Is there any way to determine a string's encoding in C#?
Say, I have a filename string, but I don't know if it is encoded in Unicode UTF-16 or the system-default encoding, how do I find out?
Is there any way to determine a string's encoding in C#?
Say, I have a filename string, but I don't know if it is encoded in Unicode UTF-16 or the system-default encoding, how do I find out?
The code below has the following features:
As others have said, no solution can be perfect (and certainly one can't easily differentiate between the various 8-bit extended ASCII encodings in use worldwide), but we can get 'good enough' especially if the developer also presents to the user a list of alternative encodings as shown here: What is the most common encoding of each language?
A full list of Encodings can be found using Encoding.GetEncodings();
// Function to detect the encoding for UTF-7, UTF-8/16/32 (bom, no bom, little
// & big endian), and local default codepage, and potentially other codepages.
// 'taster' = number of bytes to check of the file (to save processing). Higher
// value is slower, but more reliable (especially UTF-8 with special characters
// later on may appear to be ASCII initially). If taster = 0, then taster
// becomes the length of the file (for maximum reliability). 'text' is simply
// the string with the discovered encoding applied to the file.
public Encoding detectTextEncoding(string filename, out String text, int taster = 1000)
{
byte[] b = File.ReadAllBytes(filename);
//////////////// First check the low hanging fruit by checking if a
//////////////// BOM/signature exists (sourced from http://www.unicode.org/faq/utf_bom.html#bom4)
if (b.Length >= 4 && b[0] == 0x00 && b[1] == 0x00 && b[2] == 0xFE && b[3] == 0xFF) { text = Encoding.GetEncoding("utf-32BE").GetString(b, 4, b.Length - 4); return Encoding.GetEncoding("utf-32BE"); } // UTF-32, big-endian
else if (b.Length >= 4 && b[0] == 0xFF && b[1] == 0xFE && b[2] == 0x00 && b[3] == 0x00) { text = Encoding.UTF32.GetString(b, 4, b.Length - 4); return Encoding.UTF32; } // UTF-32, little-endian
else if (b.Length >= 2 && b[0] == 0xFE && b[1] == 0xFF) { text = Encoding.BigEndianUnicode.GetString(b, 2, b.Length - 2); return Encoding.BigEndianUnicode; } // UTF-16, big-endian
else if (b.Length >= 2 && b[0] == 0xFF && b[1] == 0xFE) { text = Encoding.Unicode.GetString(b, 2, b.Length - 2); return Encoding.Unicode; } // UTF-16, little-endian
else if (b.Length >= 3 && b[0] == 0xEF && b[1] == 0xBB && b[2] == 0xBF) { text = Encoding.UTF8.GetString(b, 3, b.Length - 3); return Encoding.UTF8; } // UTF-8
else if (b.Length >= 3 && b[0] == 0x2b && b[1] == 0x2f && b[2] == 0x76) { text = Encoding.UTF7.GetString(b,3,b.Length-3); return Encoding.UTF7; } // UTF-7
//////////// If the code reaches here, no BOM/signature was found, so now
//////////// we need to 'taste' the file to see if can manually discover
//////////// the encoding. A high taster value is desired for UTF-8
if (taster == 0 || taster > b.Length) taster = b.Length; // Taster size can't be bigger than the filesize obviously.
// Some text files are encoded in UTF8, but have no BOM/signature. Hence
// the below manually checks for a UTF8 pattern. This code is based off
// the top answer at: https://mcmap.net/q/11883/-check-for-invalid-utf8
// For our purposes, an unnecessarily strict (and terser/slower)
// implementation is shown at: https://mcmap.net/q/11884/-how-to-detect-utf-8-in-plain-c
// For the below, false positives should be exceedingly rare (and would
// be either slightly malformed UTF-8 (which would suit our purposes
// anyway) or 8-bit extended ASCII/UTF-16/32 at a vanishingly long shot).
int i = 0;
bool utf8 = false;
while (i < taster - 4)
{
if (b[i] <= 0x7F) { i += 1; continue; } // If all characters are below 0x80, then it is valid UTF8, but UTF8 is not 'required' (and therefore the text is more desirable to be treated as the default codepage of the computer). Hence, there's no "utf8 = true;" code unlike the next three checks.
if (b[i] >= 0xC2 && b[i] < 0xE0 && b[i + 1] >= 0x80 && b[i + 1] < 0xC0) { i += 2; utf8 = true; continue; }
if (b[i] >= 0xE0 && b[i] < 0xF0 && b[i + 1] >= 0x80 && b[i + 1] < 0xC0 && b[i + 2] >= 0x80 && b[i + 2] < 0xC0) { i += 3; utf8 = true; continue; }
if (b[i] >= 0xF0 && b[i] < 0xF5 && b[i + 1] >= 0x80 && b[i + 1] < 0xC0 && b[i + 2] >= 0x80 && b[i + 2] < 0xC0 && b[i + 3] >= 0x80 && b[i + 3] < 0xC0) { i += 4; utf8 = true; continue; }
utf8 = false; break;
}
if (utf8 == true) {
text = Encoding.UTF8.GetString(b);
return Encoding.UTF8;
}
// The next check is a heuristic attempt to detect UTF-16 without a BOM.
// We simply look for zeroes in odd or even byte places, and if a certain
// threshold is reached, the code is 'probably' UF-16.
double threshold = 0.1; // proportion of chars step 2 which must be zeroed to be diagnosed as utf-16. 0.1 = 10%
int count = 0;
for (int n = 0; n < taster; n += 2) if (b[n] == 0) count++;
if (((double)count) / taster > threshold) { text = Encoding.BigEndianUnicode.GetString(b); return Encoding.BigEndianUnicode; }
count = 0;
for (int n = 1; n < taster; n += 2) if (b[n] == 0) count++;
if (((double)count) / taster > threshold) { text = Encoding.Unicode.GetString(b); return Encoding.Unicode; } // (little-endian)
// Finally, a long shot - let's see if we can find "charset=xyz" or
// "encoding=xyz" to identify the encoding:
for (int n = 0; n < taster-9; n++)
{
if (
((b[n + 0] == 'c' || b[n + 0] == 'C') && (b[n + 1] == 'h' || b[n + 1] == 'H') && (b[n + 2] == 'a' || b[n + 2] == 'A') && (b[n + 3] == 'r' || b[n + 3] == 'R') && (b[n + 4] == 's' || b[n + 4] == 'S') && (b[n + 5] == 'e' || b[n + 5] == 'E') && (b[n + 6] == 't' || b[n + 6] == 'T') && (b[n + 7] == '=')) ||
((b[n + 0] == 'e' || b[n + 0] == 'E') && (b[n + 1] == 'n' || b[n + 1] == 'N') && (b[n + 2] == 'c' || b[n + 2] == 'C') && (b[n + 3] == 'o' || b[n + 3] == 'O') && (b[n + 4] == 'd' || b[n + 4] == 'D') && (b[n + 5] == 'i' || b[n + 5] == 'I') && (b[n + 6] == 'n' || b[n + 6] == 'N') && (b[n + 7] == 'g' || b[n + 7] == 'G') && (b[n + 8] == '='))
)
{
if (b[n + 0] == 'c' || b[n + 0] == 'C') n += 8; else n += 9;
if (b[n] == '"' || b[n] == '\'') n++;
int oldn = n;
while (n < taster && (b[n] == '_' || b[n] == '-' || (b[n] >= '0' && b[n] <= '9') || (b[n] >= 'a' && b[n] <= 'z') || (b[n] >= 'A' && b[n] <= 'Z')))
{ n++; }
byte[] nb = new byte[n-oldn];
Array.Copy(b, oldn, nb, 0, n-oldn);
try {
string internalEnc = Encoding.ASCII.GetString(nb);
text = Encoding.GetEncoding(internalEnc).GetString(b);
return Encoding.GetEncoding(internalEnc);
}
catch { break; } // If C# doesn't recognize the name of the encoding, break.
}
}
// If all else fails, the encoding is probably (though certainly not
// definitely) the user's local codepage! One might present to the user a
// list of alternative encodings as shown here: https://mcmap.net/q/11882/-what-is-the-most-common-encoding-of-each-language
// A full list can be found using Encoding.GetEncodings();
text = Encoding.Default.GetString(b);
return Encoding.Default;
}
<= 0xF0 to < 0xF0. For consistency, even though the code is correct, I have also changed <= 0xDF to < 0xE0 just above, and also <= 0xF4 to < 0xF5 just below. –
Hyacinthe It depends where the string 'came from'. A .NET string is Unicode (UTF-16). The only way it could be different if you, say, read the data from a database into a byte array.
This CodeProject article might be of interest: Detect Encoding for in- and outgoing text
Jon Skeet's Strings in C# and .NET is an excellent explanation of .NET strings.
I know this is a bit late - but to be clear:
A string doesn't really have encoding... in .NET the a string is a collection of char objects. Essentially, if it is a string, it has already been decoded.
However if you are reading the contents of a file, which is made of bytes, and wish to convert that to a string, then the file's encoding must be used.
.NET includes encoding and decoding classes for: ASCII, UTF7, UTF8, UTF32 and more.
Most of these encodings contain certain byte-order marks that can be used to distinguish which encoding type was used.
The .NET class System.IO.StreamReader is able to determine the encoding used within a stream, by reading those byte-order marks;
Here is an example:
/// <summary>
/// return the detected encoding and the contents of the file.
/// </summary>
/// <param name="fileName"></param>
/// <param name="contents"></param>
/// <returns></returns>
public static Encoding DetectEncoding(String fileName, out String contents)
{
// open the file with the stream-reader:
using (StreamReader reader = new StreamReader(fileName, true))
{
// read the contents of the file into a string
contents = reader.ReadToEnd();
// return the encoding.
return reader.CurrentEncoding;
}
}
Encoding.Default as a StreamReader parameter, but then the code won't detect UTF8 without the BOM. –
Hyacinthe Another option, very late in coming, sorry:
http://www.architectshack.com/TextFileEncodingDetector.ashx
This small C#-only class uses BOMS if present, tries to auto-detect possible unicode encodings otherwise, and falls back if none of the Unicode encodings is possible or likely.
It sounds like UTF8Checker referenced above does something similar, but I think this is slightly broader in scope - instead of just UTF8, it also checks for other possible Unicode encodings (UTF-16 LE or BE) that might be missing a BOM.
Hope this helps someone!
The SimpleHelpers.FileEncoding Nuget package wraps a C# port of the Mozilla Universal Charset Detector into a dead-simple API:
var encoding = FileEncoding.DetectFileEncoding(txtFile);
My solution is to use built-in stuffs with some fallbacks.
I picked the strategy from an answer to another similar question on stackoverflow but I can't find it now.
It checks the BOM first using the built-in logic in StreamReader, if there's BOM, the encoding will be something other than Encoding.Default, and we should trust that result.
If not, it checks whether the bytes sequence is valid UTF-8 sequence. if it is, it will guess UTF-8 as the encoding, and if not, again, the default ASCII encoding will be the result.
static Encoding getEncoding(string path) {
var stream = new FileStream(path, FileMode.Open);
var reader = new StreamReader(stream, Encoding.Default, true);
reader.Read();
if (reader.CurrentEncoding != Encoding.Default) {
reader.Close();
return reader.CurrentEncoding;
}
stream.Position = 0;
reader = new StreamReader(stream, new UTF8Encoding(false, true));
try {
reader.ReadToEnd();
reader.Close();
return Encoding.UTF8;
}
catch (Exception) {
reader.Close();
return Encoding.Default;
}
}
Note: this was an experiment to see how UTF-8 encoding worked internally. The solution offered by vilicvane, to use a UTF8Encoding object that is initialised to throw an exception on decoding failure, is much simpler, and basically does the same thing.
I wrote this piece of code to differentiate between UTF-8 and Windows-1252. It shouldn't be used for gigantic text files though, since it loads the entire thing into memory and scans it completely. I used it for .srt subtitle files, just to be able to save them back in the encoding in which they were loaded.
The encoding given to the function as ref should be the 8-bit fallback encoding to use in case the file is detected as not being valid UTF-8; generally, on Windows systems, this will be Windows-1252. This doesn't do anything fancy like checking actual valid ascii ranges though, and doesn't detect UTF-16 even on byte order mark.
The theory behind the bitwise detection can be found here: https://ianthehenry.com/2015/1/17/decoding-utf-8/
Basically, the bit range of the first byte determines how many after it are part of the UTF-8 entity. These bytes after it are always in the same bit range.
/// <summary>
/// Reads a text file, and detects whether its encoding is valid UTF-8 or ascii.
/// If not, decodes the text using the given fallback encoding.
/// Bit-wise mechanism for detecting valid UTF-8 based on
/// https://ianthehenry.com/2015/1/17/decoding-utf-8/
/// </summary>
/// <param name="docBytes">The bytes read from the file.</param>
/// <param name="encoding">The default encoding to use as fallback if the text is detected not to be pure ascii or UTF-8 compliant. This ref parameter is changed to the detected encoding.</param>
/// <returns>The contents of the read file, as String.</returns>
public static String ReadFileAndGetEncoding(Byte[] docBytes, ref Encoding encoding)
{
if (encoding == null)
encoding = Encoding.GetEncoding(1252);
Int32 len = docBytes.Length;
// byte order mark for utf-8. Easiest way of detecting encoding.
if (len > 3 && docBytes[0] == 0xEF && docBytes[1] == 0xBB && docBytes[2] == 0xBF)
{
encoding = new UTF8Encoding(true);
// Note that even when initialising an encoding to have
// a BOM, it does not cut it off the front of the input.
return encoding.GetString(docBytes, 3, len - 3);
}
Boolean isPureAscii = true;
Boolean isUtf8Valid = true;
for (Int32 i = 0; i < len; ++i)
{
Int32 skip = TestUtf8(docBytes, i);
if (skip == 0)
continue;
if (isPureAscii)
isPureAscii = false;
if (skip < 0)
{
isUtf8Valid = false;
// if invalid utf8 is detected, there's no sense in going on.
break;
}
i += skip;
}
if (isPureAscii)
encoding = new ASCIIEncoding(); // pure 7-bit ascii.
else if (isUtf8Valid)
encoding = new UTF8Encoding(false);
// else, retain given encoding. This should be an 8-bit encoding like Windows-1252.
return encoding.GetString(docBytes);
}
/// <summary>
/// Tests if the bytes following the given offset are UTF-8 valid, and
/// returns the amount of bytes to skip ahead to do the next read if it is.
/// If the text is not UTF-8 valid it returns -1.
/// </summary>
/// <param name="binFile">Byte array to test</param>
/// <param name="offset">Offset in the byte array to test.</param>
/// <returns>The amount of bytes to skip ahead for the next read, or -1 if the byte sequence wasn't valid UTF-8</returns>
public static Int32 TestUtf8(Byte[] binFile, Int32 offset)
{
// 7 bytes (so 6 added bytes) is the maximum the UTF-8 design could support,
// but in reality it only goes up to 3, meaning the full amount is 4.
const Int32 maxUtf8Length = 4;
Byte current = binFile[offset];
if ((current & 0x80) == 0)
return 0; // valid 7-bit ascii. Added length is 0 bytes.
Int32 len = binFile.Length;
for (Int32 addedlength = 1; addedlength < maxUtf8Length; ++addedlength)
{
Int32 fullmask = 0x80;
Int32 testmask = 0;
// This code adds shifted bits to get the desired full mask.
// If the full mask is [111]0 0000, then test mask will be [110]0 0000. Since this is
// effectively always the previous step in the iteration I just store it each time.
for (Int32 i = 0; i <= addedlength; ++i)
{
testmask = fullmask;
fullmask += (0x80 >> (i+1));
}
// figure out bit masks from level
if ((current & fullmask) == testmask)
{
if (offset + addedlength >= len)
return -1;
// Lookahead. Pattern of any following bytes is always 10xxxxxx
for (Int32 i = 1; i <= addedlength; ++i)
{
if ((binFile[offset + i] & 0xC0) != 0x80)
return -1;
}
return addedlength;
}
}
// Value is greater than the maximum allowed for utf8. Deemed invalid.
return -1;
}
else statement after if ((current & 0xE0) == 0xC0) { ... } else if ((current & 0xF0) == 0xE0) { ... } else if ((current & 0xF0) == 0xE0) { ... } else if ((current & 0xF8) == 0xF0) { ... }. I suppose that else case would be invalid utf8: isUtf8Valid = false;. Would you? –
Uncial My finally working approach is to try potential candidates of expected encodings by detecting invalid characters in the strings created from the byte array by the encodings. If I don't encounter invalid characters, I suppose the tested encoding works fine for the tested data.
For me, having only Latin and German special characters to consider, in order to determine the proper encoding for a byte array, I try to detect invalid characters in a string with this method:
/// <summary>
/// detect invalid characters in string, use to detect improper encoding
/// </summary>
/// <param name="s"></param>
/// <returns></returns>
public static bool DetectInvalidChars(string s)
{
const string specialChars = "\r\n\t .,;:-_!\"'?()[]{}&%$§=*+~#@|<>äöüÄÖÜß/\\^€";
return s.Any(ch => !(
specialChars.Contains(ch) ||
(ch >= '0' && ch <= '9') ||
(ch >= 'a' && ch <= 'z') ||
(ch >= 'A' && ch <= 'Z')));
}
(NB: if you have other Latin-based languages to consider, you might want to adapt the specialChars const string in the code)
Then I use it like this (I only expect UTF-8 or Default encoding):
// determine encoding by detecting invalid characters in string
var invoiceXmlText = Encoding.UTF8.GetString(invoiceXmlBytes); // try utf-8 first
if (StringFuncs.DetectInvalidChars(invoiceXmlText))
invoiceXmlText = Encoding.Default.GetString(invoiceXmlBytes); // fallback to default
I found new library on GitHub: CharsetDetector/UTF-unknown
Charset detector build in C# - .NET Core 2-3, .NET standard 1-2 & .NET 4+
it's also a port of the Mozilla Universal Charset Detector based on other repositories.
CharsetDetector/UTF-unknown have a class named CharsetDetector.
CharsetDetector contains some static encoding detect methods:
CharsetDetector.DetectFromFile()CharsetDetector.DetectFromStream()CharsetDetector.DetectFromBytes()detected result is in class DetectionResult has attribute Detected which is instance of class DetectionDetail with below attributes:
EncodingNameEncodingConfidencebelow is an example to show usage:
// Program.cs
using System;
using System.Text;
using UtfUnknown;
namespace ConsoleExample
{
public class Program
{
public static void Main(string[] args)
{
string filename = @"E:\new-file.txt";
DetectDemo(filename);
}
/// <summary>
/// Command line example: detect the encoding of the given file.
/// </summary>
/// <param name="filename">a filename</param>
public static void DetectDemo(string filename)
{
// Detect from File
DetectionResult result = CharsetDetector.DetectFromFile(filename);
// Get the best Detection
DetectionDetail resultDetected = result.Detected;
// detected result may be null.
if (resultDetected != null)
{
// Get the alias of the found encoding
string encodingName = resultDetected.EncodingName;
// Get the System.Text.Encoding of the found encoding (can be null if not available)
Encoding encoding = resultDetected.Encoding;
// Get the confidence of the found encoding (between 0 and 1)
float confidence = resultDetected.Confidence;
if (encoding != null)
{
Console.WriteLine($"Detection completed: {filename}");
Console.WriteLine($"EncodingWebName: {encoding.WebName}{Environment.NewLine}Confidence: {confidence}");
}
else
{
Console.WriteLine($"Detection completed: {filename}");
Console.WriteLine($"(Encoding is null){Environment.NewLine}EncodingName: {encodingName}{Environment.NewLine}Confidence: {confidence}");
}
}
else
{
Console.WriteLine($"Detection failed: {filename}");
}
}
}
}
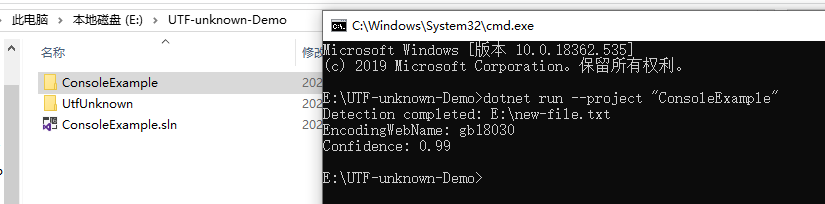
example result screenshot:
As others have mentioned, a string in C# is always encoded as UTF-16LE (System.Text.Encoding.Unicode).
Reading between the lines, what I believe what you're actually concerned about is whether or not the characters in your string are compatible with some other known encoding (i.e. will they "fit" in that other code page?).
In that case, the most correct solution I've found is to attempt the conversion and see if the string changes. If a character in your string doesn't "fit" in the destination encoding, the encoder will substitute it for some sentinel character that will (e.g. '?' is common).
// using System.Text;
// And if you're using the "System.Text.Encoding.CodePages" NuGet package, you
// need to call this once or GetEncoding will raise a NotSupportedException:
// Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
var srcEnc = Encoding.Unicode;
var dstEnc = Encoding.GetEncoding(1252); // 1252 Requires use of the "System.Text.Encoding.CodePages" NuGet package.
string srcText = "Some text you want to check";
string dstText = dstEnc.GetString(Encoding.Convert(srcEnc, dstEnc, srcEnc.GetBytes(srcText)));
// if (srcText == dstText) the srcText "fits" (it's compatible).
// else the srcText doesn't "fit" (it's not compatible)
© 2022 - 2024 — McMap. All rights reserved.