Our database was running 16 GB of ram, 4 vcpu and 60 GB of disk (m4.xlarge aws rds machine) 3 months ago, and it was running fine until, from one moment to another, it started with an increase of the queue depth, along with Read and Write latency. In that case, we rebooted and upgraded our database to a 32 GB of ram, 8 vcpu (m4.2xlarge instance) and the problem disappeared.
Of course that's not sustainable in time but we couldn't find the exact reason. We do know that our traffic, hence the database operations, are increasing, but not duplicating in size for sure.
The thing is, after 3 months, the problem appeared again today with the 32 GB 8 vcpu, and again, as a panic button, we upgraded to 64 gb 16 vcpu. And we also duplicated the disk size to 120 GB just to be sure. The traffic didn't suddenly increase in the moment of the incident, and also, I can ensure that the traffic is not twice heavier than 3 months ago. In this 3 months though, we analyzed the slow query log and improved some queries by adding some indexes.
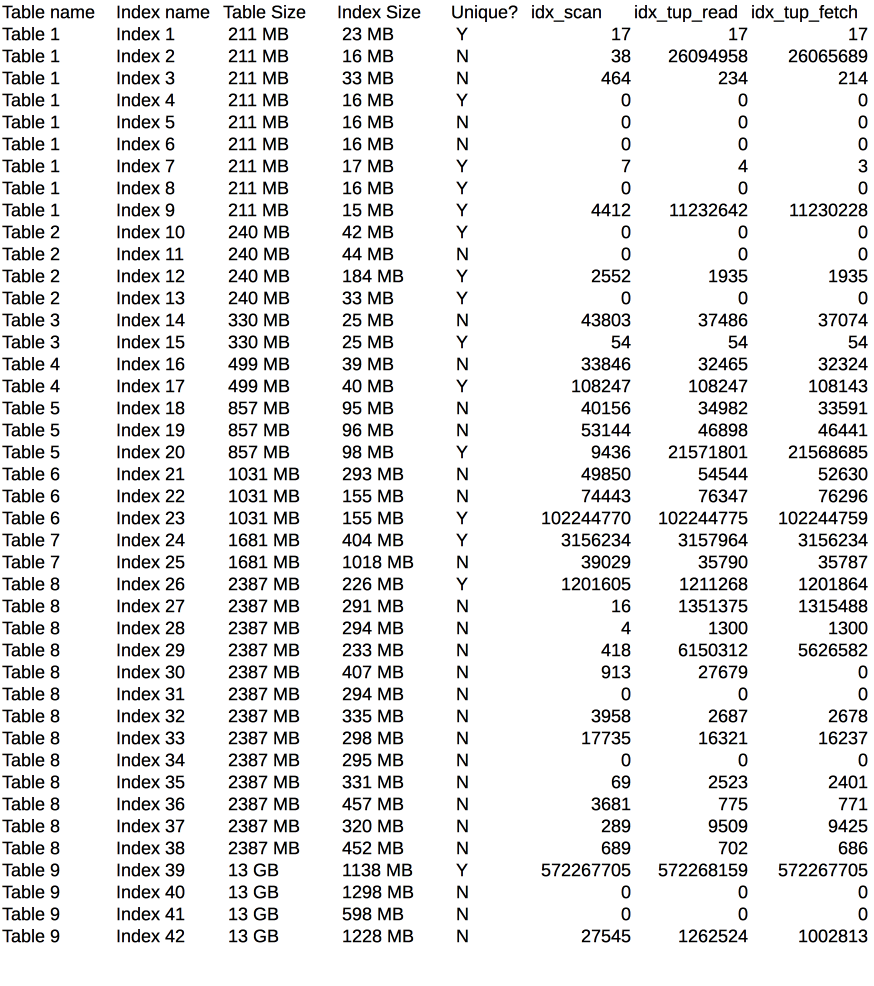
We now have (relevant tables) this tables and indexes
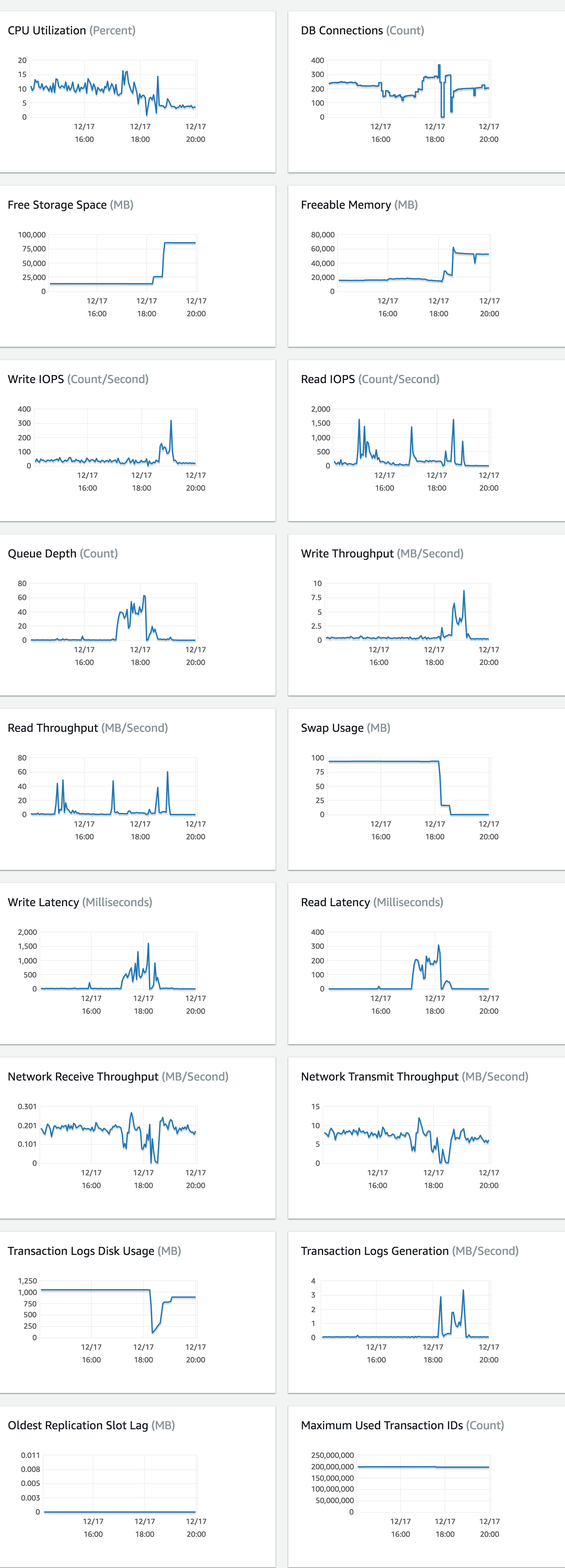
We are not database experts but this doesn't look like the traffic is too heavy for our databases (we are running a ruby on rails e-commerce app). We recognize that "Freeable memory" was always over 20 GB, disk was always over 15 GB. But also, we don't know why it had 100MB of swap usage, if ram was free.
Here are the monitoring charts from aws the last 6 hours, in the middle is the incident, then the scale around 18:15.
total_timeinpg_stat_statements. – Assyriologylog_autovacuum_min_durationto a value other than -1 for an idea on vacuuming activity; see number of seqscans in pg_stat_user_tables too. – Trinitroglycerin