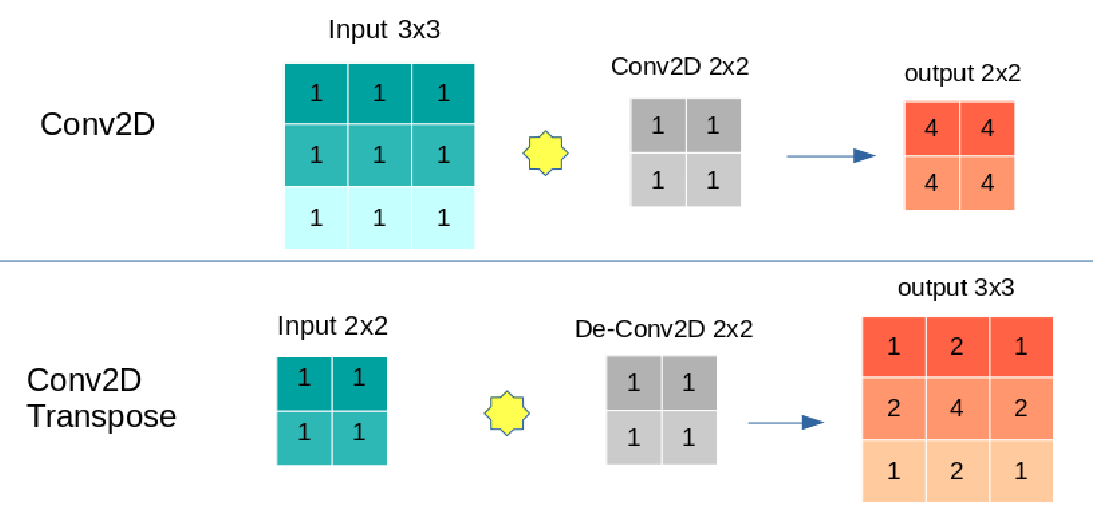
Conv2D applies Convolutional operation on the input. On the contrary, Conv2DTranspose applies a Deconvolutional operation on the input.
Conv2D is mainly used when you want to detect features, e.g., in the encoder part of an autoencoder model, and it may shrink your input shape.- Conversely,
Conv2DTranspose is used for creating features, for example, in the decoder part of an autoencoder model for constructing an image. As you can see in the code below, it makes the input shape larger.
x = tf.random.uniform((1,3,3,1))
conv2d = tf.keras.layers.Conv2D(1,2)(x)
print(conv2d.shape)
# (1, 2, 2, 1)
conv2dTranspose = tf.keras.layers.Conv2DTranspose(1,2)(x)
print(conv2dTranspose.shape)
# (1, 4, 4, 1)
To sum up:
Conv2D:
- May shrink your input
- For detecting features
Conv2DTranspose:
- Enlarges your input
- For constructing features
![enter image description here]()
And if you want to know how Conv2DTranspose enlarges input, here you go:
![enter image description here]()
For example:
kernel = tf.constant_initializer(1.)
x = tf.ones((1,3,3,1))
conv = tf.keras.layers.Conv2D(1,2, kernel_initializer=kernel)
y = tf.ones((1,2,2,1))
de_conv = tf.keras.layers.Conv2DTranspose(1,2, kernel_initializer=kernel)
conv_output = conv(x)
print("Convolution\n---------")
print("input shape:",x.shape)
print("output shape:",conv_output.shape)
print("input tensor:",np.squeeze(x.numpy()).tolist())
print("output tensor:",np.around(np.squeeze(conv_output.numpy())).tolist())
'''
Convolution
---------
input shape: (1, 3, 3, 1)
output shape: (1, 2, 2, 1)
input tensor: [[1.0, 1.0, 1.0], [1.0, 1.0, 1.0], [1.0, 1.0, 1.0]]
output tensor: [[4.0, 4.0], [4.0, 4.0]]
'''
de_conv_output = de_conv(y)
print("De-Convolution\n------------")
print("input shape:",y.shape)
print("output shape:",de_conv_output.shape)
print("input tensor:",np.squeeze(y.numpy()).tolist())
print("output tensor:",np.around(np.squeeze(de_conv_output.numpy())).tolist())
'''
De-Convolution
------------
input shape: (1, 2, 2, 1)
output shape: (1, 3, 3, 1)
input tensor: [[1.0, 1.0], [1.0, 1.0]]
output tensor: [[1.0, 2.0, 1.0], [2.0, 4.0, 2.0], [1.0, 2.0, 1.0]]
'''