I would like to find the overlapping dates for each ID and create a new row with the overlapping dates and also combine the characters (char) for the lines. It is possible that my data will have >2 overlaps and need >2 combinations of characters. eg. ERM
Data:
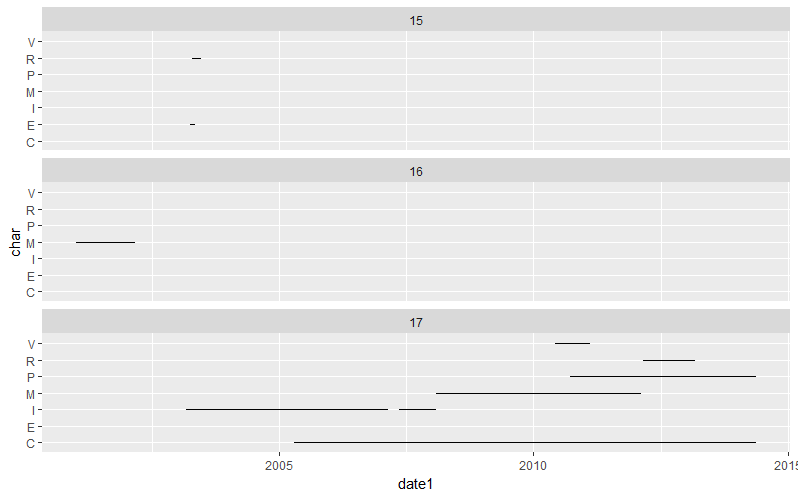
ID date1 date2 char
15 2003-04-05 2003-05-06 E
15 2003-04-20 2003-06-20 R
16 2001-01-02 2002-03-04 M
17 2003-03-05 2007-02-22 I
17 2005-04-15 2014-05-19 C
17 2007-05-15 2008-02-05 I
17 2008-02-05 2012-02-14 M
17 2010-06-07 2011-02-14 V
17 2010-09-22 2014-05-19 P
17 2012-02-28 2013-03-04 R
Output I would like:
ID date1 date2 char
15 2003-04-05 2003-04-20 E
15 2003-04-20 2003-05-06 ER
15 2003-05-06 2003-06-20 R
16 2001-01-02 2002-03-04 M
17 2003-03-05 2005-04-15 I
17 2005-04-15 2007-02-22 IC
17 2005-04-15 2007-05-15 C
17 2007-05-15 2008-02-05 CI
17 2008-02-05 2012-02-14 CM
17 2010-06-07 2011-02-14 CV
17 2010-09-22 2014-05-19 CP
17 2012-02-28 2013-03-04 CR
17 2014-05-19 2014-05-19 P
17 2010-06-07 2012-02-14 MV
17 2010-09-22 2011-02-14 VP
17 2012-02-28 2013-03-04 RP
What I have tried: I have tried using subtracting date 2 from the current row from the row below using:
df$diff <- c(NA,df[2:nrow(tdf), "date1"] - df[1:(nrow(df)-1), "date2"])
Then to determine the overlaps between the rows:
df$overlap[which(df$diff<1)] <-1
df$overlap.up <- c(df$overlap[2:(nrow(df))], "NA")
df$overlap.final[which(df$overlap==1 | df$overlap.up==1)] <- 1
I then selected those that had an overlap.final==1 and put them into another dataframe and found the overlaps for each ID.
However, I have realized that this is way too simplistic and flawed, because it only selects overlaps that occur sequentially (using the difference in dates in the first step). What I need to do is to take the series of dates for each ID and loop through each combination to determine if there is an overlap and then, if so, record that start and end date and create a new character “char” signalling what was combined during those two dates. I think I need a loop to do this.
I tried to create a loop to find the overlap intervals between date1 and date 2
df <- df[which(!duplicated(df$ ID)),]
for (i in 1:nrow(df)) {
tmp <- length(which(df $ID[i] & (df$date1[i] >df$date1 & df$date1[i]< df$date2) | (df$date2[i] < df$date2& df$date2[i]> df$date1))) >0
df$int[i]<- tmp
}
However this does not work.
After identifying the overlapping intervals, I need to create new rows for each new start and end date and a new character that represents the overlap.
Another version of the loop I have tried to identify overlaps:
for (i in 1:nrow(df)) {
if (df$ID[i]==IDs$ID){
tmp <- length(df, df$ ID[i]==IDs$ & (df$date1[i]> df$date1 & df$date1 [i]< df$date2 | df$date2[i] < df$date2 & df$date2[i]> df$date1)) >0
df$int[i]<- tmp
}
}
IRangespackage on bioconductor has some nice functions for this. – Hollydate1[i1]>date1[i2] && date1[i1]<date2[i2]and the same fordate2[i1]. Then the both rows are combined. Thedate1anddate2are set tominof bothdate1anddate2, respectively. Your question to >2 overlapping intervals: ERI is such a case. Do you want four new rows (ER, EI, RI, and ERI) and one new row (ERI)? The latter might yield some conflicts. I would solve it with some recursive function call ... . – Finn