I'm trying to gain some experience with automatic text recognition and i'm using the package tesseract to perform ocr on some images (i.e. some screenshots I took).
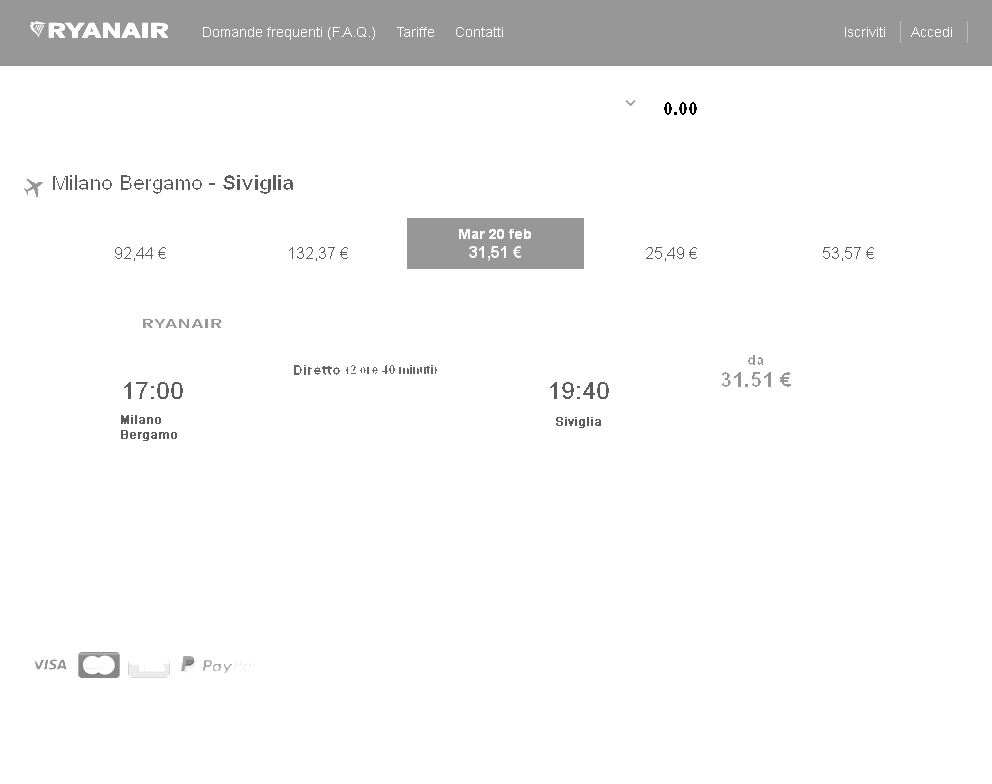
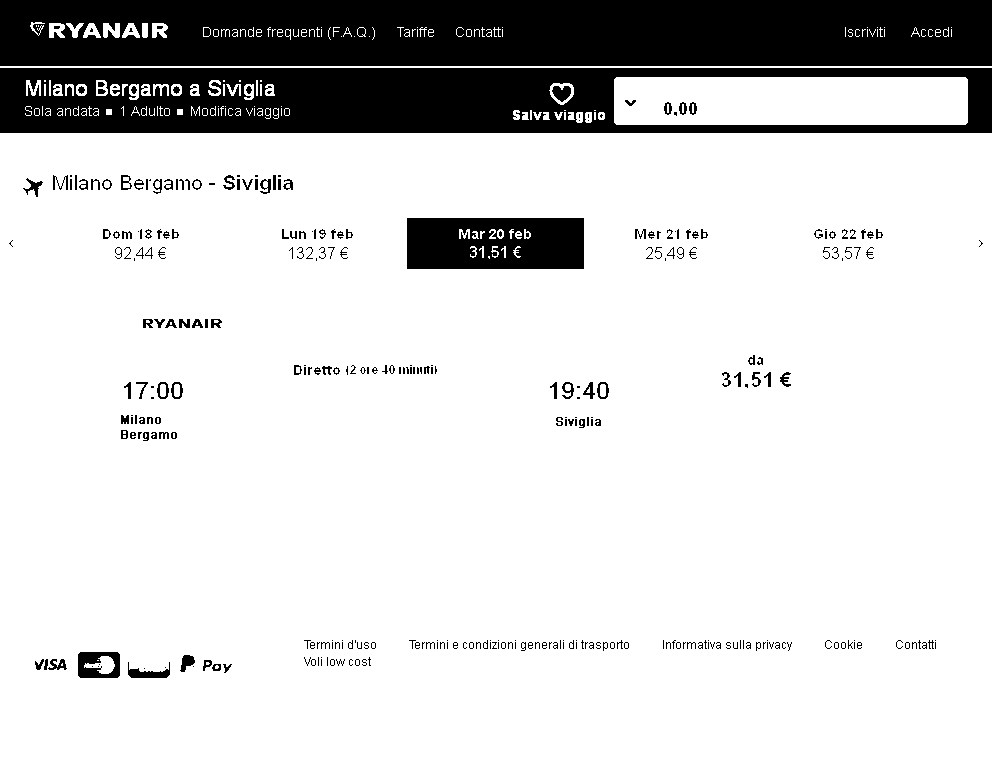
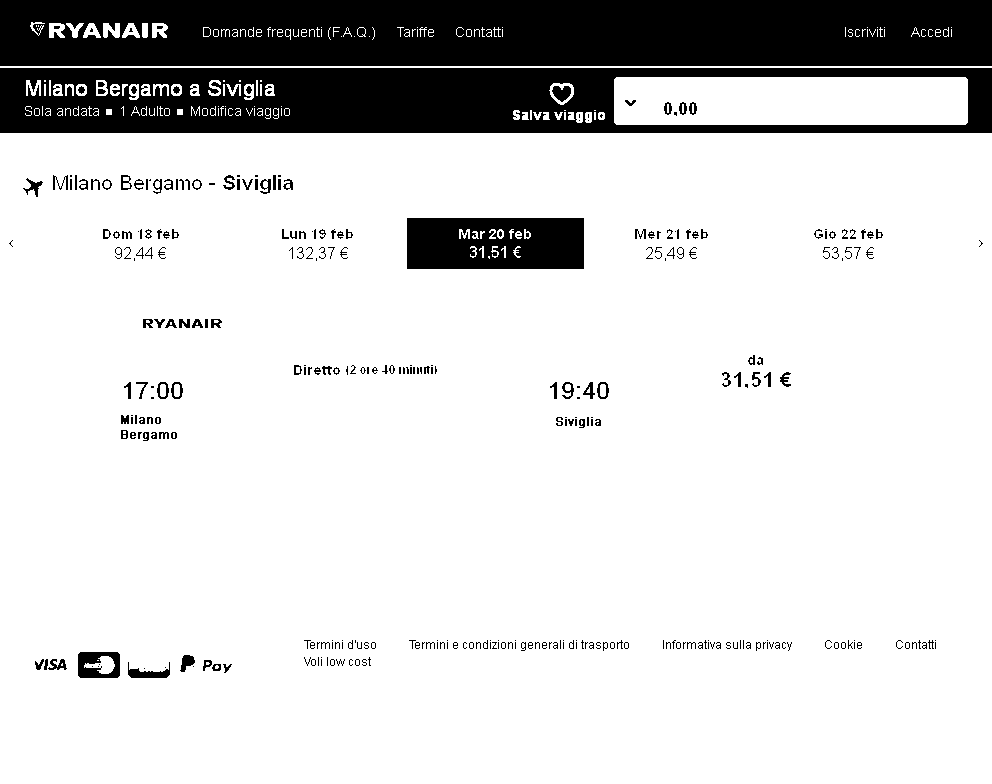
To improve the performance of my program's recognition of the prices in the image below, I implemented some preprocessing on the image using the magick package by increasing the contrast of the image by changing brightness and saturation parameters.
However, I think the performance could be further increased by converting to a black and white image.
How can this be efficiently achieved in R?
Original Image
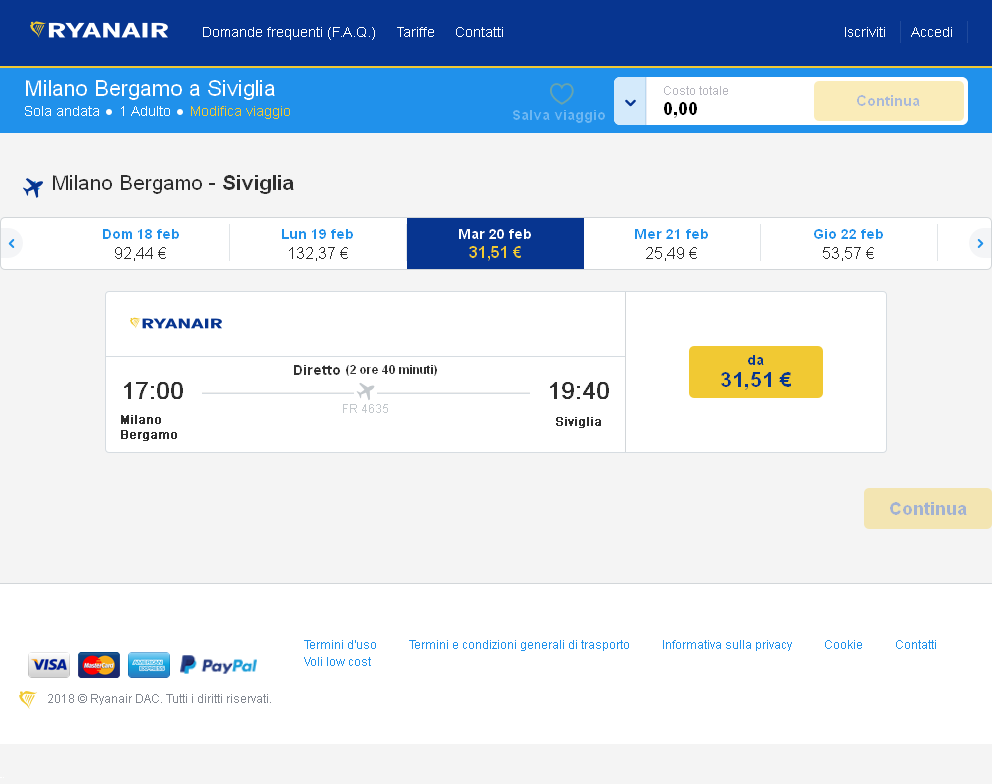
After preprocessing