How can I find the p-value (significance) of each coefficient?
lm = sklearn.linear_model.LinearRegression()
lm.fit(x,y)
How can I find the p-value (significance) of each coefficient?
lm = sklearn.linear_model.LinearRegression()
lm.fit(x,y)
This is kind of overkill but let's give it a go. First lets use statsmodel to find out what the p-values should be
import pandas as pd
import numpy as np
from sklearn import datasets, linear_model
from sklearn.linear_model import LinearRegression
import statsmodels.api as sm
from scipy import stats
diabetes = datasets.load_diabetes()
X = diabetes.data
y = diabetes.target
X2 = sm.add_constant(X)
est = sm.OLS(y, X2)
est2 = est.fit()
print(est2.summary())
and we get
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.518
Model: OLS Adj. R-squared: 0.507
Method: Least Squares F-statistic: 46.27
Date: Wed, 08 Mar 2017 Prob (F-statistic): 3.83e-62
Time: 10:08:24 Log-Likelihood: -2386.0
No. Observations: 442 AIC: 4794.
Df Residuals: 431 BIC: 4839.
Df Model: 10
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 152.1335 2.576 59.061 0.000 147.071 157.196
x1 -10.0122 59.749 -0.168 0.867 -127.448 107.424
x2 -239.8191 61.222 -3.917 0.000 -360.151 -119.488
x3 519.8398 66.534 7.813 0.000 389.069 650.610
x4 324.3904 65.422 4.958 0.000 195.805 452.976
x5 -792.1842 416.684 -1.901 0.058 -1611.169 26.801
x6 476.7458 339.035 1.406 0.160 -189.621 1143.113
x7 101.0446 212.533 0.475 0.635 -316.685 518.774
x8 177.0642 161.476 1.097 0.273 -140.313 494.442
x9 751.2793 171.902 4.370 0.000 413.409 1089.150
x10 67.6254 65.984 1.025 0.306 -62.065 197.316
==============================================================================
Omnibus: 1.506 Durbin-Watson: 2.029
Prob(Omnibus): 0.471 Jarque-Bera (JB): 1.404
Skew: 0.017 Prob(JB): 0.496
Kurtosis: 2.726 Cond. No. 227.
==============================================================================
Ok, let's reproduce this. It is kind of overkill as we are almost reproducing a linear regression analysis using Matrix Algebra. But what the heck.
lm = LinearRegression()
lm.fit(X,y)
params = np.append(lm.intercept_,lm.coef_)
predictions = lm.predict(X)
newX = pd.DataFrame({"Constant":np.ones(len(X))}).join(pd.DataFrame(X))
MSE = (sum((y-predictions)**2))/(len(newX)-len(newX.columns))
# Note if you don't want to use a DataFrame replace the two lines above with
# newX = np.append(np.ones((len(X),1)), X, axis=1)
# MSE = (sum((y-predictions)**2))/(len(newX)-len(newX[0]))
var_b = MSE*(np.linalg.inv(np.dot(newX.T,newX)).diagonal())
sd_b = np.sqrt(var_b)
ts_b = params/ sd_b
p_values =[2*(1-stats.t.cdf(np.abs(i),(len(newX)-len(newX[0])))) for i in ts_b]
sd_b = np.round(sd_b,3)
ts_b = np.round(ts_b,3)
p_values = np.round(p_values,3)
params = np.round(params,4)
myDF3 = pd.DataFrame()
myDF3["Coefficients"],myDF3["Standard Errors"],myDF3["t values"],myDF3["Probabilities"] = [params,sd_b,ts_b,p_values]
print(myDF3)
And this gives us.
Coefficients Standard Errors t values Probabilities
0 152.1335 2.576 59.061 0.000
1 -10.0122 59.749 -0.168 0.867
2 -239.8191 61.222 -3.917 0.000
3 519.8398 66.534 7.813 0.000
4 324.3904 65.422 4.958 0.000
5 -792.1842 416.684 -1.901 0.058
6 476.7458 339.035 1.406 0.160
7 101.0446 212.533 0.475 0.635
8 177.0642 161.476 1.097 0.273
9 751.2793 171.902 4.370 0.000
10 67.6254 65.984 1.025 0.306
So we can reproduce the values from statsmodel.
code np.linalg.inv can sometimes return a result even when the matrix is non-invertable. That might be the issue. –
Tetrapod nans. For me it was because my X's were a sample of my data so the index was off. This causes errors when calling pd.DataFrame.join(). I made this one line change and it seems to work now: newX = pd.DataFrame({"Constant":np.ones(len(X))}).join(pd.DataFrame(X.reset_index(drop=True))) –
Gabrielagabriele len(newX)-len(X[0]) instead of len(newX)-len(newX[0]) –
Overrun p_values =[2*(1-stats.t.cdf(np.abs(i),(len(newX)-len(newX[0])))) for i in ts_b] returns all Nan, and I rewrite the degree of freedom with len(newX) - 1 and get the same p_value as the statsmodels given. But I am not sure whether the df is correct for the case or not. If wrong, a correction to my concept is appreciated. Tks. –
Ashok p_values = [2 * (1 - stats.t.cdf(np.abs(i), (len(newX) - len(newX.columns)))) for i in ts_b] because newX is a dataframe not an array. Same as denominator in the MSE line. DF = N - P as explained here –
Fritter p_values calculation. There should be an absolute value of t statistics 2 * (1 - stats.t.cdf(np.abs(ts_b), (len(newX) - len(newX.columns)))) instead of np.abs(i) (replaced list comprehension with vectorized version). Reference implementation: github.com/bashtage/linearmodels/blob/… –
Wendiewendin scikit-learn's LinearRegression doesn't calculate this information but you can easily extend the class to do it:
from sklearn import linear_model
from scipy import stats
import numpy as np
class LinearRegression(linear_model.LinearRegression):
"""
LinearRegression class after sklearn's, but calculate t-statistics
and p-values for model coefficients (betas).
Additional attributes available after .fit()
are `t` and `p` which are of the shape (y.shape[1], X.shape[1])
which is (n_features, n_coefs)
This class sets the intercept to 0 by default, since usually we include it
in X.
"""
def __init__(self, *args, **kwargs):
if not "fit_intercept" in kwargs:
kwargs['fit_intercept'] = False
super(LinearRegression, self)\
.__init__(*args, **kwargs)
def fit(self, X, y, n_jobs=1):
self = super(LinearRegression, self).fit(X, y, n_jobs)
sse = np.sum((self.predict(X) - y) ** 2, axis=0) / float(X.shape[0] - X.shape[1])
se = np.array([
np.sqrt(np.diagonal(sse[i] * np.linalg.inv(np.dot(X.T, X))))
for i in range(sse.shape[0])
])
self.t = self.coef_ / se
self.p = 2 * (1 - stats.t.cdf(np.abs(self.t), y.shape[0] - X.shape[1]))
return self
Stolen from here.
You should take a look at statsmodels for this kind of statistical analysis in Python.
An easy way to pull of the p-values is to use statsmodels regression:
import statsmodels.api as sm
mod = sm.OLS(Y,X)
fii = mod.fit()
p_values = fii.summary2().tables[1]['P>|t|']
You get a series of p-values that you can manipulate (for example choose the order you want to keep by evaluating each p-value):

The code in elyase's answer https://mcmap.net/q/115792/-find-p-value-significance-in-scikit-learn-linearregression does not actually work. Notice that sse is a scalar, and then it tries to iterate through it. The following code is a modified version. Not amazingly clean, but I think it works more or less.
class LinearRegression(linear_model.LinearRegression):
def __init__(self,*args,**kwargs):
# *args is the list of arguments that might go into the LinearRegression object
# that we don't know about and don't want to have to deal with. Similarly, **kwargs
# is a dictionary of key words and values that might also need to go into the orginal
# LinearRegression object. We put *args and **kwargs so that we don't have to look
# these up and write them down explicitly here. Nice and easy.
if not "fit_intercept" in kwargs:
kwargs['fit_intercept'] = False
super(LinearRegression,self).__init__(*args,**kwargs)
# Adding in t-statistics for the coefficients.
def fit(self,x,y):
# This takes in numpy arrays (not matrices). Also assumes you are leaving out the column
# of constants.
# Not totally sure what 'super' does here and why you redefine self...
self = super(LinearRegression, self).fit(x,y)
n, k = x.shape
yHat = np.matrix(self.predict(x)).T
# Change X and Y into numpy matricies. x also has a column of ones added to it.
x = np.hstack((np.ones((n,1)),np.matrix(x)))
y = np.matrix(y).T
# Degrees of freedom.
df = float(n-k-1)
# Sample variance.
sse = np.sum(np.square(yHat - y),axis=0)
self.sampleVariance = sse/df
# Sample variance for x.
self.sampleVarianceX = x.T*x
# Covariance Matrix = [(s^2)(X'X)^-1]^0.5. (sqrtm = matrix square root. ugly)
self.covarianceMatrix = sc.linalg.sqrtm(self.sampleVariance[0,0]*self.sampleVarianceX.I)
# Standard erros for the difference coefficients: the diagonal elements of the covariance matrix.
self.se = self.covarianceMatrix.diagonal()[1:]
# T statistic for each beta.
self.betasTStat = np.zeros(len(self.se))
for i in xrange(len(self.se)):
self.betasTStat[i] = self.coef_[0,i]/self.se[i]
# P-value for each beta. This is a two sided t-test, since the betas can be
# positive or negative.
self.betasPValue = 1 - t.cdf(abs(self.betasTStat),df)
There could be a mistake in @JARH's answer in the case of a multivariable regression. (I do not have enough reputation to comment.)
In the following line:
p_values =[2*(1-stats.t.cdf(np.abs(i),(len(newX)-1))) for i in ts_b],
the t-values follows a chi-squared distribution of degree len(newX)-1 instead of following a chi-squared distribution of degree len(newX)-len(newX.columns)-1.
So this should be:
p_values =[2*(1-stats.t.cdf(np.abs(i),(len(newX)-len(newX.columns)-1))) for i in ts_b]
(See t-values for OLS regression for more details)
You can use scipy for p-value. This code is from scipy documentation.
>>> from scipy import stats >>> import numpy as np >>> x = np.random.random(10) >>> y = np.random.random(10) >>> slope, intercept, r_value, p_value, std_err = stats.linregress(x,y)
For a one-liner you can use the pingouin.linear_regression function (disclaimer: I am the creator of Pingouin), which works with uni/multi-variate regression using NumPy arrays or Pandas DataFrame, e.g:
import pingouin as pg
# Using a Pandas DataFrame `df`:
lm = pg.linear_regression(df[['x', 'z']], df['y'])
# Using a NumPy array:
lm = pg.linear_regression(X, y)
The output is a dataframe with the beta coefficients, standard errors, T-values, p-values and confidence intervals for each predictor, as well as the R^2 and adjusted R^2 of the fit.
p_value is among f statistics. if you want to get the value, simply use this few lines of code:
import statsmodels.api as sm
from scipy import stats
diabetes = datasets.load_diabetes()
X = diabetes.data
y = diabetes.target
X2 = sm.add_constant(X)
est = sm.OLS(y, X2)
print(est.fit().f_pvalue)
Getting little bit into the theory of linear regression, here is the summary of what we need to compute the p-values for the coefficient estimators (random variables), to check if they are significant (by rejecting the corresponding null hyothesis):

Now, let's compute the p-values using the following code snippets:
import numpy as np
# generate some data
np.random.seed(1)
n = 100
X = np.random.random((n,2))
beta = np.array([-1, 2])
noise = np.random.normal(loc=0, scale=2, size=n)
y = X@beta + noise
Compute p-values from the above formulae with scikit-learn:
# use scikit-learn's linear regression model to obtain the coefficient estimates
from sklearn.linear_model import LinearRegression
reg = LinearRegression().fit(X, y)
beta_hat = [reg.intercept_] + reg.coef_.tolist()
beta_hat
# [0.18444290873001834, -1.5879784718284842, 2.5252138207251904]
# compute the p-values
from scipy.stats import t
# add ones column
X1 = np.column_stack((np.ones(n), X))
# standard deviation of the noise.
sigma_hat = np.sqrt(np.sum(np.square(y - X1@beta_hat)) / (n - X1.shape[1]))
# estimate the covariance matrix for beta
beta_cov = np.linalg.inv(X1.T@X1)
# the t-test statistic for each variable from the formula from above figure
t_vals = beta_hat / (sigma_hat * np.sqrt(np.diagonal(beta_cov)))
# compute 2-sided p-values.
p_vals = t.sf(np.abs(t_vals), n-X1.shape[1])*2
t_vals
# array([ 0.37424023, -2.36373529, 3.57930174])
p_vals
# array([7.09042437e-01, 2.00854025e-02, 5.40073114e-04])
Compute p-values with statsmodels:
import statsmodels.api as sm
X1 = sm.add_constant(X)
model = sm.OLS(y, X2)
model = model.fit()
model.tvalues
# array([ 0.37424023, -2.36373529, 3.57930174])
# compute p-values
t.sf(np.abs(model.tvalues), n-X1.shape[1])*2
# array([7.09042437e-01, 2.00854025e-02, 5.40073114e-04])
model.summary()
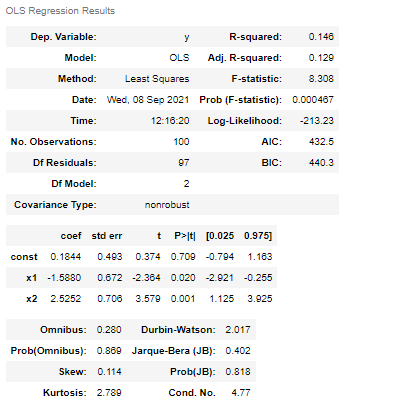
As can be seen from above, the p-values computed in both the cases are exactly same.
beta_cov is negative, so np.sqrt(np.diagonal(beta_cov)) is failing since square root of negative, what should be done in that case? Do you know what could be the reason behind the negative values? –
Eben Another option to those already proposed would be to use permutation testing. Fit the model N times with values of y shuffled and compute the proportion of the coefficients of fitted models that have larger values (one-sided test) or larger absolute values (two-sided test) compared to those given by the original model. These proportions are the p-values.
The purely sklearn solution is to use sklearn.feature_selection.f_regression, which produces p-values for all the features of the predictor vector:
#!/usr/bin/python3.6
import numpy as np
from scipy.stats import linregress
from sklearn.feature_selection import f_regression
# generating data
rng = np.random.default_rng(seed=2023) #initializing random numbers generator
n = 10 #sample size
X = rng.random((n, 2)) #predictor variables
std = 0.5
eps = rng.normal(0., std, n) #noise
Y = 1.6*X[:,0] + eps #response variable
#determine p-values using the scipy solution proposed by @AliMirzaei
p1 = linregress(X[:,0], Y).pvalue
p2 = linregress(X[:,1], Y).pvalue
#determine p-values using sklearn
pp = f_regression(X, Y)[1]
print(p1, p2)
print(pp)
Output:

© 2022 - 2024 — McMap. All rights reserved.