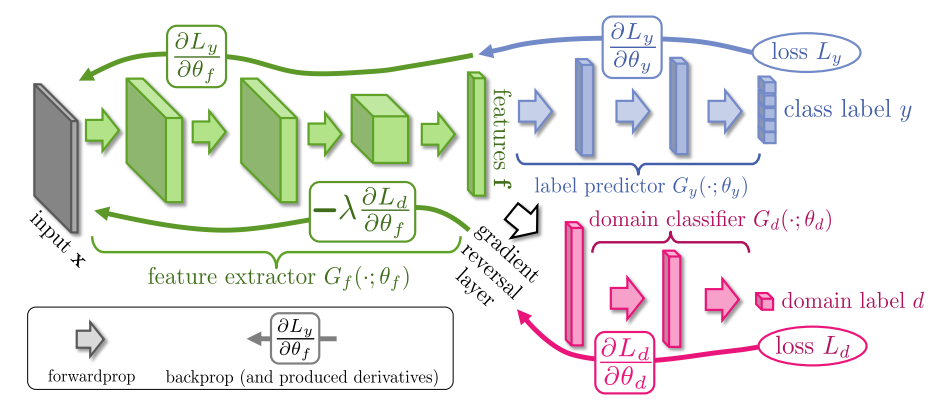
Here's a sketch implementation using plain Theano. This can be integrated into Lasagne easily enough.
You need to create a custom operation which acts as an identity operation in the forward pass but reverses the gradient in the backward pass.
Here's a suggestion for how that could be implemented. It is not tested and I'm not 100% certain I've understood everything correctly, but you may be able to verify and fix as required.
class ReverseGradient(theano.gof.Op):
view_map = {0: [0]}
__props__ = ('hp_lambda',)
def __init__(self, hp_lambda):
super(ReverseGradient, self).__init__()
self.hp_lambda = hp_lambda
def make_node(self, x):
return theano.gof.graph.Apply(self, [x], [x.type.make_variable()])
def perform(self, node, inputs, output_storage):
xin, = inputs
xout, = output_storage
xout[0] = xin
def grad(self, input, output_gradients):
return [-self.hp_lambda * output_gradients[0]]
Using the paper notation and naming conventions, here's a simple Theano implementation of the complete general model they propose.
import numpy
import theano
import theano.tensor as tt
def g_f(z, theta_f):
for w_f, b_f in theta_f:
z = tt.tanh(theano.dot(z, w_f) + b_f)
return z
def g_y(z, theta_y):
for w_y, b_y in theta_y[:-1]:
z = tt.tanh(theano.dot(z, w_y) + b_y)
w_y, b_y = theta_y[-1]
z = tt.nnet.softmax(theano.dot(z, w_y) + b_y)
return z
def g_d(z, theta_d):
for w_d, b_d in theta_d[:-1]:
z = tt.tanh(theano.dot(z, w_d) + b_d)
w_d, b_d = theta_d[-1]
z = tt.nnet.sigmoid(theano.dot(z, w_d) + b_d)
return z
def l_y(z, y):
return tt.nnet.categorical_crossentropy(z, y).mean()
def l_d(z, d):
return tt.nnet.binary_crossentropy(z, d).mean()
def mlp_parameters(input_size, layer_sizes):
parameters = []
previous_size = input_size
for layer_size in layer_sizes:
parameters.append((theano.shared(numpy.random.randn(previous_size, layer_size).astype(theano.config.floatX)),
theano.shared(numpy.zeros(layer_size, dtype=theano.config.floatX))))
previous_size = layer_size
return parameters, previous_size
def compile(input_size, f_layer_sizes, y_layer_sizes, d_layer_sizes, hp_lambda, hp_mu):
r = ReverseGradient(hp_lambda)
theta_f, f_size = mlp_parameters(input_size, f_layer_sizes)
theta_y, _ = mlp_parameters(f_size, y_layer_sizes)
theta_d, _ = mlp_parameters(f_size, d_layer_sizes)
xs = tt.matrix('xs')
xs.tag.test_value = numpy.random.randn(9, input_size).astype(theano.config.floatX)
xt = tt.matrix('xt')
xt.tag.test_value = numpy.random.randn(10, input_size).astype(theano.config.floatX)
ys = tt.ivector('ys')
ys.tag.test_value = numpy.random.randint(y_layer_sizes[-1], size=9).astype(numpy.int32)
fs = g_f(xs, theta_f)
e = l_y(g_y(fs, theta_y), ys) + l_d(g_d(r(fs), theta_d), 0) + l_d(g_d(r(g_f(xt, theta_f)), theta_d), 1)
updates = [(p, p - hp_mu * theano.grad(e, p)) for theta in theta_f + theta_y + theta_d for p in theta]
train = theano.function([xs, xt, ys], outputs=e, updates=updates)
return train
def main():
theano.config.compute_test_value = 'raise'
numpy.random.seed(1)
compile(input_size=2, f_layer_sizes=[3, 4], y_layer_sizes=[7, 8], d_layer_sizes=[5, 6], hp_lambda=.5, hp_mu=.01)
main()
This is untested but the following may allow this custom op to be used as a Lasagne layer:
class ReverseGradientLayer(lasagne.layers.Layer):
def __init__(self, incoming, hp_lambda, **kwargs):
super(ReverseGradientLayer, self).__init__(incoming, **kwargs)
self.op = ReverseGradient(hp_lambda)
def get_output_for(self, input, **kwargs):
return self.op(input)