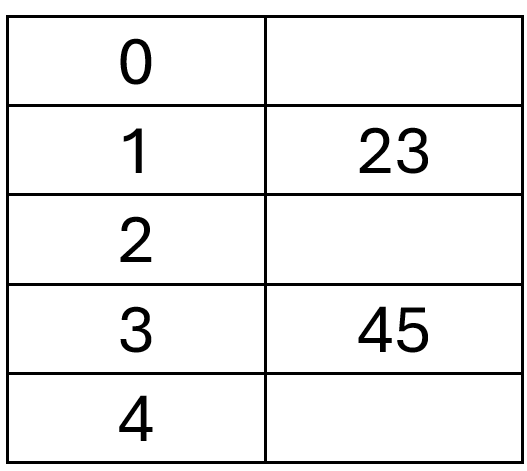
When a deletion happens under linear probing, there is an algorithm which avoids placing tombstones into the array. The algorithm walks all the entries starting with the deleted entry V until the first empty spot (or all the way around the table, if it is full).
Successive entries E are visited. We find the first such E which has a hash code such that when E is retrieved by a lookup operation V has to be traversed to get to E. When we find such an E, we relocate it over top of V. Then we regard E as being the new victim node V and continue at step 1.
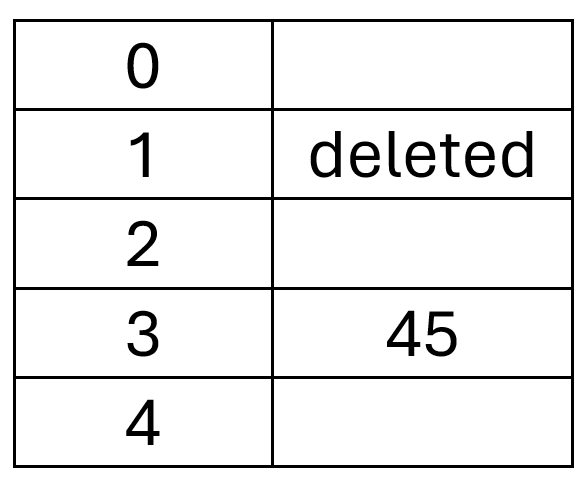
If in (1) we do not find such a node that can be moved over V, it means that all nodes after V are hashed and probed without crossing V. V can therefore be safely obliterated.
A trivial case of 2 occurs when we V is immediately before an empty spot.
A non-trivial case of 2 occurs when the search for E wraps around back to V. That can only happen when the table is full.
For instance, suppose the table is full and perfectly hashed: every entry E is located at (hash(E) mod size(table)), its ideal location. Further suppose that the V we are deleting is the first node at the bottom of the table. For every subsequent entry E, we will find that navigating to that entry does not cross V (since the hashing proceeds directly to that node without any probing), and so we cannot move that entry into the V location. Eventually we visit all of them and wrap back to V. At that point we know that no nodes which follow V in probing order require a traversal of V, and V can be safely obliterated into an empty spot.
The condition in (1) is tricky. This SO answer shows it in Python code, where the xor operator simplifies the condition. If you're working in a language without an xor, I think this might work. Here I'm using the same variable names as that answer:
if (j > i and (k <= i or k > j)) or (j < i and k <= i and k > j):
slot[i] = slot[j]
i = j
The j < i case is the wraparound case; j is searching for what I called the node E, and hit the end of the table, so j is now below i. i is the victim node. k is the hash location of the j node being examined: the place where the table is first probed for j.
{kind=link}
{kind=link}