I am trying to grasp the concept of Semantic Web. I am finding it hard to understand what exactly is the difference between RDF and OWL. Is OWL an extension of RDF or these two are totally different technologies?
What is the difference between RDF and OWL? [closed]
Asked Answered
I personally found this slide deck quite useful and understandable: slideshare.net/rlovinger/rdf-and-owl –
Rondarondeau
I try to answer it in a short: RDF provides standardizations for the vocabulary used to characterize ontologies, which are summarized under the umbrella of Web Ontology Language (OWL) family e.g. when building ontologies of Knowledge systems. –
Dabble
While it's closed long time ago, I found the answers to be super confusing. I found most simple and clear answer to this question from Piotr Szwed, AGH University of Science and Technology in Kraków: - with OWL it is possible to specify cardinalities of object relations and datatype properties (attributes) - it is possible to use logical opeartors in definitions (e.g. use union of classes as a range of relation) Source: researchgate.net/post/… –
Cheapen
The semantic web comes in layers. This is a quick summary of the ones I think you're interested in.
Update: Please note that RDFS is used to define the structure of the data, not OWL. OWL describes semantic relationships which normal programming, such as a C struct, isn't fussed about and is closer to AI research & set theory.
Triples & URIs
Subject - Predicate - Object
These describe a single fact. Generally URI's are used for the subject and predicate. The object is either another URI or a literal such as a number or string. Literals can have a type (which is also a URI), and they can also have a language. Yes, this means triples can have up to 5 bits of data!
For example a triple might describe the fact that Charles is Harrys father.
<http://example.com/person/harry> <http://familyontology.net/1.0#hasFather> <http://example.com/person/charles> .
Triples are database normalization taken to a logical extreme. They have the advantage that you can load triples from many sources into one database with no reconfiguration.
RDF and RDFS
The next layer is RDF - The Resource Description Framework. RDF defines some extra structure to triples. The most important thing RDF defines is a predicate called "rdf:type". This is used to say that things are of certain types. Everyone uses rdf:type which makes it very useful.
RDFS (RDF Schema) defines some classes which represent the concept of subjects, objects, predicates etc. This means you can start making statements about classes of thing, and types of relationship. At the most simple level you can state things like http://familyontology.net/1.0#hasFather is a relationship between a person and a person. It also allows you to describe in human readable text the meaning of a relationship or a class. This is a schema. It tells you legal uses of various classes and relationships. It is also used to indicate that a class or property is a sub-type of a more general type. For example "HumanParent" is a subclass of "Person". "Loves" is a sub-class of "Knows".
RDF Serialisations
RDF can be exported in a number of file formats. The most common is RDF+XML but this has some weaknesses.
N3 is a non-XML format which is easier to read, and there's some subsets (Turtle and N-Triples) which are stricter.
It's important to know that RDF is a way of working with triples, NOT the file formats.
XSD
XSD is a namespace mostly used to describe property types, like dates, integers and so forth. It's generally seen in RDF data identifying the specific type of a literal. It's also used in XML schemas, which is a slightly different kettle of fish.
OWL
OWL adds semantics to the schema. It allows you to specify far more about the properties and classes. It is also expressed in triples. For example, it can indicate that "If A isMarriedTo B" then this implies "B isMarriedTo A". Or that if " C isAncestorOf D " and " D isAncestorOf E " then " C isAncestorOf E ". Another useful thing owl adds is the ability to say two things are the same, this is very helpful for joining up data expressed in different schemas. You can say that relationship "sired" in one schema is owl:sameAs "fathered" in some other schema. You can also use it to say two things are the same, such as the "Elvis Presley" on wikipedia is the same one on the BBC. This is very exciting as it means you can start joining up data from multiple sites (this is "Linked Data").
You can also use the OWL to infer implicit facts, such as "C isAncestorOf E".
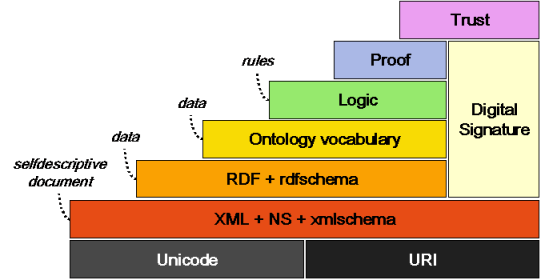
Here is an image of the Semantic Web layers : w3.org/2001/12/semweb-fin/swlevels.png Just for reference. –
Caecilian
{kind=link}
One part of this that's still unclear to me is that there appears to be some overlap between what RDFS and OWL can express. E.g., an owl:Class can look very similar to an rdfs:Class. (E.g., an entity of type owl:Class is often the subject of several RDFS predicates such as rdfs:comment and rdfs:subclassOf.) I'm struggling to understand how OWL is a layer on top of RDFS, because when it comes to defining classes, it looks more like a way to enrich what you could do with RDFS. –
Nevil
Depending on the OWL/OWL-2 profile you use, you have the 'additional' capability to enrich your knowledge base with DL axioms (e.g. property restrictions, disjointness, and many more). –
Dribble
@IanGriffiths: in fact under OWL2 semantics, owl:Class and rdfs:Class (as well as several more surprising pairs) are eqivalent: answers.semanticweb.com/questions/30954/… –
Rosemonde
...OWL, RDFS, XSD... are complementary languages... each one plays a role in the description of your domain and all join to enrich it... –
Slavophile
I don't really like this answer. It is confusing in the sense that it implies that Linked Data wasn't possible until OWL. Linked Data started to be possible already thanks of RDF (for example: en.wikipedia.org/wiki/Linked_data) clearly states "It builds upon standard Web technologies such as HTTP, RDF and URIs". "Joining" of data is already possible with RDF! OWL adds more power to that of course. –
Cheapen
In the Semantic Web levels shown here - w3.org/2001/12/semweb-fin/swlevels.png, does OWL fall into the same layer as RDF and RDFS? Also, as per your description of RDF and RDFS, I understand that they're Vocabularies. Would you say an Ontology is equivalent to a Vocabulary? –
Averi
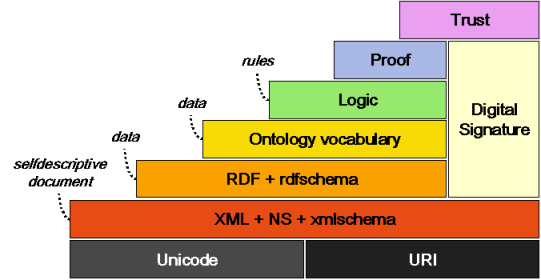{kind=link}
In short:
- RDF defines how to write stuff
- OWL defines what to write
As previous poster wrote, RDF is a specification which tells you how to define triples.
The problem is that RDF allows you to define everything, so you could compose a declaration like this:
| subject | predicate | object |
|---------|-----------|--------|
| Alex | Eats | Apples |
| Apples | Eats | Apples |
| Apples | Apples | Apples |
These triples form valid RDF documents.
But, semantically, you understand that these statements are incorrect and RDF cannot help you to validate what you have written.
This is not a valid ontology.
OWL specification defines exactly what you can write with RDF in order to have valid ontology.
Ontologies can have several properties.
Thats why OWL (ver 1) defines several versions like OWL DL, OWL Lite, OWL Full.
But note that OWL won't constrain what you can put in your RDF store - the OWL schema information is primarily used for inference, not for enforcing constraints. –
Trujillo
And to add to that, for enforcing constrains on RDF and/or OWL, there is another standard / language called Shapes Constraint Language (SHACL) –
Airboat
RDF, RDFS and OWL are means to express increasingly complex information or knowledge. All of them can be serialised in RDF/XML syntax (or any other RDF serialisation syntax like Turtle or N3 for instance).
These technologies are related and supposed to be interoperable, yet they have different origins that's maybe why the relation between them is complicated to grasp. The choice on one or the other depends on how much complexity the situation you are modelling requires.
Summary of expressivity
RDF: Straightforward representation, focused on the instances and on the mapping to their types (rdf:type). It is possible to define custom properties to link data and creating triples. RDF data are queried with SPARQL.
Example of RDF serialised in Turtle:
@prefix : <http://www.example.org/> .
:john rdf:type :Man .
:john :livesIn "New-York" .
:livesIn rdf:type rdf:Property .
RDFS: Some situations are not easily modelled by RDF alone, it is sometimes interesting to represent more complex relations like subclasses (the type of a type) for example. RDFS provides special means to represent such cases, with constructs like rdfs:subClassOf, rdfs:range or rdfs:domain. Ideally, a reasoner can understand the RDFS semantics and expand the number of triples based on the relations: For instance if you have the triples John a Man and Man rdfs:subClassOf Human then you should generate as well the triple John a Human. Note that this is not possible to do with RDF alone. RDFS data are queried using SPARQL.
Example of RDFS serialised in Turtle:
@prefix : <http://www.example.org/> .
:john rdf:type :Man .
:Man rdfs:subClassOf :Human .
:john :livesIn "New-York" .
:livesIn rdf:type rdf:Property .
# After reasoning
:john rdf:type :Human .
OWL: The highest level of expressivity. Relation between classes can be formally modelled based on description logics (mathematical theory). OWL relies heavily on the reasoner, it is possible to express complex constructs such as chained properties for instance or restriction between classes. OWL serves to build ontologies or schema on the top of RDF datasets. As OWL can be serialised as RDF/XML, it is theoretically possible to query it via SPARQL, yet it is much more intuitive to query an OWL ontology with a DL query (which is usually a standard OWL class expression). Example of OWL constructs serialised in Turtle.
@prefix : <http://www.example.org/> .
:livesIn rdf:type owl:DatatypeProperty .
:Human rdf:type owl:Class .
:Man rdf:type owl:Class .
:Man rdfs:subClassOf :Human .
:John rdf:type :Man .
:John rdf:type owl:NamedIndividual .
Subclass is not "the type of a type": that's a metaclass. "X a Y. Y a Z." is different from "X a Y. Y subClassOf Z" –
Rosemonde
Firstly, an as has been pointed out before, owl can be serialised in RDF.
Secondly, OWL adds ontological capability to RDF (which on its own only provides extremely limited capability for formal knownledge representation), by providing the apparatus to define the components of your triple using formal computable first order description logic. That is what posters here mean by when they talk about "semantic richness".
Thirdly, it's important to realise that in OWL-Full (for OWL 1) rdfs:class and owl:class are equivalent and in OWL-DL, owl:class is a subclass of rdfs:class. In effect, this means that you can use an OWL ontology as a schema for RDF (which does not formally require schemata).
I hope that helps to clarify further.
Very good post...I want to save RDF triples in Oracle 11g, can I use OWL as a schema for my RDF? –
Woodborer
When you are using the term RDF you have to distinguish two things:
You can refer to RDF as a concept:
A way of describing things/logic/anything using collections of triples.
Example:
"Anna has apples." "Apples are healthy."
Above you have two triples that describe two resources "Anna" and "apples". The concept of RDF (Resource Description Framework) is that you can describe resources (anything) with sets of only 3 words (terms). At this level you don't care about how you are storing information, whether you have a string of 3 words, or a painting on a wall, or a table with 3 columns etc.
At this conceptual level the only thing that is important is that you can represent anything that you want using triple statements.
You can refer to RDF as a vocabulary
A vocabulary is just a collection of term definitions stored in a file or somewhere. These defined terms have the purpose of being generally reused in other descriptions so people can describe data (resources) more easily and in a standard manner.
On the web you can find some standard vocabularies like:
RDF (https://www.w3.org/1999/02/22-rdf-syntax-ns)
RDFS (https://www.w3.org/2000/01/rdf-schema#)
OWL (https://www.w3.org/2002/07/owl)
The RDF vocubalary defines terms that help you to describe (at the most basic level as possible) individuals/instances of classes. Example: rdf:type, rdf:Property.
With rdf:type you can describe that some resource is an instance of a class:
<http://foo.com/anna> rdf:type <http://foo.com/teacher>So the RDF vocabulary has terms that are targeting basic descriptions of class instances and some other descriptions (like the triple statement definition, or the predicate definition... in general things that are realted to the RDF concept).
The RDFS vocabulary has term definitions that help you describe classes and relationships between them. RDFS vocabulary doesn't care about instances of classes (individuals) like the RDF vocabulary. Example: the rdfs:subClassOf property which you can use to describe that a class A is subclass of class B.
The RDF and the RDFS vocabularies are dependent to one another. RDF defines it's terms using RDFS, and RDFS uses RDF for defining it's own terms.
The RDF/RDFS vocabularies provide terms that can be used to create very basic descriptions of resources. If you want to have more complex and accurate descriptions you have to use the OWL vocabulary.
The OWL vocabulary comes with a set of new terms targeting more detailed descriptions. These term are defined using terms from RDF/RDFS vocabularies.
owl:ObjectProperty a rdfs:Class ;
rdfs:label "ObjectProperty" ;
rdfs:comment "The class of object properties." ;
rdfs:isDefinedBy <http://www.w3.org/2002/07/owl#> ;
rdfs:subClassOf rdf:Property .
owl:DatatypeProperty a rdfs:Class ;
rdfs:label "DatatypeProperty" ;
rdfs:comment "The class of data properties." ;
rdfs:isDefinedBy <http://www.w3.org/2002/07/owl#> ;
rdfs:subClassOf rdf:Property .
owl:TransitiveProperty a rdfs:Class ;
rdfs:label "TransitiveProperty" ;
rdfs:comment "The class of transitive properties." ;
rdfs:isDefinedBy <http://www.w3.org/2002/07/owl#> ;
rdfs:subClassOf owl:ObjectProperty .
As you can see above the OWL vocabulary extends the concept of rdf:Property by creating new types of Properties that are less abstract and can provide more accurate descriptions of resources.
Conclusions:
- RDF is a concept or a way of describing resources using sets of triples.
- RDF triples can be stored in different formats (XML/RDF, Turtle etc.)
- The concept of RDF is the base model of all semantic web technologies and structures (like vocabularies).
- RDF is also a vocabulary that along with the RDFS vocabulary provides a set of terms that can be used for creating general/abstract descriptions of resources.
- OWL is a vocabulary built with RDF and RDFS vocabularies that provide new terms for creating more detailed descriptions of resources.
- All semantic web vocabularies (RDF, RDFS, OWL etc) are built by respecting the RDF concept.
- And of course the OWL vocabulary has behind the scenes all kind of complex logic and concepts which define the Web Ontology Language. The OWL vocabulary is just a way of using all that logic in practice.
RDFS allows you to express the relationships between things by standardizing on a flexible, triple-based format and then providing a vocabulary ("keywords" such as rdf:type or rdfs:subClassOf) which can be used to say things.
OWL is similar, but bigger, better, and badder. OWL lets you say much more about your data model, it shows you how to work efficiently with database queries and automatic reasoners, and it provides useful annotations for bringing your data models into the real world.
1st Difference: Vocabulary
Of the differences between RDFS and OWL, the most important is just that OWL provides a far, far larger vocabulary that you can use to say things.
For example, OWL includes all your old friends from RDFS such as rdfs:type, rdfs:domain, and rdfs:subPropertyOf. However, OWL also gives you new and better friends! For example, OWL lets you describe you data in terms of set operations:
Example:Mother owl:unionOf (Example:Parent, Example:Woman)
It lets you define equivalences across databases:
AcmeCompany:JohnSmith owl:sameAs PersonalDatabase:JohnQSmith
It lets you restrict property values:
Example:MyState owl:allValuesFrom (State:NewYork, State:California, …)
in fact, OWL provides so much new, sophisticated vocabulary to use in data modeling and reasoning that gets its own lesson!
2nd Difference: Rigidity
Another major difference is that unlike RDFS, OWL not only tells you how you can use certain vocabulary, it actually tells you how you cannot use it. By contrast, RDFS gives you an anything goes world in which you can add pretty much any triple you want.
For example, in RDFS, anything you feel like can be an instance of rdfs:Class. You might decide to say that Beagle is an rdfs:Class and then say that Fido is an instance of Beagle:
Example: Beagle rdf:Type rdfs:Class
Example:Fido rdf:Type Example: Beagle
Next, you might decide that you would like to say things about beagles, perhaps you want to say that Beagle is an instance of dogs bred in England:
Example:Beagle rdf:Type Example:BreedsBredInEngland
Example: BreedsBredInEngland rdf:Type rdfs:Class
The interesting thing in this example is that Example:Beagle is being used as both a class and an instance. Beagle is a class that Fido is a member of, but Beagle is itself a member of another class: Things Bred in England.
In RDFS, all this is perfectly legal because RDFS doesn't really constrain which statements you can and cannot insert. In OWL, by contrast, or at least in some flavors of OWL, the above statements are actually not legal: you're simply not allowed to say that something can be both a class and an instance.
This is then a second major difference between RDFS and OWL. RDFS enables a free-for-all, anything goes kind of world full of the Wild West, Speak-Easies, and Salvador Dali. The world of OWL imposes a much more rigid structure.
3rd Difference: Annotations, the meta-meta-data
Suppose that you've spent the last hour building an ontology that describes your radio manufacturing business. During lunch, your task is to build an ontology for your clock manufacturing business. This afternoon, after a nice coffee, your boss now tells you that you'll have to build an ontology for your highly profitable clock-radio business. Is there a way to easily reuse the morning's work?
OWL makes doing things like this very, very easy. Owl:Import is what you would use in the clock-radio situation, but OWL also gives you a rich variety of annotations such as owl:versionInfo, owl:backwardsCompatibleWith, and owl:deprecatedProperty, which can easily be used link data models together into a mutually coherent whole.
Unlike RDFS, OWL is sure to satisfy all of your meta-meta-data-modeling needs.
Conclusion
OWL gives you a much larger vocabulary to play with, which makes it easy to say anything you might want to say about your data model. It even allows you to tailor what you say based on the computational realities of today's computers and to optimize for particular applications (for search queries, for example.) Further, OWL allows you to easily express the relationships between different ontologies using a standard annotation framework.
All these are advantages as compared to RDFS, and are typically worth the extra effort it takes to familiarize yourself with them.
Source : RDFS vs. OWL
RDF is a way to define a triple 'subject','predicate', 'value'. For example, if I want to say,
"my name is Pierre"
I would write
<mail:[email protected]> <foaf:name> "Pierre"
See the <foaf:name> ? it is part of the FOAF ontology. An ontology is a formal way to describe the properties, the classes of a given subject and OWL is a (RDF) way to define an ontology.
You use C++, Java, etc... to define a Class, a subclass, a field, etc...
class Person
{
String email_as_id;
String name;
}
RDF uses OWL to define these kinds of statements.
Another place to ask this kind of question: http://www.semanticoverflow.com/
Disagree with: "RDF uses OWL to define this kind of statements". RDF does not use OWL in any way. This is other way around: OWL uses RDF Schema which uses RDF. –
Foreordination
@Stefano Where do they find people to run, that's the real question. –
Ringleader
I am trying to grasp the concept of Semantic Web. I am finding it hard to understand what exactly is the difference between RDF and OWL. Is OWL an extension of RDF or these two are totally different technologies?
In short, yes you could say that OWL is an extension of RDF.
In more detail, with RDF you can describe a directed graph by defining subject-predicate-object triples. The subject and the object are the nodes, the predicate is the edge, or by other words, the predicate describes the relation between the subject and the object. For example :Tolkien :wrote :LordOfTheRings or :LordOfTheRings :author :Tolkien, etc... Linked data systems use these triples to describe knowledge graphs, and they provide ways to store them, query them. Now these are huge systems, but you can use RDF by smaller projects. Every application has a domain specific language (or by DDD terms ubiquitous language). You can describe that language in your ontology/vocabulary, so you can describe the domain model of your application with a graph, which you can visualize show it to business ppl, talk about business decisions based on the model, and build the application on top of that. You can bind the vocab of your application to the data it returns and to a vocabulary known by the search engines, like microdata (for example you can use HTML with RDFA to do this), and so search engines can find your applications easily, because the knowledge about what it does will be machine processable. This is how semantic web works. (At least this is how I imagine it.)
Now to describe object oriented applications you need types, classes, properties, instances, etc... With RDF you can describe only objects. RDFS (RDF schema) helps you to describe classes, inheritance (based on objects ofc.), but it is too broad. To define constraints (for example one kid per chinese family) you need another vocab. OWL (web ontology language) does this job. OWL is an ontology which you can use to describe web applications. It integrates the XSD simpleTypes.
So RDF -> RDFS -> OWL -> MyWebApp is the order to describe your web application in a more and more specific way.
Thank you - this seems very helpful. I think you are saying (please let me know if I have understood this correctly) that (1). RDF allows specifying direct relationships between objects (
personA friendsWith personB), that (2) RDFS extends this by providing the ability to specify relationships between object classes - i.e class Person <has 'friendsWith' relationship> Person. That allows you to then phrase RDF via class: A:typeof:person friendsWith B:<typeof:person>. And (3), OWL then allows you to specify constraints of the relationships? –
Lancaster i.e. a person can have maximum 4 "friendsWith" connections`? –
Lancaster
@ZachSmith Yes. –
Quiroz
Such a good answer - thank you. Makes it easier to read everything else on this page. –
Lancaster
@ZachSmith yw . –
Quiroz
@ZachSmith You can define constraints with SHACL too: w3.org/TR/shacl Some ppl. recommend that, I am not sure, I need to read a lot more in the topic, maybe compare it with OWL on an example. –
Quiroz
A picture speaks a thousand words! This diagram below should reinforce what Christopher Gutteridge said in this answer that the semantic web is a "layered architecture".
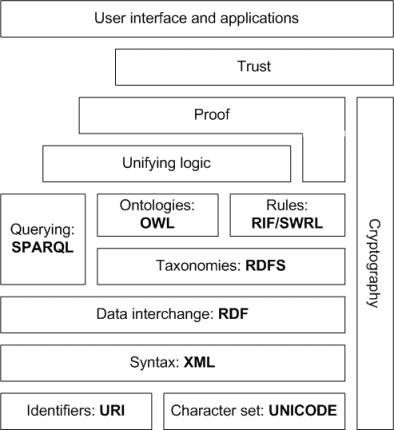
Source: https://www.obitko.com/tutorials/ontologies-semantic-web/semantic-web-architecture.html
In the WC3 document object model, a document is an abstract thing: an element with text, comments, attributes, and other elements nested within it.
In the semantic web, we deal with a set of "triples". Each triple is:
- a subject, the thing the triple is about, the id, the database primary key - a URI; and
- the predicate, the "verb", the "property", the "database column" - another URI; and
- the object, an atomic value or some URI.
OWL is to the semantic web as Schemas are to the W3C document object model. It documents what the various URIs mean and specify how they are used in a formal way that can be checked by a machine. A semantic web may or may not be valid with respect to the OWL that applies to it, just as a document may or may not be valid with respect to a schema.
RDF is to the semantic web as XML is to the DOM - it's a serialisation of a set of triples.
Of course, RDF is usually serialised as an XML documents ... but it's important to understand that RDF is not the same thing as "the XML serialisation of RDF".
Likewise, OWL can be serialised using OWL/XML, or (sorry about this) it can be expressed as RDF, which itself is usually serialised as XML.
The basic semantic web stack has been explained a lot already in this thread. I'd like to focus on the initial question and compare RDF to OWL.
- OWL is a super-set of RDF & RDF-S (on top)
- OWL allows to effectively working with RDF & RDF-S
- OWL has some extended vocabulary
- classes & individuals ("instances")
- properties & data-types ("predicates")
- OWL is required for proper reasoning and inference
- OWL comes in three dialects lite, description logic & full
Using OWL is essential to get more meaning (reasoning & inference) by just knowing a few facts. This "dynamically created" information can further be used for accordant queries like in SPARQL.
Some examples will show that that actually works with OWL - these have been taken from my talk about the basics of semantic web at the TYPO3camp Mallorca, Spain in 2015.
equivalents by rules
Spaniard: Person and (inhabitantOf some SpanishCity)
This means that a Spaniard must be a Person (and thus inherits all properties in the inferencing part) and must live in at least one (or more) SpanishCity.
meaning of properties
<Palma isPartOf Mallorca>
<Mallorca contains Palma>
The example shows the result of applying inverseOf to the properties isPartOf and contains.
- inverse
- symmetric
- transitive
- disjoint
- ...
cardinalities of properties
<:hasParent owl:cardinality “2“^^xsd:integer>
This defines that each Thing (in this scenario most probably a Human) has exactly two parents - the cardinality is assigned to the hasParent property.
- minimum
- maximum
- exact
The Resource Description Framework (RDF) is a powerful formal knowledge representation language and a fundamental standard of the Semantic Web. It has its own vocabulary that defines core concepts and relations (e.g., rdf:type corresponds to the isA relationship), and a data model that enables machine-interpretable statements in the form of subject-predicate-object (resource-property-value) triples, called RDF triples, such as picture-depicts-book. The extension of the RDF vocabulary with concepts required to create controlled vocabularies and basic ontologies is called RDF Schema or RDF Vocabulary Description Language (RDFS). RDFS makes it possible to write statements about classes and resources, and express taxonomical structures, such as via superclass-subclass relationships.
Complex knowledge domains require more capabilities than what is available in RDFS, which led to the introduction of OWL. OWL supports relationships between classes (union, intersection, disjointness, equivalence), property cardinality constraints (minimum, maximum, exact number, e.g., every person has exactly one father), rich typing of properties, characteristics of properties and special properties (transitive, symmetric, functional, inverse functional, e.g., A ex:hasAncestor B and B ex:hasAncestor C implies that A ex:hasAncestor C), specifying that a given property is a unique key for instances of a particular class, and domain and range restrictions for properties.
Although you are voted down in the page, I think you have the best answer. I found other answers super confusing -- ironically especially the most voted. I have one aditional question though that is still bugging me: Does it mean simply that RDFS CANNOT imply relationship accross not directly related nodes like OWL? Like in the example A ex:hasAncestor B and B ex:hasAncestor C implies that A ex:hasAncestor C. –
Cheapen
© 2022 - 2024 — McMap. All rights reserved.