Cannot find a clean way to set Stackdriver alert notifications on errors in cloud functions
I am using a cloud function to process data to cloud data store. There are 2 types of errors that I want to be alerted on:
- Technical exceptions which might cause function to 'crash'
- Custom errors that we are logging from the cloud function
I have done the below,
- Created a log metric searching for specific errors (although this will not work for 'crash' as the error message can be different each time)
- Created an alert for this metric in Stackdriver monitoring with parameters as in below code section
This is done as per the answer to the question, how to create alert per error in stackdriver
For the first trigger of the condition I receive an email. However, on subsequent triggers lets say on the next day, I don't. Also the incident is in 'opened' state.
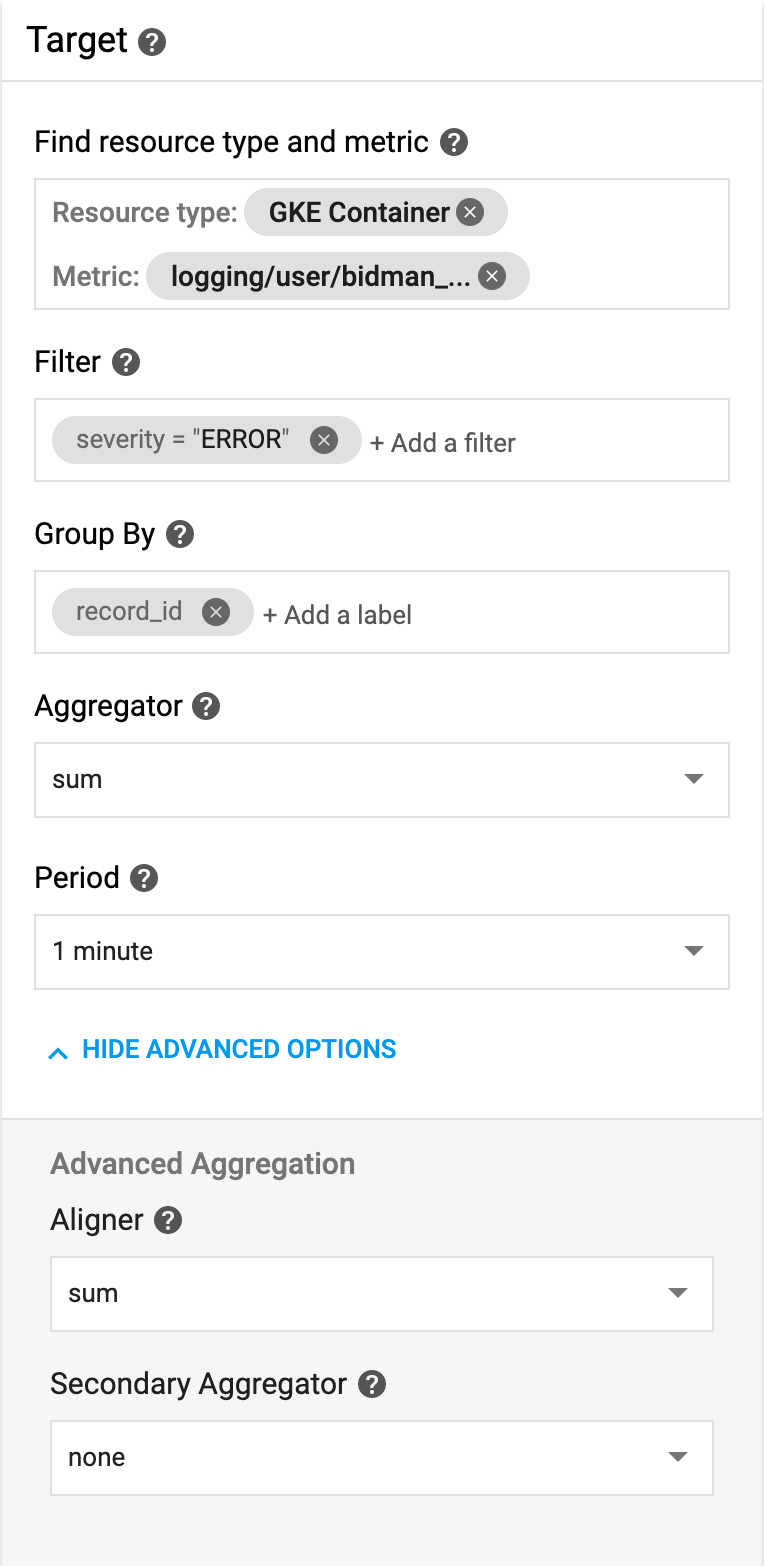
Resource type: cloud function
Metric:from point 2 above
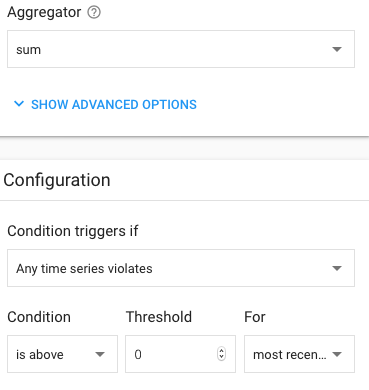
Aggregation: Aligner: count, Reducer: None, Alignment period: 1m
Configuration: Condition triggers if: Any time series violates, Condition:
is above, Threshold: 0.001, For: 1 min
So I have 3 questions,
Is this the right way to do to satisfy my requirement of creating alerts?
How can I still receive alert notifications for subsequent errors?
How to set the incident to 'resolved' either automatically/ manually?