Using the Fetch API I'm able to make a network request for a large asset of binary data (say more than 500 MB) and then convert the Response to either a Blob or an ArrayBuffer.
Afterwards, I can either do worker.postMessage and let the standard structured clone algorithm copy the Blob over to a Web Worker or transfer the ArrayBuffer over to the worker context (making effectively no longer available from the main thread).
At first, it would seem that it would be much preferable to fetch the data as an ArrayBuffer, since a Blob is not transferrable and thus, will need to be copied over. However, blobs are immutable and thus, it seems that the browser doesn't store it in the JS heap associated to the page, but rather in a dedicated blob storage space and thus, what's ended up being copied over to the worker context is just a reference.
I've prepared a demo to try out the difference between the two approaches: https://blobvsab.vercel.app/. I'm fetching 656 MB worth of binary data using both approaches.
Something interesting I've observed in my local tests, is that copying the Blob is even faster than transferring the ArrayBuffer:
Blob copy time from main thread to worker: 1.828125 ms
ArrayBuffer transfer time from main thread to worker: 3.393310546875 ms
This is a strong indicator that dealing with Blobs is actually pretty cheap. Since they're immutable, the browser seems to be smart enough to treat them as a reference rather than linking the overlying binary data to those references.
Here are the heap memory snapshots I've taken when fetching as a Blob:

The first two snapshots were taken after the resulting Blob of fetching was copied over the worker context using postMessage. Notice that neither of those heaps include the 656 MBs.
The latter two snapshots were taken after I've used a FileReader to actually access the underlying data, and as expected, the heap grew a lot.
Now, this is what happens with fetching directly as an ArrayBuffer:
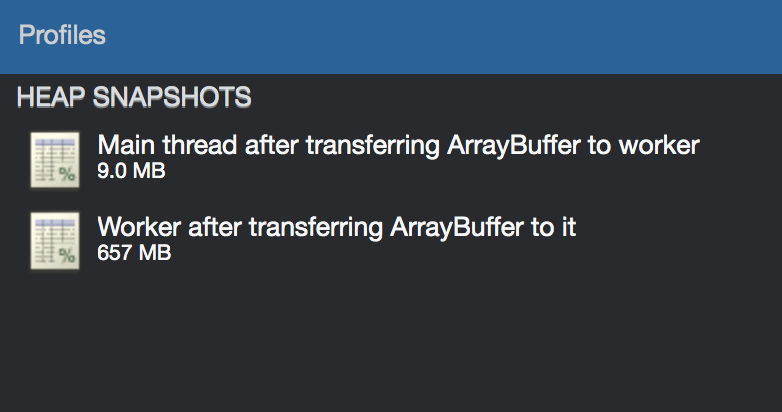
Here, since the binary data was simply transferred over the worker thread, the heap of the main thread is small but the worker heap contains the entirety of the 656 MBs, even before reading this data.
Now, looking around at SO I see that What is the difference between an ArrayBuffer and a Blob? mentions a lot of underlying differences between the two structures, but I haven't found a good reference regarding if one should be worried about copying over a Blob between execution contexts vs. what would seem an inherent advantage of ArrayBuffer that they're transferrable. However, my experiments show that copying the Blob might actually be faster and thus I think preferable.
It seems to be up to each browser vendor how they're storing and handling Blobs. I've found this Chromium documentation describing that all Blobs are transferred from each renderer process (i.e. a page on a tab) to the browser process and that way Chrome can even offload the Blob to the secondary memory if needed.
Does anyone have some more insights regarding all of this? If I can choose to fetch some large binary data over the network and move that to a Web Worker should I prefer a Blob or a ArrayBuffer?