@RickJames is right, you should not worry about saving space by choosing ASCII or utf8 over utf8mb4.
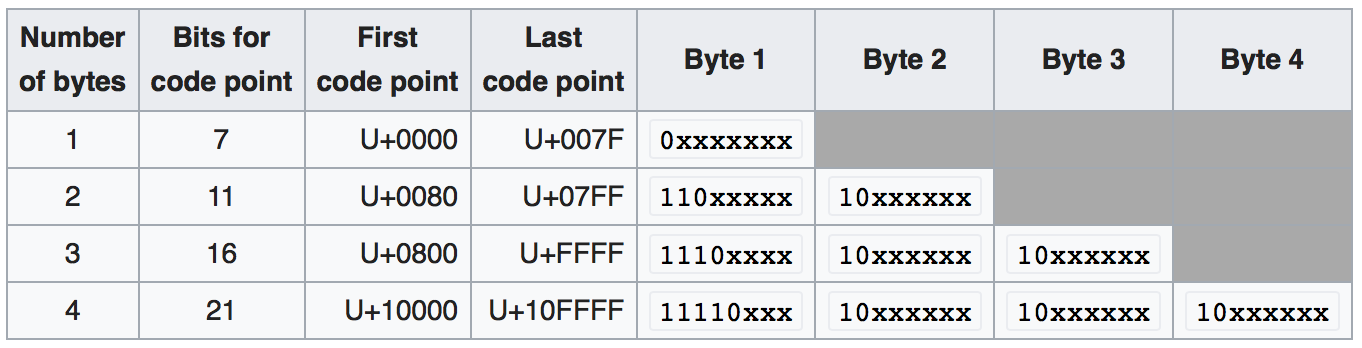
utf8 and utf8mb4 are variable-length character encodings. This table from wikipedia illustrates how characters automatically take 1, 2, 3, or 4 bytes each, depending on the value encoded. If the high bit of a byte is set, then the character uses an additional byte, up to 4 bytes.
![enter image description here]() The wikipedia article explains it clearly:
The wikipedia article explains it clearly:
The first 128 characters (US-ASCII) need one byte. The next 1,920 characters need two bytes to encode, which covers the remainder of almost all Latin-script alphabets, and also Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic, Syriac, Thaana and N'Ko alphabets, as well as Combining Diacritical Marks. Three bytes are needed for characters in the rest of the Basic Multilingual Plane, which contains virtually all characters in common use including most Chinese, Japanese and Korean characters. Four bytes are needed for characters in the other planes of Unicode, which include less common CJK characters, various historic scripts, mathematical symbols, and emoji (pictographic symbols).
You don't have to do anything to choose single-byte versus multi-byte mode. This is just the way the encoding works. Each character automatically uses the number of bytes it needs, and no more.
So there is no advantage to using utf8 over utf8mb4, and no advantage of using ASCII over either, unless you need to restrict the characters allowed in a string.
For what it's worth, the character set MySQL calls "utf8" is an alias for utf8mb3, an implementation of just the first three bytes of the UTF8 encoding. The MySQL server team blog (https://mysqlserverteam.com/mysql-8-0-when-to-use-utf8mb3-over-utf8mb4/) says that utf8mb4 is faster, at least given performance improvements in MySQL 8.0, and utf8mb3 should be considered deprecated. MySQL 8.0.11 release notes say that utf8 will be redefined as an alias for utf8mb4 in some future version of MySQL.