(See below for update with partially working code.)
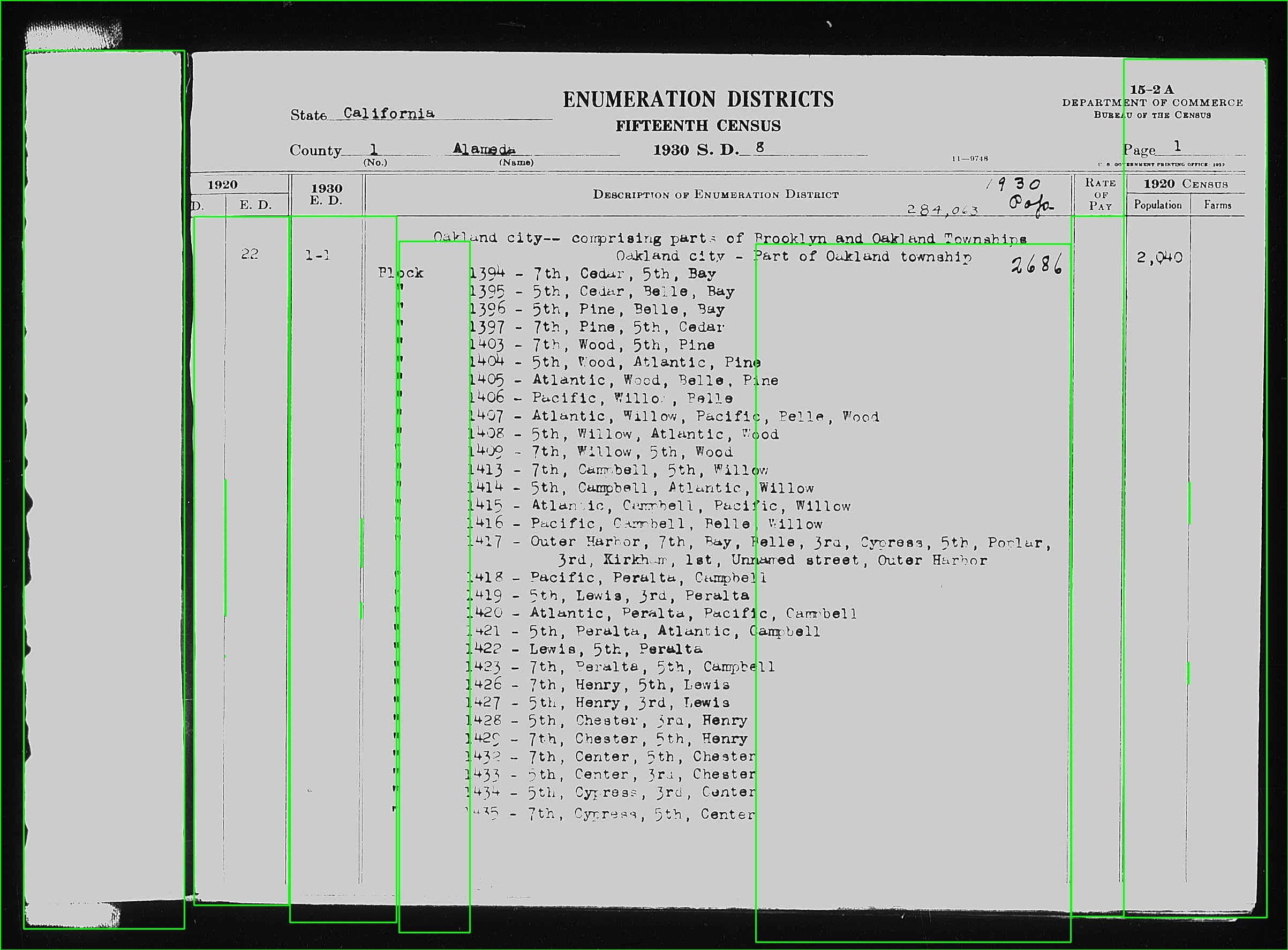
I have thousands of images that look like this:



I need to run an OCR algorithm on the "1930 E.D." column. I find that when I crop the image down to just that column, I get much better results from Tesseract. So I want to identify this long, vertical rectangle automatically and then crop the image and OCR just that bit (with a margin that I'll tweak).
However, the dimensions of the image and the location of the column aren't fixed. There can also be a small bit of rotation in the image which leads the vertical lines to be a few degrees off strictly vertical.
If I were able to reliably identify the long vertical and horizontal lines (and ideally be able to distinguish between single lines and line pairs), then I could easily find the column I need. But the images can be quite poor, so sometimes the lines are interrupted (see third test image). This is the closest I've come, based on this very helpful SO answer:
import cv2
import numpy as np
img = cv2.imread(path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
height, width, channels = img.shape
center_x = width // 2
center_y = height // 2
center_point = (center_x, center_y)
kernel_size = 5
blur_gray = cv2.GaussianBlur(gray, (kernel_size, kernel_size), 0)
low_threshold = 50
high_threshold = 150
edges = cv2.Canny(blur_gray, low_threshold, high_threshold)
rho = 1 # distance resolution in px of Hough grid
theta = np.pi / 180 # angular resolution in rad of Hough grid
threshold = 15 # minimum number of votes (intersections in Hough grid cell)
min_line_length = 50 # minimum number of px making up a line
max_line_gap = 5 # maximum gap in px btw line segments
line_image = np.copy(img) * 0 # creating a blank to draw lines on
lines = cv2.HoughLinesP(
edges,
rho,
theta,
threshold,
np.array([]),
min_line_length,
max_line_gap,
)
for line in lines:
for x1, y1, x2, y2 in line:
cv2.line(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
Which gives me an image like this:
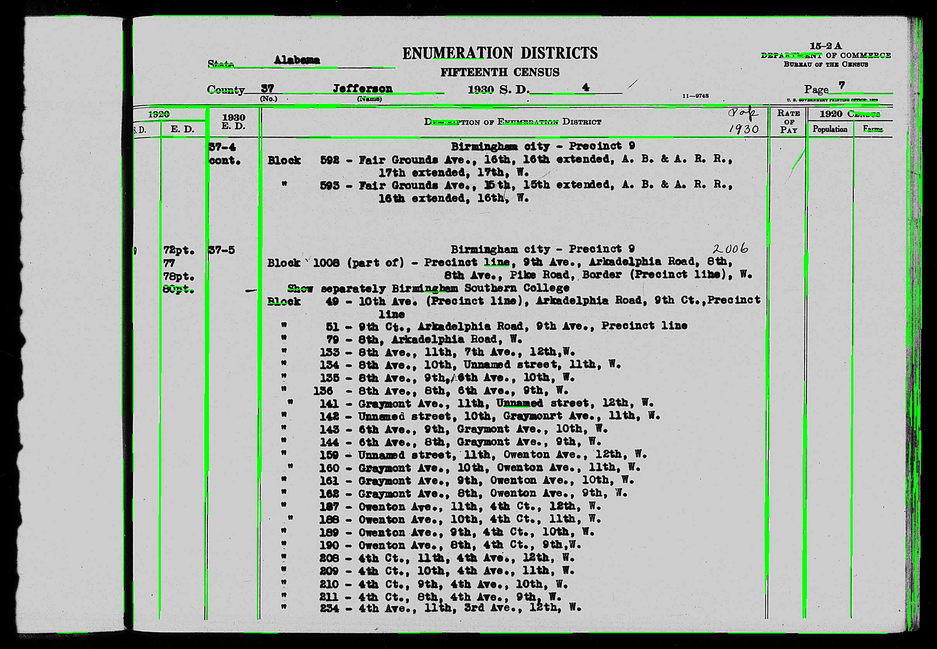
This looks like it could be good enough line discovery. But my question is: how do I group the lines/countours and then determine the coordinates that define the crop rectangle?
Assuming accurate line discovery, a reliable heuristic will be that the rectangle in question will consist of the first two (double) lines to the left of the centerpoint of the image, with the top edge being the first (single) line above the center point. Putting the bottom edge at the end of the image should be fine: the OCR isn't going to identify any text in the black border area. Basically, every image shows the same paper form.
Thanks in advance!
UPDATE: I have tried @fmw42's suggested approach, and have made some progress! Here's the code as of now. Points to note:
- I've used
equalizeHistto improve the contrast. This seems to marginally improve results. - I'm relying on a morphology kernel of 400x30, which selects for tall, narrow boxes.
from pathlib import Path
import cv2
import numpy as np
def find_column(path):
image = cv2.imread(path)
out = cv2.imread(path)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
equal = cv2.equalizeHist(gray)
_, thresh = cv2.threshold(equal, 10, 255, cv2.THRESH_BINARY_INV)
kernel = np.ones((400, 30), np.uint8)
morph = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, kernel)
contours, _ = cv2.findContours(morph, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)
cv2.rectangle(out, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imwrite(Path("/tmp") / path.name, out) # Save
show_img(path.stem, out)
def show_img(self, title, img):
cv2.imshow(title, img)
code = cv2.waitKeyEx(0)
cv2.destroyAllWindows()
if code == 113: # 'q'
sys.exit(0)
That results in this:
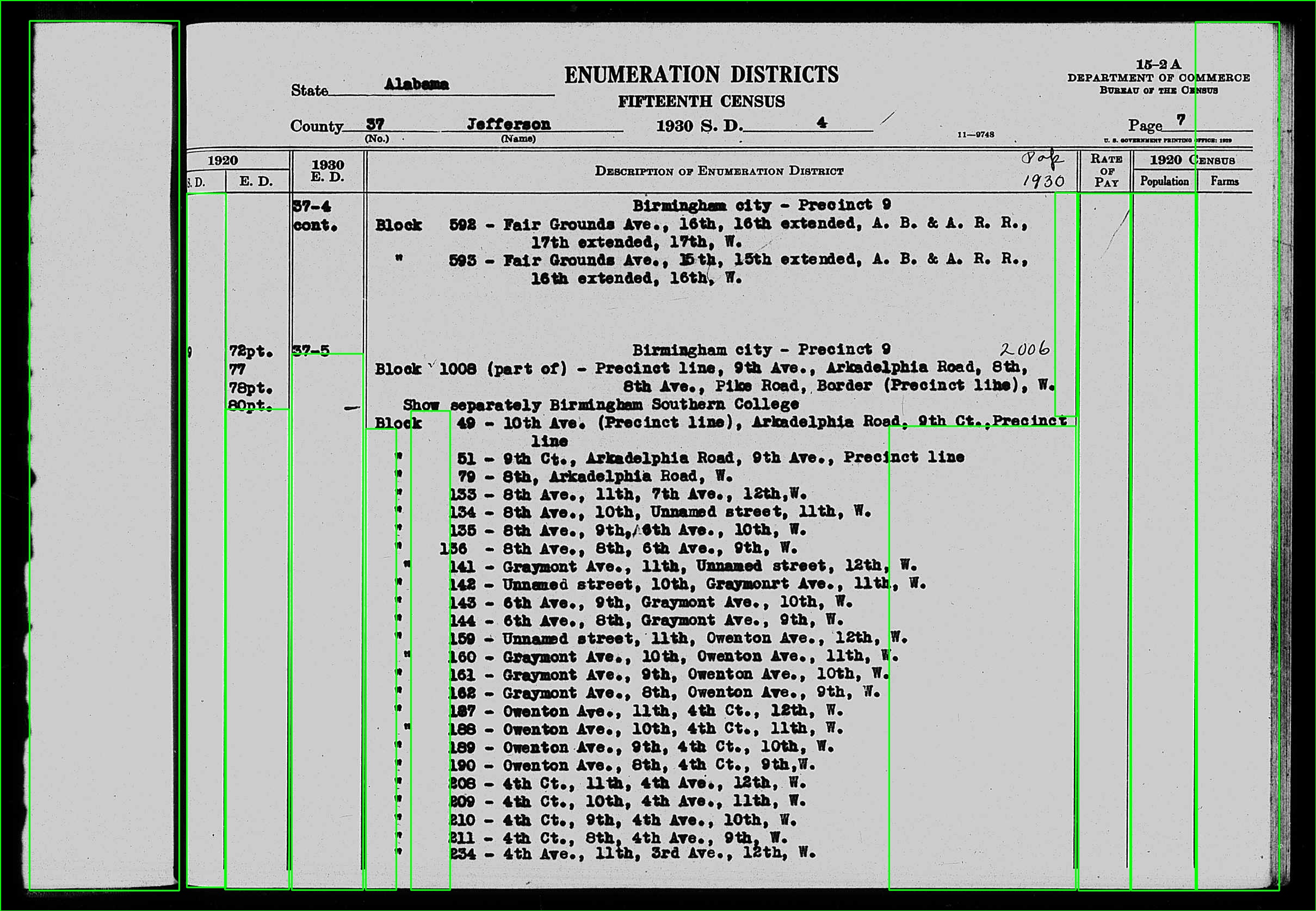
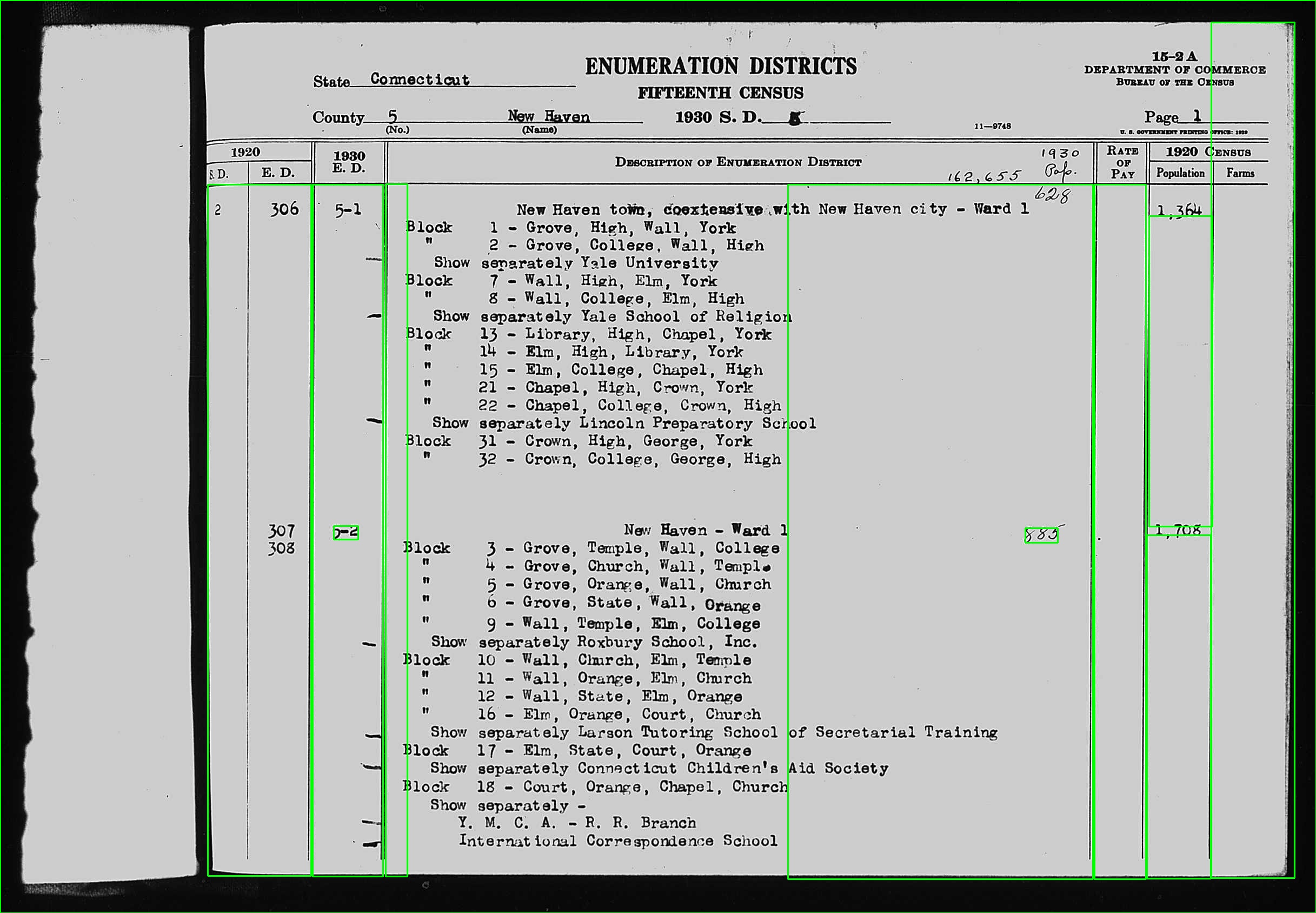

This does work sometimes, and quite well in those cases. But more often, the box still isn't properly aligned or doesn't extend far enough up the column to capture all of the text. Any other suggestions about how to tweak these knobs to realiably get the coordinates of the column I'm after?