A good conceptual understanding of what the AMQP protocol does "under the hood" is useful here. I would offer that the documentation and API that AMQP 0.9.1 chose to deploy makes this particularly confusing, so the question itself is one which many people have to wrestle with.
TL;DR
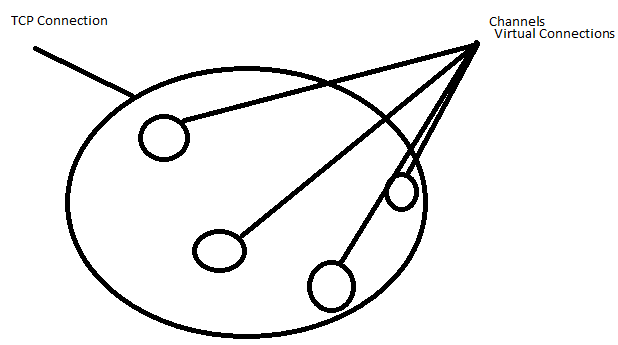
A connection is the physical negotiated TCP socket with the AMQP server. Properly-implemented clients will have one of these per application, thread-safe, sharable among threads.
A channel is a single application session on the connection. A thread will have one or more of these sessions. AMQP architecture 0.9.1 is that these are not to be shared among threads, and should be closed/destroyed when the thread that created it is finished with it. They are also closed by the server when various protocol violations occur.
A consumer is a virtual construct that represents the presence of a "mailbox" on a particular channel. The use of a consumer tells the broker to push messages from a particular queue to that channel endpoint.
Connection Facts
First, as others have correctly pointed out, a connection is the object that represents the actual TCP connection to the server. Connections are specified at the protocol level in AMQP, and all communication with the broker happens over one or more connections.
- Since it's an actual TCP connection, it has an IP Address and Port #.
- Protocol parameters are negotiated on a per-client basis as part of setting up the connection (a process known as the handshake.
- It is designed to be long-lived; there are few cases where connection closure is part of the protocol design.
- From an OSI perspective, it probably resides somewhere around Layer 6
- Heartbeats can be set up to monitor the connection status, as TCP does not contain anything in and of itself to do this.
- It is best to have a dedicated thread manage reads and writes to the underlying TCP socket. Most, if not all, RabbitMQ clients do this. In that regard, they are generally thread-safe.
- Relatively speaking, connections are "expensive" to create (due to the handshake), but practically speaking, this really doesn't matter. Most processes really will only need one connection object. But, you can maintain connections in a pool, if you find you need more throughput than a single thread/socket can provide (unlikely with current computing technology).
Channel Facts
A Channel is the application session that is opened for each piece of your app to communicate with the RabbitMQ broker. It operates over a single connection, and represents a session with the broker.
- As it represents a logical part of application logic, each channel usually exists on its own thread.
- Typically, all channels opened by your app will share a single connection (they are lightweight sessions that operate on top of the connection). Connections are thread-safe, so this is OK.
- Most AMQP operations take place over channels.
- From an OSI Layer perspective, channels are probably around Layer 7.
- Channels are designed to be transient; part of the design of AMQP is that the channel is typically closed in response to an error (e.g. re-declaring a queue with different parameters before deleting the existing queue).
- Since they are transient, channels should not be pooled by your app.
- The server uses an integer to identify a channel. When the thread managing the connection receives a packet for a particular channel, it uses this number to tell the broker which channel/session the packet belongs to.
- Channels are not generally thread-safe as it would make no sense to share them among threads. If you have another thread that needs to use the broker, a new channel is needed.
Consumer Facts
A consumer is an object defined by the AMQP protocol. It is neither a channel nor a connection, instead being something that your particular application uses as a "mailbox" of sorts to drop messages.
- "Creating a consumer" means that you tell the broker (using a channel via a connection) that you would like messages pushed to you over that channel. In response, the broker will register that you have a consumer on the channel and begin pushing messages to you.
- Each message pushed over the connection will reference both a channel number and a consumer number. In that way, the connection-managing thread (in this case, within the Java API) knows what to do with the message; then, the channel-handling thread also knows what to do with the message.
- Consumer implementation has the widest amount of variation, because it's literally application-specific. In my implementation, I chose to spin off a task each time a message arrived via the consumer; thus, I had a thread managing the connection, a thread managing the channel (and by extension, the consumer), and one or more task threads for each message delivered via the consumer.
- Closing a connection closes all channels on the connection. Closing a channel closes all consumers on the channel. It is also possible to cancel a consumer (without closing the channel). There are various cases when it makes sense to do any of the three things.
- Typically, the implementation of a consumer in an AMQP client will allocate one dedicated channel to the consumer to avoid conflicts with the activities of other threads or code (including publishing).
In terms of what you mean by consumer thread pool, I suspect that Java client is doing something similar to what I programmed my client to do (mine was based off the .Net client, but heavily modified).