tl;dr
I am not asking about one's likes or dislikes about syntax or other functionalities provided by purrr.
Choose the tool that matches your use case, and maximizes your productivity. For production code that prioritizes speed use *apply, for code that requires small memory footprint use map. Based on ergonomics, map is likely preferable for most users and most one-off tasks.
Convenience
update October 2021
Since both the accepted answer and the 2nd most voted post mention syntax convenience:
R versions 4.1.1 and higher now support shorthand anonymous function \(x) and pipe |> syntax. To check your R version, use version[['version.string']].
library(purrr)
library(repurrrsive)
lapply(got_chars[1:2], `[[`, 2) |>
lapply(\(.) . + 1)
#> [[1]]
#> [1] 1023
#>
#> [[2]]
#> [1] 1053
map(got_chars[1:2], 2) %>%
map(~ . + 1)
#> [[1]]
#> [1] 1023
#>
#> [[2]]
#> [1] 1053
Syntax for the purrr approach generally is shorter to type if your task involves more than 2 manipulations of list-like objects.
nchar(
"lapply(x, fun, y) |>
lapply(\\(.) . + 1)")
#> [1] 45
nchar(
"library(purrr)
map(x, fun) %>%
map(~ . + 1)")
#> [1] 45
Considering a person might write tens or hundreds of thousands of these calls in their career, this syntax length difference can equate to writing 1 or 2 novels (av. novel 80 000 letters), given the code is typed. Further consider your code input speed (~65 words per minute?), your input accuracy (do you find that you often mistype certain syntax (\"< ?), your recall of function arguments, then you can make a fair comparison of your productivity using one style, or a combination of the two.
Another consideration might be your target audience. Personally I found explaining how purrr::map works harder than lapply precisely because of its concise syntax.
1 |>
lapply(\(.z) .z + 1)
#> [[1]]
#> [1] 2
1 %>%
map(~ .z+ 1)
#> Error in .f(.x[[i]], ...) : object '.z' not found
but,
1 %>%
map(~ .+ 1)
#> [[1]]
#> [1] 2
Speed
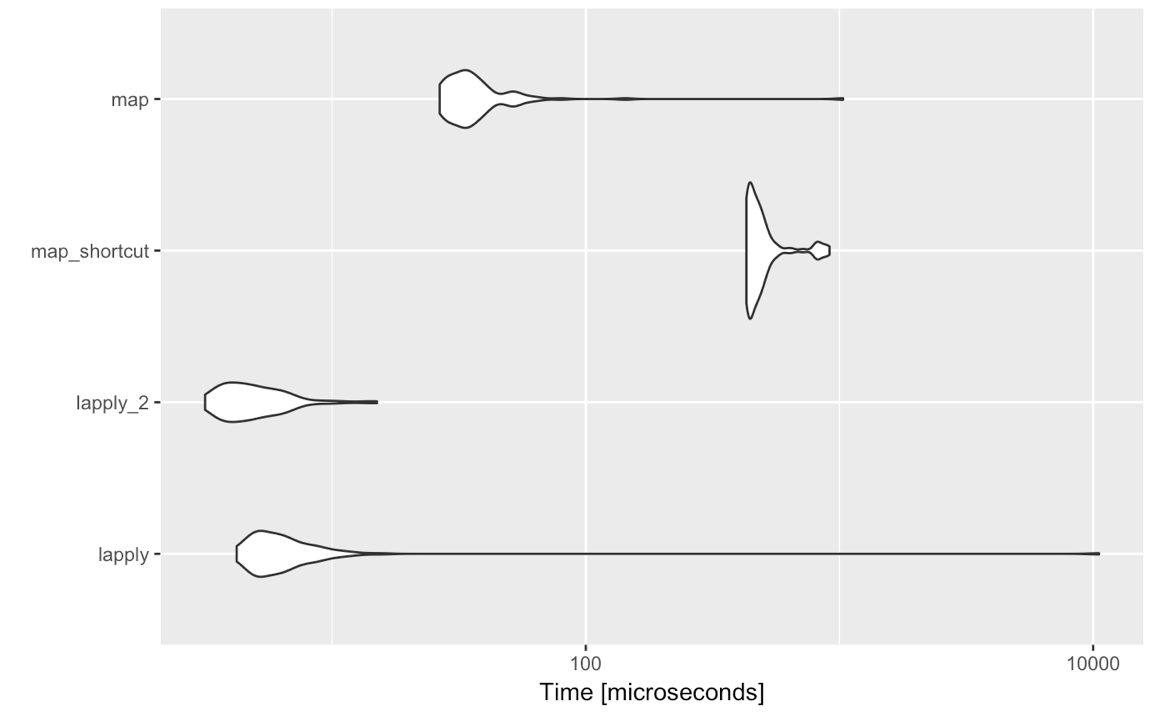
Often when dealing with list-like objects, multiple operations are performed. A nuance to the discussion that the overhead of purrr is insignificant in most code - dealing with large lists and use cases.
got_large <- rep(got_chars, 1e4) # 300 000 elements, 1.3 GB in memory
bench::mark(
base = {
lapply(got_large, `[[`, 2) |>
lapply(\(.) . * 1e5) |>
lapply(\(.) . / 1e5) |>
lapply(\(.) as.character(.))
},
purrr = {
map(got_large, 2) %>%
map(~ . * 1e5) %>%
map(~ . / 1e5) %>%
map(~ as.character(.))
}, iterations = 100,
)[c(1, 3, 4, 5, 7, 8, 9)]
# A tibble: 2 x 7
expression median `itr/sec` mem_alloc n_itr n_gc total_time
<bch:expr> <bch:tm> <dbl> <bch:byt> <int> <dbl> <bch:tm>
1 base 1.19s 0.807 9.17MB 100 301 2.06m
2 purrr 2.67s 0.363 9.15MB 100 919 4.59m
This diverges the more actions are performed. If you are writing code that is used routinely by some users or packages depend on it, the speed might be a significant factor to consider in your choice between base R and purr. Notice purrr has a slightly lower memory footprint.
There is, however a counterargument: If you want speed, go to a lower level language.
tidyversethough, you may benefit from the pipe%>%and anonymous functions~ .x + 1syntax – Anachronismpurrr::mapprovides a range of functions, such asmap_int,map_dbl,map_lgl, andmap2etc. that extend the functionality beyondlapplywhile keeping a consistent syntax. – Capstanpurrr/tests/comparingmap()andlapply()outputs:test_that("map forces arguments in same way as base R", { f_map <- map(1:2, function(i) function(x) x + i) ; f_base <- lapply(1:2, function(i) function(x) x + i) ; expect_equal(f_map[[1]](0), f_base[[1]](0)) ; expect_equal(f_map[[2]](0), f_base[[2]](0)) })and interestingly, it fails when I copy-paste-and-run it. Does it have to do with evaluation rules? github.com/tidyverse/purrr/blob/master/tests/testthat/… – Anachronism~{}shortcut lambda (with or without the{}seals the deal for me for plainpurrr::map(). The type-enforcement of thepurrr::map_…()are handy and less obtuse thanvapply().purrr::map_df()is a super expensive function but it also simplifies code. There's absolutely nothing wrong with sticking with base R[lsv]apply(), though. – Gasifyvapply,mapplyand friends. It's not because you don't know how to do it, that it doesn't exist in base R. Nothing againstpurrr::map, but it's JAF: Just Another Function. – Hightest0.2.2.9000, now the test passes. Thank you – Anachronismpurrrstuff. My point is following:tidyverseis fabulous for analyses/ interactive/reports stuff, not for programming. If you are into having to uselapplyormapthen you are programming and may end up one day with creating a package. Then the less dependencies the best. Plus: I sometime see people usingmapwith quite obscure syntax after. And now that I see performances testing: if you are used toapplyfamily: stick to it. – Jihadlapplycall with amapcall and expect my code not to break?". This removes the issue of some people interpreting your question as opinion-based and will still get you the right answers (if I got your question right)... – Upholster