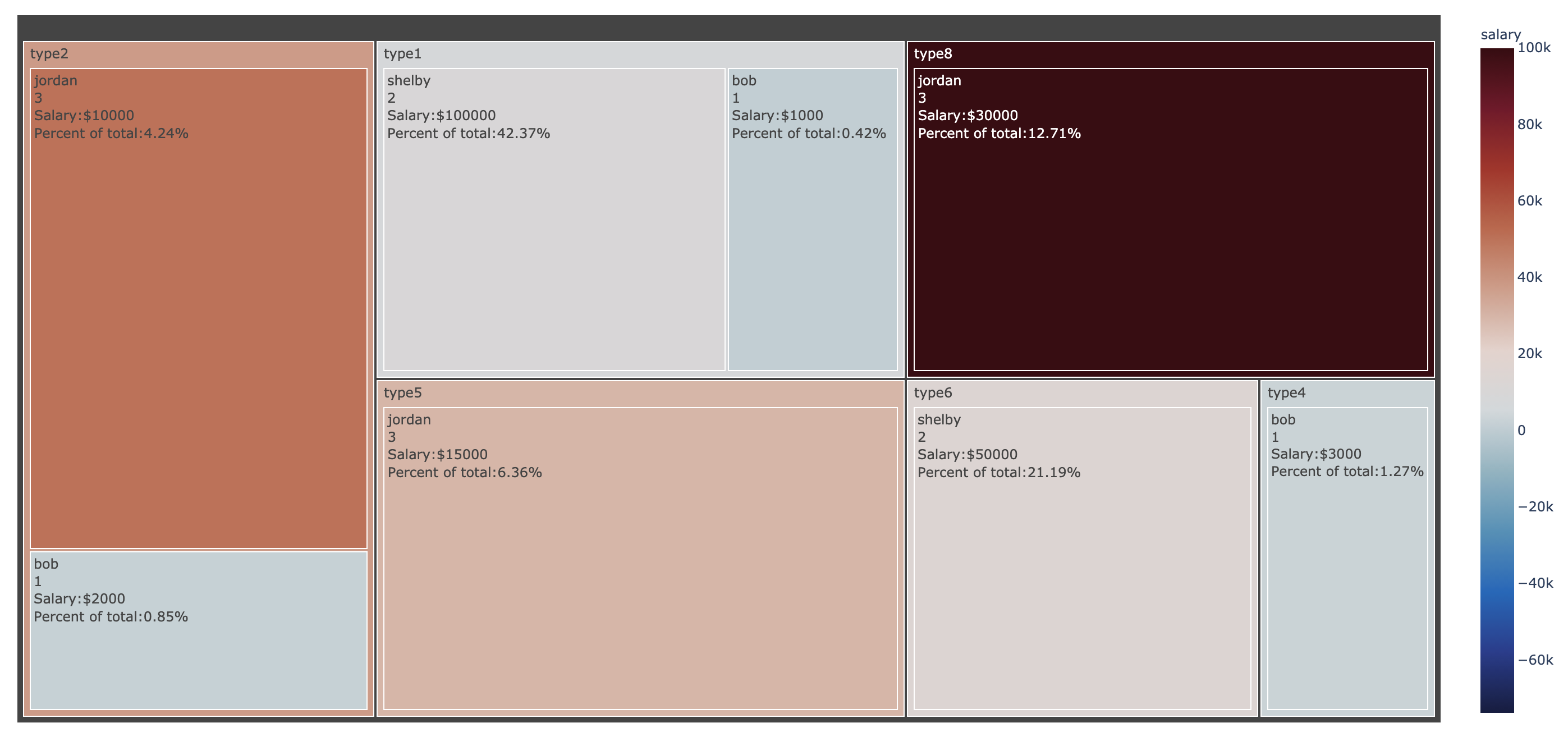
I am using plotly express to make a treemap. I would like to annotate my data sectors with a label as well as the % of the parent and the value that is used in the color scale.
How can I add an annotation to display the actual value that is used in the color argument of the treemap? In the below example code I would like to annotate "salary" for each sector. I would like to add some additional text to describe the numbers in each sector as well. For example "Percent of Total:" Appended to the percent value for more text description would be ideal to help annotate the treemap a bit more. Any ways to add custom text would be beneficial.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import plotly.express as px
d = {'count': [1,1,1,2,2,3,3,3,4],
'name': ['bob','bob','bob','shelby','shelby','jordan','jordan','jordan','jeff'],
'type': ['type1','type2','type4','type1','type6','type5','type8','type2',None],
'salary':[1000,2000,3000,10000,15000,30000,100000,50000,25000]}
df = pd.DataFrame(data=d)
# group data and aggregate
df_plot = df.groupby(['name','type'])[['salary','count']].sum().reset_index()
avg_salary = df_plot['salary'].sum()/df_plot['count'].sum()
# plot treemap
fig = px.treemap(df_plot,
values='count',
color='salary',
color_continuous_scale='balance',
color_continuous_midpoint=avg_salary,
path=['type','name'])
fig.data[0].textinfo = 'label+value+percent parent'
fig.show()