This isn't really a programming question, is there a command line or Windows tool (Windows 7) to get the current encoding of a text file? Sure I can write a little C# app but I wanted to know if there is something already built in?
Get encoding of a file in Windows
You can use a free utility called Encoding Recognizer (requires java). You can find it at mindprod.com/products2.html#ENCODINGRECOGNISER –
Ferment
Guess encoding of a file in Windows is what the title should be. If you don't know in advance, you'll never be able to guess for certain. –
Tiffin
@TomBlodget Your comment makes sense. Then how do the below answers work? Are they just guessing? –
Croydon
Open up your file using regular old vanilla Notepad that comes with Windows 7.
It will show you the encoding of the file when you click "Save As...".
It'll look like this:

Whatever the default-selected encoding is, that is what your current encoding is for the file.
If it is UTF-8, you can change it to ANSI and click save to change the encoding (or visa-versa).
There are many different types of encodings, but this was all I needed when our export files were in UTF-8 and the 3rd party required ANSI. It was a onetime export, so Notepad fit the bill for me.
FYI: From my understanding I think "Unicode" (as listed in Notepad) is a misnomer for UTF-16.
More here on Notepad's "Unicode" option: Windows 7 - UTF-8 and Unicode
Update (06/14/2023):
Updated with screenshots of the newer Notepad and Notepad++
Notepad (Windows 10 & 11):
Bottom-Right Corner: 
"Save As..." Dialog Box: 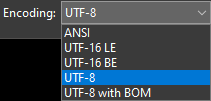
Notepad++:
Bottom-Right Corner: 
"Encoding" Menu Item: 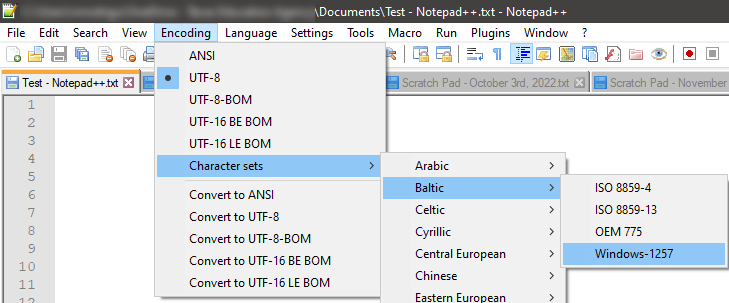
Far more Encoding options are available in NotePad++; should you need them.
Other (Mac/Linux/Win) Options:
I hear Windows 11 improved the performance of large 100+MB files to open much faster.
On the web I've read that Notepad++ is still the all around large-file editor champion.
However, (for those on Mac or Linux) here are some other contenders I found:
1). Sublime Text
2). Visual Studio Code
there is no notepad on windows 8 and editor (which seems to be the replacement) does not have this functionality –
Skillful
@Alex, I do not use Win-8. Performing a google search, I found this link: Win-8 Notepad. I hope you find it because I assure you, it's still there. –
Dinghy
Thanks but on Windows 8.1 there is definitely no app called notepad. When you enter notepad in the search, "editor" appears. And this does not have that endoding dropdown and no menu for it either –
Skillful
This method does not work for files that are too large for Notepad to open. And that limit is reached much faster than other editors like Notepad++. My Windows 8.1 does have Notepad. Look in %windir%\system32\notepad.exe maybe? –
Macromolecule
Notepad, as distributed with Windows systems, will crash on files over 64k. If I were to trust the encoding listed in "Save as", then I'll need to trust that this 64.1k file is completely blank. Unreliable. Just look at that list in your image example: it doesn't even list the only encoding that Windows uses as default, CP1252!!! So unreliable. –
Glockenspiel
Notepad exists in Windows 8 and Windows 10. –
Lacker
Read this article if you are curious about all these: joelonsoftware.com/2003/10/08/… –
Inequity
Notepad is installed in ALL versions of Windows since Windows 3 at least. –
Octameter
In windows 10, its shortcut is in "Windows Accessories". To avoid searching for the shortcut, simply press Windows+R then type notepad. And Notepad definitely works on files of all sizes, albeit slowly on files larger than 100MB. I've used it today to review 3MB log files. –
Octameter
I just used this to identify encoding on a 7MB text file in Windows 8.1. This is a good solution and the drawbacks mentioned in comments don't seem to apply in the real world. –
Tiliaceous
@Glockenspiel Notepad is not for big files usage, but it does have the ability to open files larger than 64KB at least since XP. Only the version in Windows 98 and previous support a maximum of 64KB –
Conjure
One option is to download Notepad++. It is a very powerful free notepad and works as it was explained by @Dinghy –
Soap
Anyone knows how does Notepad's "ANSI" encoding map to CRAN's R read_delim() function encoding types? –
Dextro
@Skillful In the bottom right of the editor you also see the encoding. –
Dactylo
If you have "git" or "Cygwin" on your Windows Machine, then go to the folder where your file is present and execute the command:
file *
This will give you the encoding details of all the files in that folder.
adding to your answer, If you only interested in specific file, you can use grep command to filter the results of
file * command –
Part Instead of just blindly running file command, the full command that answers this question is
file --mime-encoding to get the encoding for the file –
Decern In 2020, the question is not cygwin anymore, it is wsl or wsl2. Cygwin is nearly dead. –
Dendro
In 2021, this works in git-bash (aka the shell that ships with "Git for Windows"). It uses MinGW, not Cygwin. –
Overabundance
The (Linux) command-line tool 'file' is available on Windows via GnuWin32:
http://gnuwin32.sourceforge.net/packages/file.htm
If you have git installed, it's located in C:\Program Files\git\usr\bin.
Example:
C:\Users\SH\Downloads\SquareRoot>file *
_UpgradeReport_Files; directory
Debug; directory
duration.h; ASCII C++ program text, with CRLF line terminators
ipch; directory
main.cpp; ASCII C program text, with CRLF line terminators
Precision.txt; ASCII text, with CRLF line terminators
Release; directory
Speed.txt; ASCII text, with CRLF line terminators
SquareRoot.sdf; data
SquareRoot.sln; UTF-8 Unicode (with BOM) text, with CRLF line terminators
SquareRoot.sln.docstates.suo; PCX ver. 2.5 image data
SquareRoot.suo; CDF V2 Document, corrupt: Cannot read summary info
SquareRoot.vcproj; XML document text
SquareRoot.vcxproj; XML document text
SquareRoot.vcxproj.filters; XML document text
SquareRoot.vcxproj.user; XML document text
squarerootmethods.h; ASCII C program text, with CRLF line terminators
UpgradeLog.XML; XML document text
C:\Users\SH\Downloads\SquareRoot>file --mime-encoding *
_UpgradeReport_Files; binary
Debug; binary
duration.h; us-ascii
ipch; binary
main.cpp; us-ascii
Precision.txt; us-ascii
Release; binary
Speed.txt; us-ascii
SquareRoot.sdf; binary
SquareRoot.sln; utf-8
SquareRoot.sln.docstates.suo; binary
SquareRoot.suo; CDF V2 Document, corrupt: Cannot read summary infobinary
SquareRoot.vcproj; us-ascii
SquareRoot.vcxproj; utf-8
SquareRoot.vcxproj.filters; utf-8
SquareRoot.vcxproj.user; utf-8
squarerootmethods.h; us-ascii
UpgradeLog.XML; us-ascii
note that you probably need git 2.x for it, I don't have it with git 1.9.5 –
Octangle
For my file it says "binary" :( –
Leigha
Unbelievable to have to revert to command line for basic operation, this is 2017, but it looks to do ok. –
Wileywilfong
Like the other answer says, you can also use the
file command in cygwin. Any POSIX toolset for Windows should have file. –
Sharrisharron If you installed git for windows, it includes GIT BASH (bash emulator), which in turn includes the 'file' command. Just used it and it works. It's mentioned also in the next answer... –
Farthing
In windows if file name have space how can I deal with it? –
View
tjorchrt: Put (double or single) quotes around it. –
Dottie
Install git ( on Windows you have to use git bash console). Type:
file --mime-encoding *
for all files in the current directory , or
file --mime-encoding */*
for the files in all subdirectories
Documentation link: linux.die.net/man/1/file –
Zonked
Nice answer. However,
file --mime-encoding */* will miss all files in */*/*. So you also need to run file --mime-encoding */*/*, and so on, if you want to catch all files in the whole subdirectory tree. –
Yogh Another tool that I found useful: [https://codeplexarchive.org/project/EncodingCheckerEXE] can be found here
Really helpful to analyse multiple files –
Deafmute
Instant answer even with very large files (as one would expect). –
Macromolecule
Works on current Windows 10. –
Leigha
can't figure out where the exe file is on that page. Is the link outdated? –
Eta
same. Cant find exe –
Ivo
@MarkDeven Yeah. there is no EXE but if you have visual studio you can compile SLN file to create EXE. let me know if that doesn't work for you –
Aggie
@MarkDeven I have added path to exe in answer –
Aggie
https://github.com/amrali-eg/EncodingChecker there is a modified version. –
Sealer
Yes, the github now host the latest version of this application. –
Underlaid
Here's my take how to detect the Unicode family of text encodings via BOM. The accuracy of this method is low, as this method only works on text files (specifically Unicode files), and defaults to ascii when no BOM is present (like most text editors, the default would be UTF8 if you want to match the HTTP/web ecosystem).
Update 2018: I no longer recommend this method. I recommend using file.exe from GIT or *nix tools as recommended by @Sybren, and I show how to do that via PowerShell in a later answer.
# from https://gist.github.com/zommarin/1480974
function Get-FileEncoding($Path) {
$bytes = [byte[]](Get-Content $Path -Encoding byte -ReadCount 4 -TotalCount 4)
if(!$bytes) { return 'utf8' }
switch -regex ('{0:x2}{1:x2}{2:x2}{3:x2}' -f $bytes[0],$bytes[1],$bytes[2],$bytes[3]) {
'^efbbbf' { return 'utf8' }
'^2b2f76' { return 'utf7' }
'^fffe' { return 'unicode' }
'^feff' { return 'bigendianunicode' }
'^0000feff' { return 'utf32' }
default { return 'ascii' }
}
}
dir ~\Documents\WindowsPowershell -File |
select Name,@{Name='Encoding';Expression={Get-FileEncoding $_.FullName}} |
ft -AutoSize
Recommendation: This can work reasonably well if the dir, ls, or Get-ChildItem only checks known text files, and when you're only looking for "bad encodings" from a known list of tools. (i.e. SQL Management Studio defaults to UTF16, which broke GIT auto-cr-lf for Windows, which was the default for many years.)
There are many variations of
Get-FileEncoding on poshcode. I've even reviewed punycode from python and nodejs, but this small version hits 80/20 for my usage (more like 99/1). If you're hosting other people's files I suggest you use file command from Syben's answer (https://mcmap.net/q/11236/-get-encoding-of-a-file-in-windows) or another production-quality unicode decoder. –
Trip It should be added that this method works only if the BOM is present... which is not always the case –
Rosaliarosalie
@Rosaliarosalie The last line is
default encoding (when no BOM). For XML, JSON, and JavaScript the default is UTF8, but your mileage may vary. –
Trip @yzorg: but that's a brain dead way to do it. You're just lying to the user. At least most parsers make an educated guess. If you can't make a guess just throw an error and tell them a BOM is required to use your code (and then go use another, smarter tool as many already exist). –
Coniah
@EdS. Sure, but seems impossible to know for sure. I am the user when this code is run, so it is optimized for my use case (git hooks, or other scenarios where encodings break devops tools). –
Trip
Sure, it is impossible to know for sure, but you can make an educated guess via heuristics. I get that this is your code, but once it hits e.g. SO for public consumption it's open to criticism. –
Coniah
@EdS. It's said in answer #2 and in comments of answer #1 that if you're looking for an "authoritative" encoding or file type to use
file.exe from cygwin or GIT tools. I also mention it in my response to other comments. I follow that advice, see a later answer (also by me) https://mcmap.net/q/11236/-get-encoding-of-a-file-in-windows for tips on using file.exe from powershell. Would you like me to include that qualifier in the body of my answer? –
Trip @yzorg: That's fine, but this is your answer. I commented on this, your answer, which says none of that. You're saying I need to go read other answers and your comments elsewhere to better understand your own? –
Coniah
A simple solution might be opening the file in Firefox.
- Drag and drop the file into firefox
- Press Ctrl+I to open the page info
and the text encoding will appear on the "Page Info" window.
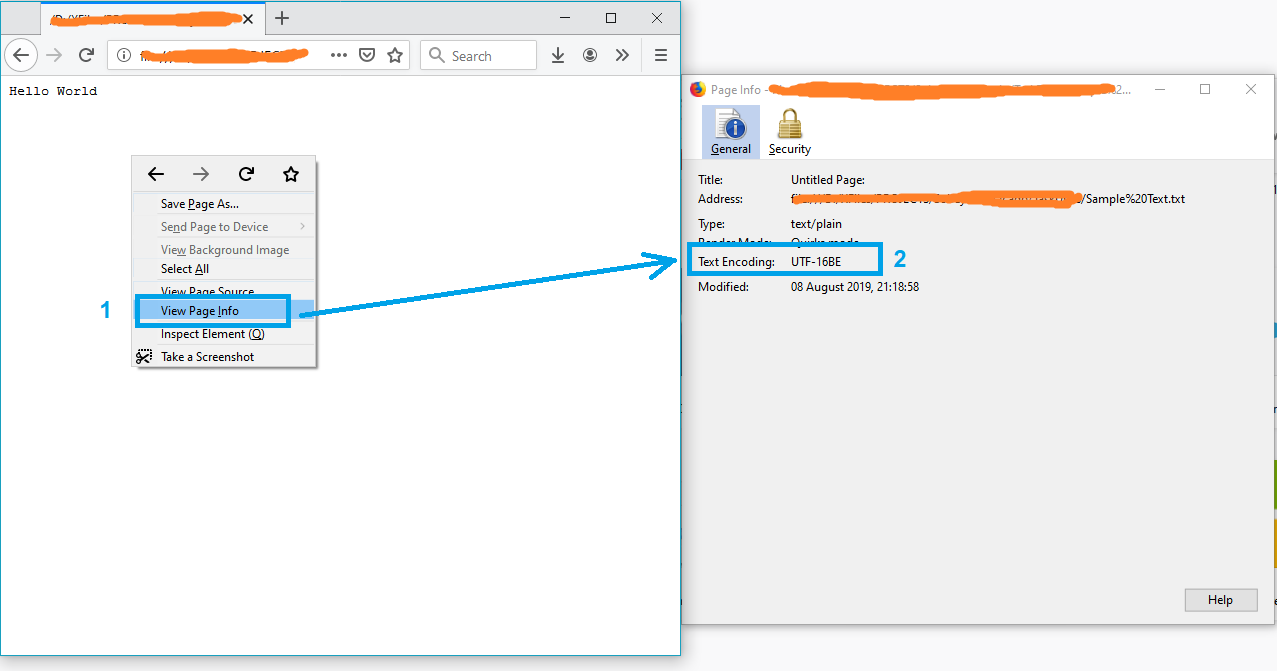
Note: If the file is not in txt format, just rename it to txt and try again.
P.S. For more info see this article.
Looks like
View Page Info is no longer around per Firefox 88 has quietly removed these features from April 2021. CTRL-I (Windows OS on Jan 2022) as a workaround –
Casady I wrote the #4 answer (at time of writing). But lately I have git installed on all my computers, so now I use @Sybren's solution. Here is a new answer that makes that solution handy from powershell (without putting all of git/usr/bin in the PATH, which is too much clutter for me).
Add this to your profile.ps1:
$global:gitbin = 'C:\Program Files\Git\usr\bin'
Set-Alias file.exe $gitbin\file.exe
And used like: file.exe --mime-encoding *. You must include .exe in the command for PS alias to work.
But if you don't customize your PowerShell profile.ps1 I suggest you start with mine: https://gist.github.com/yzorg/8215221/8e38fd722a3dfc526bbe4668d1f3b08eb7c08be0
and save it to ~\Documents\WindowsPowerShell. It's safe to use on a computer without git, but will write warnings when git is not found.
The .exe in the command is also how I use C:\WINDOWS\system32\where.exe from powershell; and many other OS CLI commands that are "hidden by default" by powershell, *shrug*.
or you could just use
file as your alias to file.exe instead of file.exe ¯\_(ツ)_/¯ –
Crosswise @ferrell_io TL;DR: PS is based on .NET and .NET has File static class, and PS has enough confusing overloads with common EXEs that I use .exe to differentiate PS from Win EXE:
dir | where Size -lt 10000 vs where.exe git. –
Trip @ferrell_io I use
where.exe to differentiate it from where in PS, which is a built-in alias for Where-Object. Example: where.exe git* vs ls . | where Size -lt 10000 –
Trip @ferrell_io So I use the same pattern for
file.exe vs .NET static class, which you might need in the same script that is detecting encoding. Example: [File]::SetCreationTime("readme.md", [DateTime]::Now). –
Trip the better way is to add the folder to the
PATH environment variable instead of using alias like this –
Conjure Some C code here for reliable ascii, bom's, and utf8 detection: https://unicodebook.readthedocs.io/guess_encoding.html
Only ASCII, UTF-8 and encodings using a BOM (UTF-7 with BOM, UTF-8 with BOM, UTF-16, and UTF-32) have reliable algorithms to get the encoding of a document. For all other encodings, you have to trust heuristics based on statistics.
EDIT:
A powershell version of a C# answer from: Effective way to find any file's Encoding. Only works with signatures (boms).
# get-encoding.ps1
param([Parameter(ValueFromPipeline=$True)] $filename)
begin {
# set .net current directoy
[Environment]::CurrentDirectory = (pwd).path
}
process {
$reader = [System.IO.StreamReader]::new($filename,
[System.Text.Encoding]::default,$true)
$peek = $reader.Peek()
$encoding = $reader.currentencoding
$reader.close()
[pscustomobject]@{Name=split-path $filename -leaf
BodyName=$encoding.BodyName
EncodingName=$encoding.EncodingName}
}
.\get-encoding chinese8.txt
Name BodyName EncodingName
---- -------- ------------
chinese8.txt utf-8 Unicode (UTF-8)
get-childitem -file | .\get-encoding
@jeasoft Thanks. I added in a fix to set the .net current directory. #11246568 –
Buffum
This doesn't work for
ASCII, UTF-8, UTF-8, UTF-8 BOM, does seem to work with UTF-16, UTF-16 BE though... –
Odo @Odo like I said only works with boms, including utf-8 bom –
Buffum
Interesting, but still not sure how that works... –
Odo
you can simply check that by opening your git bash on the file location then running the command file -i file_name
example
user filesData
$ file -i data.csv
data.csv: text/csv; charset=utf-8
Looking for a Node.js/npm solution? Try encoding-checker:
npm install -g encoding-checker
Usage
Usage: encoding-checker [-p pattern] [-i encoding] [-v]
Options:
--help Show help [boolean]
--version Show version number [boolean]
--pattern, -p, -d [default: "*"]
--ignore-encoding, -i [default: ""]
--verbose, -v [default: false]
Examples
Get encoding of all files in current directory:
encoding-checker
Return encoding of all md files in current directory:
encoding-checker -p "*.md"
Get encoding of all files in current directory and its subfolders (will take quite some time for huge folders; seemingly unresponsive):
encoding-checker -p "**"
For more examples refer to the npm docu or the official repository.
File Encoding Checker is a GUI tool that allows you to validate the text encoding of one or more files. The tool can display the encoding for all selected files, or only the files that do not have the encodings you specify.
File Encoding Checker requires .NET 4 or above to run.
Similar to the solution listed above with Notepad, you can also open the file in Visual Studio, if you're using that. In Visual Studio, you can select "File > Advanced Save Options..."
The "Encoding:" combo box will tell you specifically which encoding is currently being used for the file. It has a lot more text encodings listed in there than Notepad does, so it's useful when dealing with various files from around the world and whatever else.
Just like Notepad, you can also change the encoding from the list of options there, and then saving the file after hitting "OK". You can also select the encoding you want through the "Save with Encoding..." option in the Save As dialog (by clicking the arrow next to the Save button).
Nice but when I try to open the file with Visual Studio, it always open the file in the associated text editor (Notepad++ for this kind of file extension). –
Leigha
@Leigha that'd be something to do with your Visual Studio settings, I'd think. I've been able to access any plain text files of any type in Visual Studio. You've probably told it to just go to Notepad++ whenever it encounters a file with that extension. That's my thoughts, at least. –
Glanti
The only way that I have found to do this is VIM or Notepad++.
Unfortunately they're not "builtin" tools –
Conjure
Using Powershell
After many years of trying to get file encoding from native CMD/Powershell methods, and always having to resort to using (and installing) 3rd party software like Cygwin, git-bash and other external binaries, there is finally a native method.
Before, people go on complaining about all the ways this can fail, please understand that this tool is primarily to be used for identifying Text,Log, CSV and TAB type of files. Not binary files. In addition, the file encoding is mostly a guessing game, so the provided script is making some rudimentary guesses, that will certainly fail on large files. Feel free to test and give improved feedback in the gist.
To test this, I was dumping a bunch of weird garbage text into a string, and then exporting it using the available Windows Encodings.
ASCII, BigEndianUnicode, BigEndianUTF32, OEM, Unicode, UTF7, UTF8, UTF8BOM, UTF8NoBOM, UTF32
# The Garbage
$d=''; (33..126 && 161..252) | ForEach-Object { $c = $([char]$_); $d += ${c} }; $d = "1234 5678 ABCD EFGH`nCRLF: `r`nESC[ :`e[`nESC[m :`e[m`n`r`nASCII [22-126,161-252]:`n$d";
$elist=@('ASCII','BigEndianUnicode','BigEndianUTF32','OEM','Unicode','UTF7','UTF8','UTF8BOM','UTF8NoBOM','UTF32')
$elist | ForEach-Object { $ec=[string]($_); $fp = "zx_$ec.txt"; Write-Host -Fo DarkGray ("Encoding to file: {0}" -f $fp); $d | Out-File -Encoding $ec -FilePath $fp; }
# ls | encguess
ascii zx_ASCII.txt
utf-16 BE zx_BigEndianUnicode.txt
utf-32 BE zx_BigEndianUTF32.txt
OEM (finds) : (3)
OEM 437 ? zx_OEM.txt
utf-16 LE zx_Unicode.txt
utf-32 LE zx_UTF32.txt
utf-7 zx_UTF7.txt
utf-8 zx_UTF8.txt
utf-8 BOM zx_UTF8BOM.txt
utf-8 zx_UTF8NoBOM.txt
Here's is the code and it can also be found in the gist URL.
#!/usr/bin/env pwsh
# GuessFileEncoding.ps1 - Guess File Encoding for Windows-11 using Powershell
# -*- coding: utf-8 -*-
#------------------------------------------------------------------------------
# Author : not2qubit
# Date : 2023-11-27
# Version: : 1.0.0
# License: : CC-BY-SA-4.0
# URL: : https://gist.github.com/eabase/d4f16c8c6535f3868d5dfb1efbde0e5a
#--------------------------------------------------------
# Usage : ls | encguess
# : encguess .\somefile.txt
#--------------------------------------------------------
# References:
#
# [1] https://www.fileformat.info/info/charset/UTF-7/list.htm
# [2] https://learn.microsoft.com/en-gb/windows/win32/intl/code-page-identifiers
# [3] https://learn.microsoft.com/en-us/windows/console/console-virtual-terminal-sequences
# [4] https://gist.github.com/fnky/458719343aabd01cfb17a3a4f7296797
# [5] https://github.com/dankogai/p5-encode/blob/main/lib/Encode/Guess.pm
#
#--------------------------------------------------------
# https://mcmap.net/q/11271/-powershell-binary-grep
Function Find-Bytes([byte[]]$Bytes, [byte[]]$Search, [int]$Start, [Switch]$All) {
For ($Index = $Start; $Index -le $Bytes.Length - $Search.Length ; $Index++) {
For ($i = 0; $i -lt $Search.Length -and $Bytes[$Index + $i] -eq $Search[$i]; $i++) {}
If ($i -ge $Search.Length) {
$Index
If (!$All) { Return }
}
}
}
function get_file_encoding {
param([Parameter(ValueFromPipeline=$True)] $filename)
begin {
# Use .NET to set current directory
[Environment]::CurrentDirectory = (pwd).path
}
process {
function guess_encoding ($bytes) {
# ---------------------------------------------------------------------------------------------------
# Plan: Do the easy checks first!
# 1. scan whole file & check if there are no codes above [1-127] and excess of "?" (0x3f) --> ASCII
# 2. scan whole file & check if there are codes above [1-127] --> ? ANSI/OEM/UTF-8
# 3. scan whole file & check if there are many codes "2b41" & char<127 --> UTF-7 --> "2b2f76" UTF-7 BOM
# 4. scan whole file & check if there are many codes "c2 | c3" --> UTF-8
# ---------------------------------------------------------------------------------------------------
switch -regex ('{0:x2}{1:x2}{2:x2}{3:x2}' -f $bytes[0],$bytes[1],$bytes[2],$bytes[3]) {
# 1. Check UTF-8 BOM
'^efbbbf' { return 'utf-8 BOM' } # UTF-8 BOM (?)
'^2b2f76' { return 'utf-7 BOM' } # UTF-7 BOM (65000)
# 2. Check UTF-32 (BE|LE)
'^fffe0000' { return 'utf-32 LE' } # UTF-32 LE (12000)
'^0000feff' { return 'utf-32 BE' } # UTF-32 BE (12001) 'bigendianutf32'
# 3. Check UTF-16 (BE|LE)
'^fffe' { return 'utf-16 LE' } # UTF-16 LE (1200) 'unicode'
'^feff' { return 'utf-16 BE' } # UTF-16 BE (1201) 'bigendianunicode'
default { return 'unsure' } #
}
}
function guess_again ($blob) {
#-------------------------------
# 1. Check if ASCII [0-127] (7-bit)
#-------------------------------
# (a) Check if using ASCII above 127
$guess_ascii = 1
foreach ($i in $blob) { if ($i -gt 127) { $guess_ascii=0; break; } }
# (b) Check if there are many consecutive "?"s.
# That would indicate having erroneously saved a
# ISO-8859-1 character containing file, as ASCII.
#$b = [byte[]]("????".ToCharArray())
#$n = (Find-Bytes -all $blob $b).Count
#if ($n -gt 4) {}
#-------------------------------
# 2. Check for UTF-7 strings "2b41" (43 65)
#-------------------------------
$b = [byte[]]("+A".ToCharArray())
$finds=(Find-Bytes -all $blob $b).Count
$quart = [math]::Round(($blob.length)*0.05)
#Write-Host -Fo DarkGray " UTF-7 (quart,finds) : (${quart},${finds})"
if ( ($finds -gt 10) -And ($guess_ascii -eq 1) ) {
return 'utf-7'
} elseif ($guess_ascii -eq 1) {
return 'ascii'
}
#-------------------------------
# 3. Check for UTF-8 strings "c2|c3" (194,195)
#-------------------------------
# If > 25% are c2|c3, probably utf-8
$b = [byte[]](0xc2)
$c = [byte[]](0xc3)
$f1=(Find-Bytes -all $blob $b).Count
$f2=(Find-Bytes -all $blob $c).Count
$quart = [math]::Round(($blob.length)*0.25)
$finds = ($f1 + $f2)
if ($finds -gt $quart) { return "utf-8" }
#-------------------------------
# 4. Check for OEM Strings:
#-------------------------------
# Check for "4x" sequences of 'AAAA'(41), 'IIII'(49), 'OOOO'(4f)
$n = 0
#$oemlist = @(65,73,79)
$oemlist = @('A','I','O')
#$b = [byte[]](("$i"*4).ToCharArray())
foreach ($i in $oemlist) {$b = [byte[]](("$i"*4).ToCharArray()); $n += (Find-Bytes -all $blob $b).Count }
#$blob | Group-Object | Select Name, Count | Sort -Top 15 -Descending Count
Write-Host -Fo DarkGray " OEM (finds) : ($n)"
if ($n -ge 3) { return "OEM 437 ?" }
return "unknown"
}
$bytes = [byte[]](Get-Content $filename -AsByteStream -ReadCount 4 -TotalCount 4)
if (!$bytes) {
$guess = 'failed'
} else {
$guess = guess_encoding($bytes)
}
if ($guess -eq 'unsure') {
# 28591 iso-8859-1 Western European (ISO) // Windows-1252
$blob = [byte[]](Get-Content $filename -AsByteStream -ReadCount 0)
$guess = guess_again($blob)
}
$name = $filename.Name
Write-Host -Fo White (" {0,-16}" -f $guess) -Non; Write-Host -Fo DarkYellow "$name"
}
}
Set-Alias encguess get_file_encoding
© 2022 - 2024 — McMap. All rights reserved.