I am trying to design an input pipeline with Dataset API. I am working with parquet files. What is a good way to add them to my pipeline?
Tensorflow Dataset API: input pipeline with parquet files
Asked Answered
We have released Petastorm, an open source library that allows you to use Apache Parquet files directly via Tensorflow Dataset API.
Here is a small example:
with Reader('hdfs://.../some/hdfs/path') as reader:
dataset = make_petastorm_dataset(reader)
iterator = dataset.make_one_shot_iterator()
tensor = iterator.get_next()
with tf.Session() as sess:
sample = sess.run(tensor)
print(sample.id)
Maybe a little late, but looks like this is available directly within Tensorflow now.
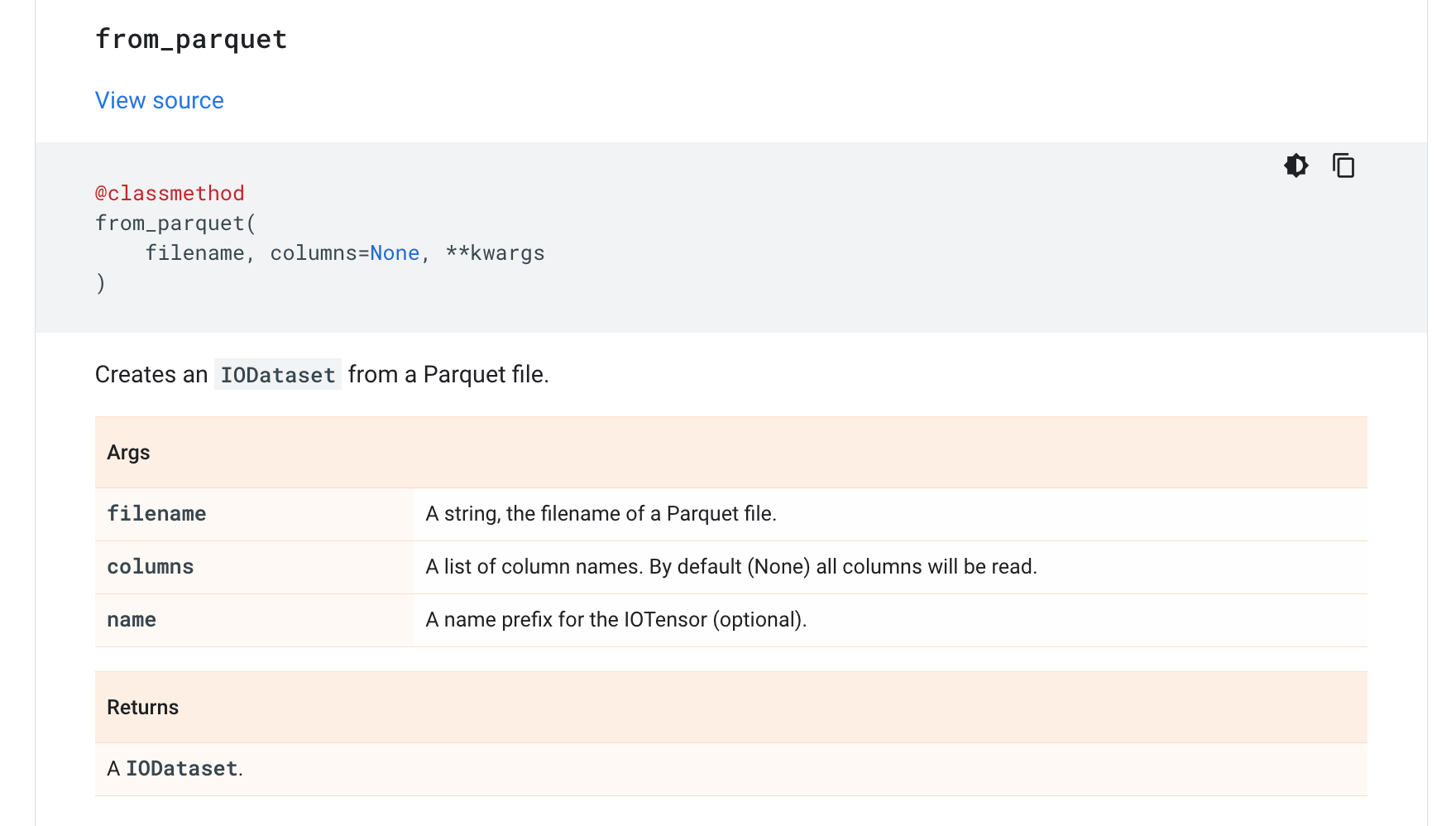
https://www.tensorflow.org/io/api_docs/python/tfio/experimental/IODataset#from_parquet
© 2022 - 2024 — McMap. All rights reserved.