The original question was in regard to TensorFlow implementations specifically. However, the answers are for implementations in general. This general answer is also the correct answer for TensorFlow.
When using batch normalization and dropout in TensorFlow (specifically using the contrib.layers) do I need to be worried about the ordering?
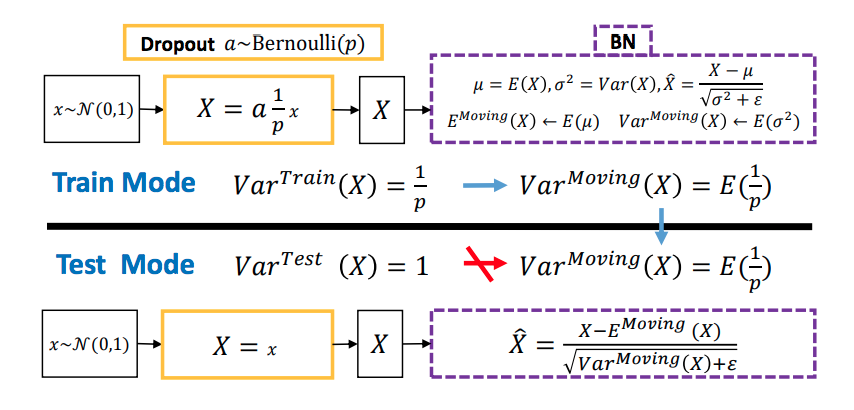
It seems possible that if I use dropout followed immediately by batch normalization there might be trouble. For example, if the shift in the batch normalization trains to the larger scale numbers of the training outputs, but then that same shift is applied to the smaller (due to the compensation for having more outputs) scale numbers without dropout during testing, then that shift may be off. Does the TensorFlow batch normalization layer automatically compensate for this? Or does this not happen for some reason I'm missing?
Also, are there other pitfalls to look out for in when using these two together? For example, assuming I'm using them in the correct order in regards to the above (assuming there is a correct order), could there be trouble with using both batch normalization and dropout on multiple successive layers? I don't immediately see a problem with that, but I might be missing something.
Thank you much!
UPDATE:
An experimental test seems to suggest that ordering does matter. I ran the same network twice with only the batch norm and dropout reverse. When the dropout is before the batch norm, validation loss seems to be going up as training loss is going down. They're both going down in the other case. But in my case the movements are slow, so things may change after more training and it's just a single test. A more definitive and informed answer would still be appreciated.