During training this code with ray tune(1 gpu for 1 trial), after few hours
of training (about 20 trials) CUDA out of memory error occurred from GPU:0,1. And even after terminated the training process, the GPUS still give out of memory error.
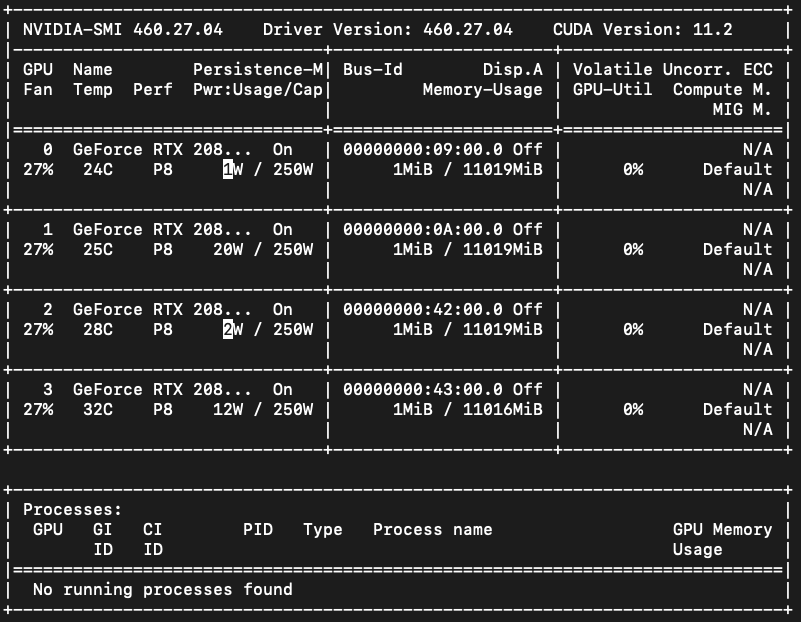
As above, currently, all of my GPU devices are empty. And there is no other python process running except these two.
import torch
torch.rand(1, 2).to('cuda:0') # cuda out of memory error
torch.rand(1, 2).to('cuda:1') # cuda out of memory error
torch.rand(1, 2).to('cuda:2') # working
torch.rand(1, 2).to('cuda:3') # working
torch.cuda.device_count() # 4
torch.cuda.memory_reserved() # 0
torch.cuda.is_available() # True
# error message of GPU 0, 1
RuntimeError: CUDA error: out of memory
However, GPU:0,1 give out of memory errors. If I reboot the computer(ubuntu 18.04.3), it returns to normal, but if I train the code again, the same problem occurs.
How can I debug this problem, or resolve it without rebooting?
- ubuntu 18.04.3
- RTX 2080ti
- CUDA version 10.2
- nvidia driver version: 460.27.04
- cudnn 7.6.4.38
- Python 3.8.4
- pytorch 1.7.0, 1.9.0, 1.9.0+cu111
- cpu: (AMD Ryzen Threadripper 2950X 16-Core Processor)x32
- memory: 125G
- power: 2000W
- dmesg result. (No
GPU has fallen off the buserror)
dmesg | grep -i -e nvidia -e nvrm
[ 5.946174] nvidia: loading out-of-tree module taints kernel.
[ 5.946181] nvidia: module license 'NVIDIA' taints kernel.
[ 5.956595] nvidia: module verification failed: signature and/or required key missing - tainting kernel
[ 5.968280] nvidia-nvlink: Nvlink Core is being initialized, major device number 235
[ 5.970485] nvidia 0000:09:00.0: enabling device (0000 -> 0003)
[ 5.970571] nvidia 0000:09:00.0: vgaarb: changed VGA decodes: olddecodes=io+mem,decodes=none:owns=none
[ 6.015145] nvidia 0000:0a:00.0: enabling device (0000 -> 0003)
[ 6.015394] nvidia 0000:0a:00.0: vgaarb: changed VGA decodes: olddecodes=io+mem,decodes=none:owns=none
[ 6.064993] nvidia 0000:42:00.0: enabling device (0000 -> 0003)
[ 6.065072] nvidia 0000:42:00.0: vgaarb: changed VGA decodes: olddecodes=io+mem,decodes=none:owns=none
[ 6.115778] nvidia 0000:43:00.0: vgaarb: changed VGA decodes: olddecodes=io+mem,decodes=none:owns=io+mem
[ 6.164680] NVRM: loading NVIDIA UNIX x86_64 Kernel Module 460.27.04 Fri Dec 11 23:35:05 UTC 2020
[ 6.174137] nvidia-modeset: Loading NVIDIA Kernel Mode Setting Driver for UNIX platforms 460.27.04 Fri Dec 11 23:24:19 UTC 2020
[ 6.176472] [drm] [nvidia-drm] [GPU ID 0x00000900] Loading driver
[ 6.176567] [drm] Initialized nvidia-drm 0.0.0 20160202 for 0000:09:00.0 on minor 0
[ 6.176635] [drm] [nvidia-drm] [GPU ID 0x00000a00] Loading driver
[ 6.176636] [drm] Initialized nvidia-drm 0.0.0 20160202 for 0000:0a:00.0 on minor 1
[ 6.176709] [drm] [nvidia-drm] [GPU ID 0x00004200] Loading driver
[ 6.176710] [drm] Initialized nvidia-drm 0.0.0 20160202 for 0000:42:00.0 on minor 2
[ 6.176760] [drm] [nvidia-drm] [GPU ID 0x00004300] Loading driver
[ 6.176761] [drm] Initialized nvidia-drm 0.0.0 20160202 for 0000:43:00.0 on minor 3
[ 6.189768] nvidia-uvm: Loaded the UVM driver, major device number 511.
[ 6.744582] input: HDA NVidia HDMI/DP,pcm=3 as /devices/pci0000:40/0000:40:03.1/0000:43:00.1/sound/card4/input12
[ 6.744664] input: HDA NVidia HDMI/DP,pcm=7 as /devices/pci0000:40/0000:40:03.1/0000:43:00.1/sound/card4/input15
[ 6.744755] input: HDA NVidia HDMI/DP,pcm=8 as /devices/pci0000:40/0000:40:03.1/0000:43:00.1/sound/card4/input17
[ 6.744852] input: HDA NVidia HDMI/DP,pcm=9 as /devices/pci0000:40/0000:40:03.1/0000:43:00.1/sound/card4/input19
[ 6.744952] input: HDA NVidia HDMI/DP,pcm=3 as /devices/pci0000:40/0000:40:01.3/0000:42:00.1/sound/card3/input11
[ 6.745301] input: HDA NVidia HDMI/DP,pcm=7 as /devices/pci0000:40/0000:40:01.3/0000:42:00.1/sound/card3/input16
[ 6.745739] input: HDA NVidia HDMI/DP,pcm=8 as /devices/pci0000:40/0000:40:01.3/0000:42:00.1/sound/card3/input18
[ 6.746280] input: HDA NVidia HDMI/DP,pcm=9 as /devices/pci0000:40/0000:40:01.3/0000:42:00.1/sound/card3/input20
[ 7.117377] input: HDA NVidia HDMI/DP,pcm=3 as /devices/pci0000:00/0000:00:01.3/0000:09:00.1/sound/card0/input9
[ 7.117453] input: HDA NVidia HDMI/DP,pcm=7 as /devices/pci0000:00/0000:00:01.3/0000:09:00.1/sound/card0/input10
[ 7.117505] input: HDA NVidia HDMI/DP,pcm=8 as /devices/pci0000:00/0000:00:01.3/0000:09:00.1/sound/card0/input13
[ 7.117559] input: HDA NVidia HDMI/DP,pcm=9 as /devices/pci0000:00/0000:00:01.3/0000:09:00.1/sound/card0/input14
[ 7.117591] input: HDA NVidia HDMI/DP,pcm=3 as /devices/pci0000:00/0000:00:03.1/0000:0a:00.1/sound/card1/input21
[ 7.117650] input: HDA NVidia HDMI/DP,pcm=7 as /devices/pci0000:00/0000:00:03.1/0000:0a:00.1/sound/card1/input22
[ 7.117683] input: HDA NVidia HDMI/DP,pcm=8 as /devices/pci0000:00/0000:00:03.1/0000:0a:00.1/sound/card1/input23
[ 7.117720] input: HDA NVidia HDMI/DP,pcm=9 as /devices/pci0000:00/0000:00:03.1/0000:0a:00.1/sound/card1/input24
[ 9.462521] caller os_map_kernel_space.part.8+0x74/0x90 [nvidia] mapping multiple BARs
- numba and tensorflow have same problem, so it seems like it is not because of pytorch.
>>> from numba import cuda
>>> device = cuda.get_current_device()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/user_name/.pyenv/versions/tensorflow/lib/python3.8/site-packages/numba/cuda/api.py", line 460, in get_current_device
return current_context().device
File "/home/user_name/.pyenv/versions/tensorflow/lib/python3.8/site-packages/numba/cuda/cudadrv/devices.py", line 212, in get_context
return _runtime.get_or_create_context(devnum)
File "/home/user_name/.pyenv/versions/tensorflow/lib/python3.8/site-packages/numba/cuda/cudadrv/devices.py", line 138, in get_or_create_context
return self._get_or_create_context_uncached(devnum)
File "/home/user_name/.pyenv/versions/tensorflow/lib/python3.8/site-packages/numba/cuda/cudadrv/devices.py", line 153, in _get_or_create_context_uncached
return self._activate_context_for(0)
File "/home/user_name/.pyenv/versions/tensorflow/lib/python3.8/site-packages/numba/cuda/cudadrv/devices.py", line 169, in _activate_context_for
newctx = gpu.get_primary_context()
File "/home/user_name/.pyenv/versions/tensorflow/lib/python3.8/site-packages/numba/cuda/cudadrv/driver.py", line 542, in get_primary_context
driver.cuDevicePrimaryCtxRetain(byref(hctx), self.id)
File "/home/user_name/.pyenv/versions/tensorflow/lib/python3.8/site-packages/numba/cuda/cudadrv/driver.py", line 302, in safe_cuda_api_call
self._check_error(fname, retcode)
File "/home/user_name/.pyenv/versions/tensorflow/lib/python3.8/site-packages/numba/cuda/cudadrv/driver.py", line 342, in _check_error
raise CudaAPIError(retcode, msg)
numba.cuda.cudadrv.driver.CudaAPIError: [2] Call to cuDevicePrimaryCtxRetain results in CUDA_ERROR_OUT_OF_MEMORY
update
It seems like it is not happening after rebooting and upgrading pytorch version to 1.9.1+cu111.
update 2
It is occurring again, but I cannot do the suggested commands in the comment section because I don't have root access.
dmesg), do you see any error messages that read in partGPU has fallen off the bus? What's the wattage of the power supply unit in this machine, what CPU does it use, and how much system memory does it have? – Canutenvidia-smishows the maximum CUDA version the installed driver can support. So no red flag in that point. – Canutenvidia-smireports "no running processes found." The specific command for this may vary depending on GPU driver, but try something likesudo rmmod nvidia-uvm nvidia-drm nvidia-modeset nvidia. After that, if you get errors of the form "rmmod: ERROR: Module nvidiaXYZ is not currently loaded", those are not an actual problem and can be ignored. After that, as an ordinary user, runnvidia-smiand then run your tests again. – Priscilapriscillanvida-smi -rfunctionality. – Priscilapriscilla