Action To cluster points based on distance and label using connected components.
Problem The back and forth switching between NetworkX nodes storage of attributes and Pandas DataFrame
- Seems too complex
- Index/key errors when looking up nodes
Tried Using different functions like Scikit NearestNeighbours, however resulting in the same back and forth moving of data.
Question Is there a simpler way to perform this connected components operation?
Example
import numpy as np
import pandas as pd
import dask.dataframe as dd
import networkx as nx
from scipy import spatial
#generate example dataframe
pdf = pd.DataFrame({'x':[1.0,2.0,3.0,4.0,5.0],
'y':[1.0,2.0,3.0,4.0,5.0],
'z':[1.0,2.0,3.0,4.0,5.0],
'label':[1,2,1,2,1]},
index=[1, 2, 3, 4, 5])
df = dd.from_pandas(pdf, npartitions = 2)
object_id = 0
def cluster(df, object_id=object_id):
# create kdtree
tree = spatial.cKDTree(df[['x', 'y', 'z']])
# get neighbours within distance for every point, store in dataframe as edges
edges = pd.DataFrame({'src':[], 'tgt':[]}, dtype=int)
for source, target in enumerate(tree.query_ball_tree(tree, r=2)):
target.remove(source)
if target:
edges = edges.append(pd.DataFrame({'src':[source] * len(target), 'tgt':target}), ignore_index=True)
# create graph for points using edges from Balltree query
G = nx.from_pandas_dataframe(edges, 'src', 'tgt')
for i in sorted(G.nodes()):
G.node[i]['label'] = nodes.label[i]
G.node[i]['x'] = nodes.x[i]
G.node[i]['y'] = nodes.y[i]
G.node[i]['z'] = nodes.z[i]
# remove edges between points of different classes
G.remove_edges_from([(u,v) for (u,v) in G.edges_iter() if G.node[u]['label'] != G.node[v]['label']])
# find connected components, create dataframe and assign object id
components = list(nx.connected_component_subgraphs(G))
df_objects = pd.DataFrame()
for c in components:
df_object = pd.DataFrame([[i[0], i[1]['x'], i[1]['y'], i[1]['z'], i[1]['label']] for i in c.nodes(data=True)]
, columns=['point_id', 'x', 'y', 'z', 'label']).set_index('point_id')
df_object['object_id'] = object_id
df_objects.append(df_object)
object_id += 1
return df_objects
meta = pd.DataFrame(np.empty(0, dtype=[('x',float),('y',float),('z',float), ('label',int), ('object_id', int)]))
df.apply(cluster, axis=1, meta=meta).head(10)
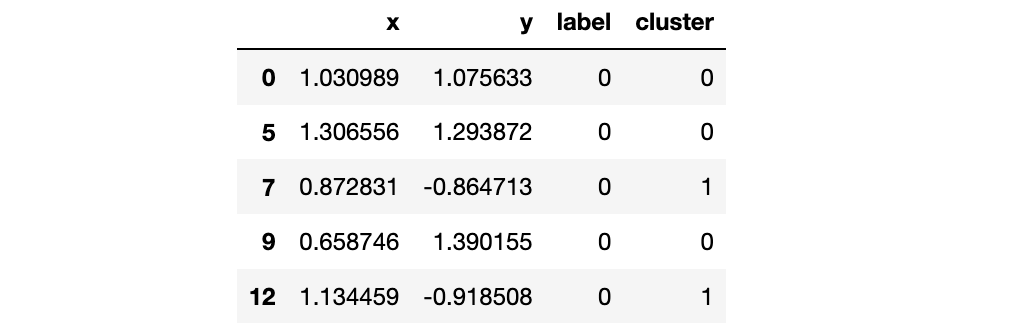
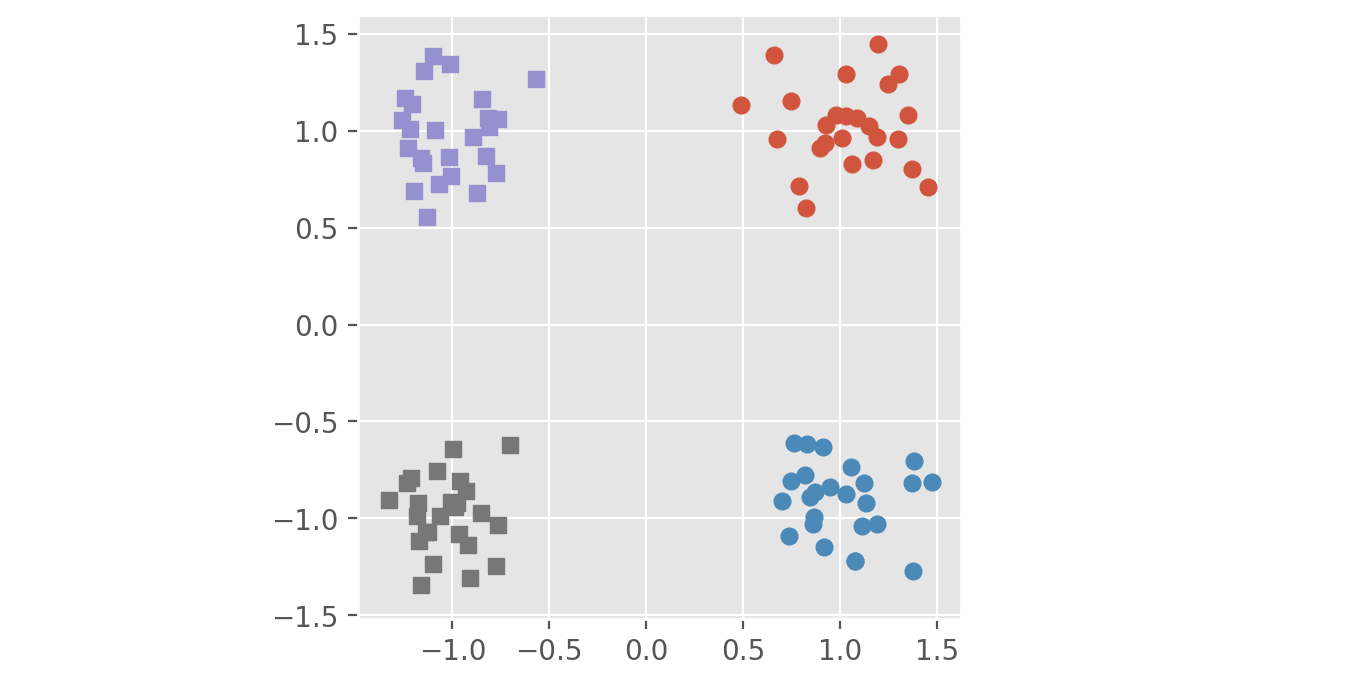
ValueError: data must be 2 dimensionswhile trying to run your code. – Border