Here's a public link to an example html file. I would like to extract each set of CAN and yearly tax information (example highlighted in red in the image below) from the file and construct a dataframe that looks like the one below.
Target Fields
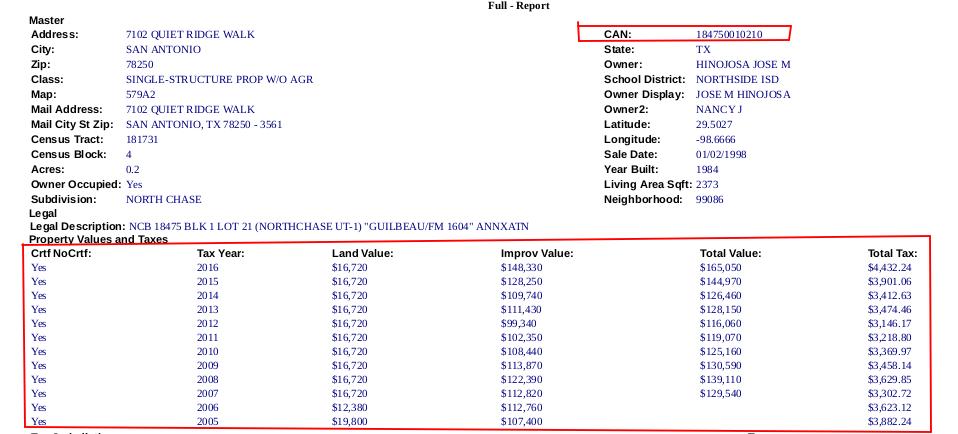
Example DataFrame
| Row | CAN | Crtf_NoCrtf | Tax_Year | Land_Value | Improv_Value | Total_Value | Total_Tax |
|-----+--------------+-------------+----------+------------+--------------+-------------+-----------|
| 1 | 184750010210 | Yes | 2016 | 16720 | 148330 | 165050 | 4432.24 |
| 2 | 184750010210 | Yes | 2015 | 16720 | 128250 | 144970 | 3901.06 |
| 3 | 184750010210 | Yes | 2014 | 16720 | 109740 | 126460 | 3412.63 |
| 4 | 184750010210 | Yes | 2013 | 16720 | 111430 | 128150 | 3474.46 |
| 5 | 184750010210 | Yes | 2012 | 16720 | 99340 | 116060 | 3146.17 |
| 6 | 184750010210 | Yes | 2011 | 16720 | 102350 | 119070 | 3218.80 |
| 7 | 184750010210 | Yes | 2010 | 16720 | 108440 | 125160 | 3369.97 |
| 8 | 184750010210 | Yes | 2009 | 16720 | 113870 | 130590 | 3458.14 |
| 9 | 184750010210 | Yes | 2008 | 16720 | 122390 | 139110 | 3629.85 |
| 10 | 184750010210 | Yes | 2007 | 16720 | 112820 | 129540 | 3302.72 |
| 11 | 184750010210 | Yes | 2006 | 12380 | 112760 | | 3623.12 |
| 12 | 184750010210 | Yes | 2005 | 19800 | 107400 | | 3882.24 |Additional Information
If it is not possible to insert the CAN to each row that is okay, I can export the CAN numbers separately and find a way to attach them to the dataframe containing the tax values. I have looked into using beautiful soup for python, but I am an absolute novice with python and the rest of the scripts I am writing are in Julia, so I would prefer to keep everything in one language.
Is there any way to achieve what I am trying to achieve? I have looked at Gumbo.jl but can not find any detailed documentation/tutorials.