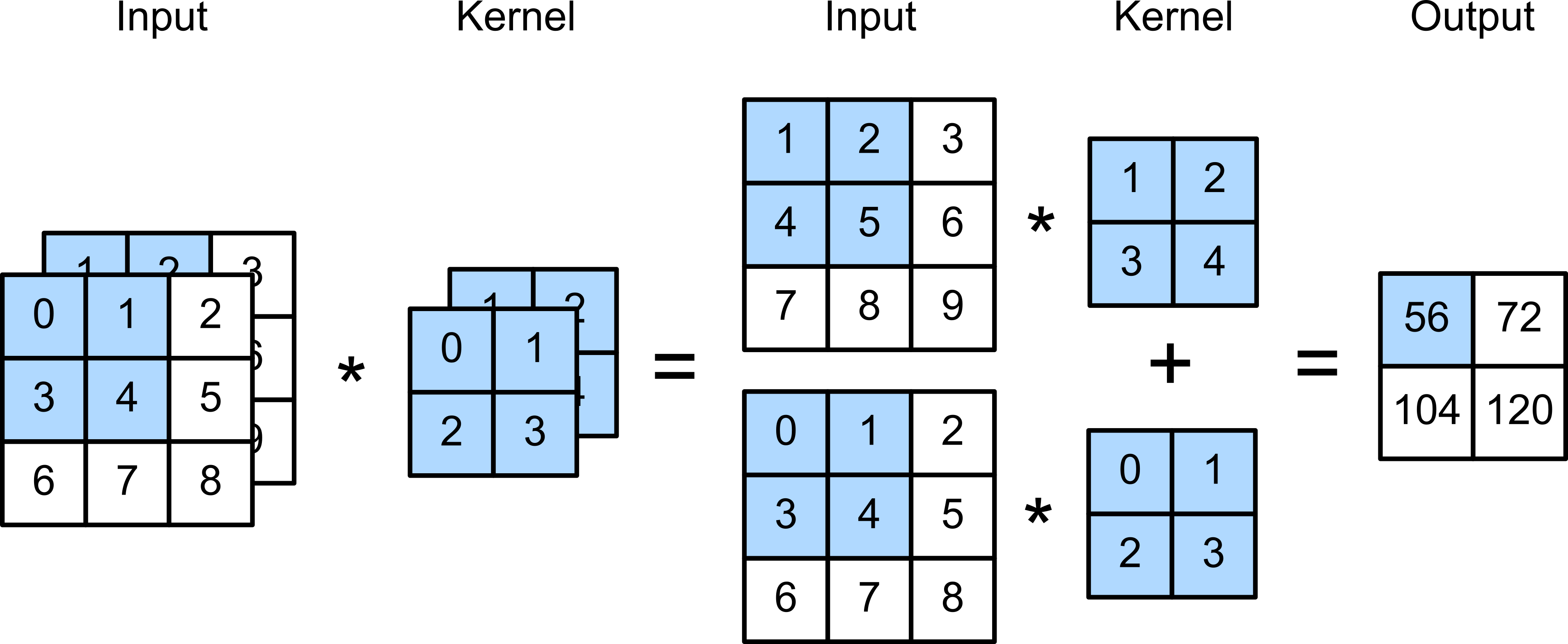
The answer is: yes. After the convolution filter is applied to each layer separately, the values for each of the three channels are added, and then a bias too if you've specified that. See the diagram below (from Dive Into Deep Learning, under CC BY-SA 4.0):
![Dive Into Deep Learning Diagram]()
The reason for this (that the separate channel layers are added) is that there aren't actually 3 separate 2D-array filters for each channel; technically there's just 1 3D-array filter which only moves in two directions. You could think of it a bit like a hamburger: there's one 2D-array filter for one channel (the bun), another for the next channel (the lettuce), etc. but all the layers are stacked up and function as a whole, so the filter weights are added all together at once. There's no need to add a special weight or filter for this, since the weights are already present during the convolution step (this would just be multiplying two fitting parameters together, which may as well be one).