I am trying to scrape my messenger.com (facebook messenger) chats using python and i have used google chromes developer tools to see the POST request for the chat history and i have copied the entire header and body into a format that requests can use.
I get HTTP code 200 implying the request at least got something but and i can print res.encoding to get the encoding it returned in which it says is utf-8. But i cannot decode it!
here is the function:
def download_thread(self, limit, offset, message_timestamp):
"""Download the specified number of messages from the
provided thread, with an optional offset
"""
data = request_data(self.thread, offset=offset,
limit=limit, group=self.group,
timestamp=message_timestamp)
res = self.ses.post(url_thread, data=data, headers=headers)
print(res.content)
thread_contents = json.loads(res.content)
print(thread_contents)
return thread_contents
yields
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x87 in position 0: invalid start byte
when it attempts to json.load (or loads) the data
But res.encoding does return utf-8.
I tried unzipping with gzip but that says it is is not gzipped content.
If i just try to do print(res.content) i get
Traceback (most recent call last):
File "FBChatScraper.py", line 200, in <module>
main()
File "FBChatScraper.py", line 134, in main
fbms.run()
0f\x82\x048\xbb\xb9=\x87\xebK0.\xff\x90\xdd\xeb\xfa\x16\xc6\xbbz\x8b\x82)\xe8\xaaV\x01^\xda\x8b\xbd\x15d-\xb1\x10@\x17\\\xd43\xa8\x92w\xe8\xc0\xcdU\xc4\xff\xc7\xfa\x90\xb2\xb3\xf5\x84\x11u\x0b\t\x8f\x83r\xf3}\xe5!y$\xe6\xf6c0\xf0\xb4\x98\xcat_\x0c\x08\xb5\xdd\x8ctx\x91\xa9\x95\rB%\xe2\x93\xa52\x85_\xa6\x10\xc2\xc9\xa3\xee4SDb\xa5\x18QJ\x83X\x19)\xaa$\xf4\xb4\xb7\x0b\x84\x15&\x88\x08L\xc9iP\xa2\xb9\xf2\xaf\x96\x96N\xd8\xcf=\x05\xc1\x18\x8d\xa0\xf2Y\x8e\n\xcf\xc8\x0fE4\xd6)\xa1\xd4\xb7D\xd6{i\xc8P\x96R\x11HC\xac\xbcKyT#~}\x93\xf7@K\xc7r/\x82\xb0\xe4\xefX\xf9j\x08\xa6Hp\xfcn\x06\xfdo\x9a\xd0wJ\xb4fJ(\x89+\x1c\xf6\x0eOI\x90\xac\x9eDD\xfd,\xa5\xe9\x89\x1blh\x86Z\x98\x05\xdd9\xc7\xf4\x80\xfcY\x8e\xad\xee\x99!\x15\x13+\x9b\x07\xe8Fdj\xfc\x11\xfc\xfe7\x06h\x02\x00@>]W\x92\xc9\x02\xb1c3\x82\xcd\xa4\xefN9\x90\xe6\x81y\x9c\x84er\xd4\xc3\x06\x1c\x06\x14\xcf\xc7\x07hj\xbfH\xdc\xf5~\xf7z\x18Ce\xaf^\x8c\xab \xdfV\xce\xb8\x11\xf8\x06\x03'
Traceback (most recent call last):
File "FBChatScraper.py", line 200, in <module>
main()
File "FBChatScraper.py", line 134, in main
fbms.run()
File "FBChatScraper.py", line 43, in run
thread_contents = self.download_thread(limit, offset, message_timestamp)
File "FBChatScraper.py", line 74, in download_thread
thread_contents = json.loads(res.content)
File "/Users/silman/anaconda/lib/python3.6/json/__init__.py", line 349, in loads
s = s.decode(detect_encoding(s), 'surrogatepass')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x87 in position 0: invalid start byte
oddly printing the content in the middle of the traceback leading me to think there are some invisible characters pushing it down.
I am unable to get the response loaded into a json format because no matter how i handle the response content it isn't properly formatted for json library to interpret.
Moreover if i just do print(res.text) i get garbage:
Traceback (most recent call last):
File "FBChatScraper.py", line 200, in <module>
main()
File "FBChatScraper.py", line 134, in main
fbms.run()
}sP���c���f�u0���\� QZed�C��� M$x�Ҹ�H�����eǘ�]���5���^�*�ӄaM�Y��b���/ڶ�JW/���>H6z�\��l4����t=i��%Ҳu�x��%�x�
F <���{1i�#%;�rɲ=Rχm��1B�Z(+�(S-���#��\v�{b��
� f/V�i̴��_��83� �_����*��O��
������Z��i-�TVeaG54�!v�a?ǯ|gu-g��.���"J$�L`&�tΊ#s)�H����s���q���^0��[)���j�ॽ�T���U���J�ЁwW���!eg�#j ��r��$y���3�4��4.��M�@Kb�AX�SDb�QJ�X)�,���a� "Sp�h�����sOA0Vé|�������:%�rKdKC���@ M��.�^
� �g���SWQHӳ.��BӄG�,����@E��������
nras��L�/��ch@>]W���c3�ͤ�N9��y��er����hj�H��~�zCe�^�� �Vθ�
Traceback (most recent call last):
File "FBChatScraper.py", line 200, in <module>
main()
File "FBChatScraper.py", line 134, in main
fbms.run()
File "FBChatScraper.py", line 43, in run
thread_contents = self.download_thread(limit, offset, message_timestamp)
File "FBChatScraper.py", line 74, in download_thread
thread_contents = json.loads(res.content)
File "/Users/silman/anaconda/lib/python3.6/json/__init__.py", line 349, in loads
s = s.decode(detect_encoding(s), 'surrogatepass')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x87 in position 0: invalid start byte
EDIT:
MWE as best i can, not sure what data from my post request is private so i left some out
using this data
url_thread = "https://www.messenger.com/api/graphqlbatch/"
request_data = {
"batch_name": "MessengerGraphQLThreadFetcher",
"__user": "<user_id>",
"__a": "1",
"__dyn": "<dyn>",
"__req": "9",
'__be' : '-1',
'__pc' : 'PHASED:messengerdotcom_pkg',
"fb_dtsg": "AQFni7TU2nes:AQGSC8FSDqyw",
"ttstamp": "265817254666710077746711957586581715370521181008510710777",
"__rev": "3791607",
"jazoest": "<jazoest>",
"queries": '<queries>'
}
headers = {
"authority": "www.messenger.com",
"method": "POST",
"path": "/api/graphqlbatch/",
"scheme": "https",
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-US,en;q=0.9",
"cache-control": "no-cache",
"content-length": "754",
"content-type" : "application/x-www-form-urlencoded",
"cookie": "<cookies>",
"origin": "https://www.messenger.com",
"pragma": "no-cache",
"referer": "https://www.messenger.com/t/<chatID>",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
}
You can get all the <items> by using chrome developer tools and lookng on the network tab for a POST request to Request URL: https://www.messenger.com/api/graphqlbatch/.
Its easy to find if you scroll up to reload old messages while chrome dev tools is recording.
Then put together a simple request with python
import requests as rq
import time
ses = rq.Session()
thread = <ID of thread found in URL of messenger.com>
conversation_type = <'thread_fbids' if group chat else 'user_ids'>
data = request_data
data['messages[{}][{}][offset]'.format(conversation_type, thread)] = 0
data['messages[{}][{}][timestamp]'.format(conversation_type, thread)] = int(time.time())
data['messages[{}][{}][limit]'.format(conversation_type, thread)] = 2000
res = ses.post(url_thread, data=data, headers=headers)
print(res.content)
thread_contents = json.loads(res.content)
print(thread_contents)
As what my dev tools got back you can see the start of the json here
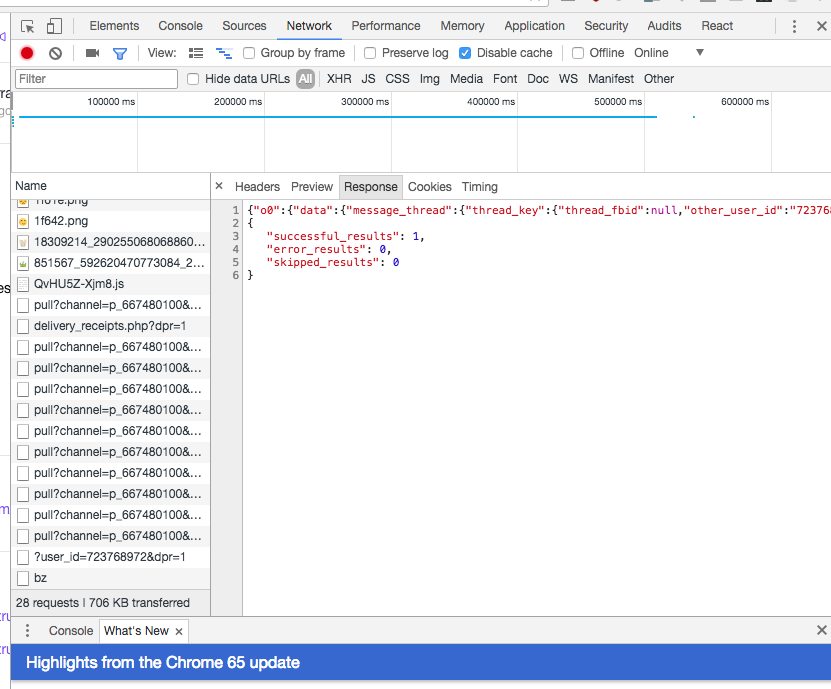{kind=link}
"accept-encoding": "gzip, deflate, br". Is it returning brotli-compressed data? Test just removingbrfrom that line. – Oroscoprint(res.encoding)' it clearly printsutf-8` – Magnanimitypip install brotliand try to decompress manually, but easier to just not accept it in the first place and get back gzip, which you can already handle. – Oroscojson.decoder.JSONDecodeError: Extra data: line 2 column 1 (char 34280)but that is a separate issue. – Magnanimityaccept-encoding, the client just advertises all the compression standards it understand; the order doesn't matter, the server just decides which one (if any) to use for its own reasons. The idea is that it can do intelligent load balancing between CPU use vs. bandwidth savings—compresstakes less CPU thangzipbut doesn't compress as well, and of course no compression takes even less CPU but even more bandwidth. – Orosco