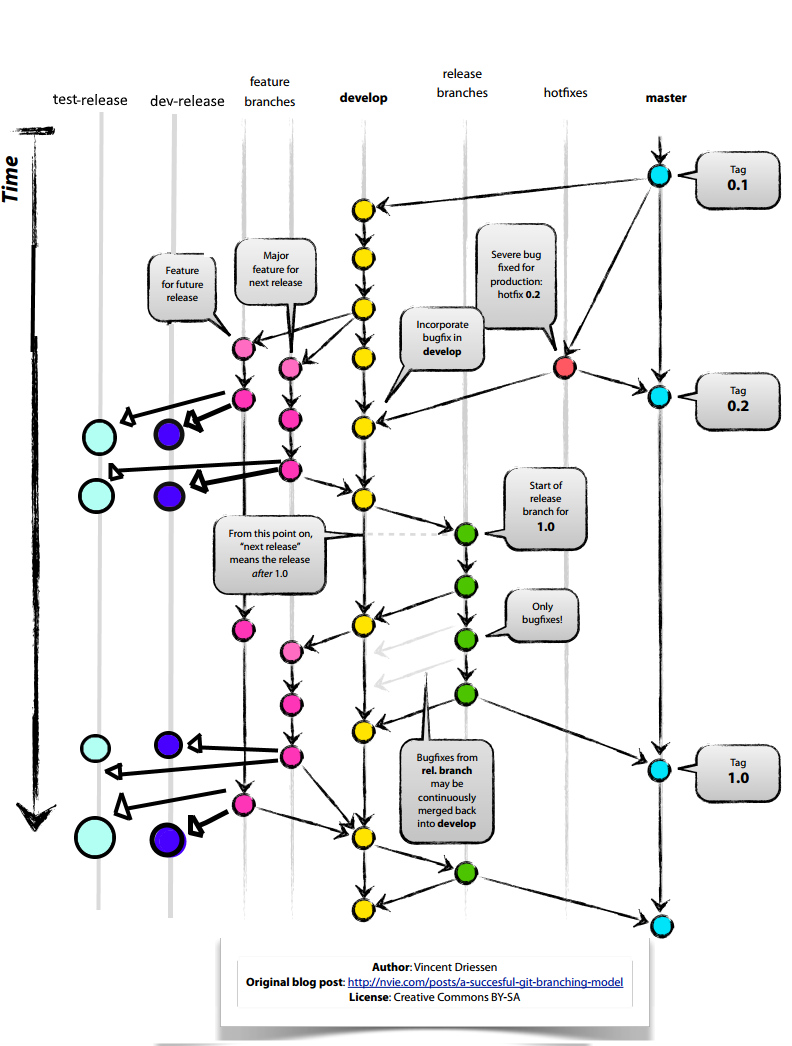
We are trying to follow the gitflow branching model, but with a twist.
We have have four servers environments where the product can be deployed to, each server serves a purpose : development, internal testing, external testing, and production.
- DevServer, where developers test their different features, while developing. Developers cannot test locally on their machines, they have to make their changes on the DevServer to be able to test
- TestServer, where QA testers test multiple features once developers are done
- ReleaseServer, where releases are tested in isolation before moving them to production
- ProductionServer. The production server
We are trying to make the merging / conflicts resolution as easy as possible, so we created two extra branches which is not part of the gitflow model.
Normal gitflow branches
- develop
- master (matches 'ProductionServer')
- featureXXX
- releaseXXX (weekly releases are deployed to 'ReleaseServer')
But also these two branches which is not standard and might need to change...
- dev-release (copy of DevServer)
- test-release (copy of TestServer)
Then process is then as follow:
- developer create their 'featureXXX' from 'develop'
- multiple developers merge their different 'features' into 'dev-release' branch, and 'dev-release' branch gets released to the 'DevServer' where all the developers can then test their different features. Not all these features will be in the same next release
- Once the developers are happy with their dev testing above, they merge their 'featureXXX' into branch 'test-release', and this gets deployed to 'TestServer'. Not all features here will be part of the same next release.
- Once testing on 'TestServer' is done for featureXXX, the developer can close their featureXXX into 'develop'.
- Developer then either create a new 'releaseXXX' or merge their 'featureXXX' into an existing 'releaseXXX'.
- The 'releaseXXX' branch is deployed to to 'ReleaseServer' and tested.
- Once 'releaseXXX' testing is signed off, 'releaseXXX' is merged into develop and master, and deployed to 'ProductionServer'
Are we messing up the whole gitflow model?
Here is our brancing process: