Say, I create an object of type Foo in thread #1 and want to be able to access it in thread #3.
I can try something like:
std::atomic<int> sync{10};
Foo *fp;
// thread 1: modifies sync: 10 -> 11
fp = new Foo;
sync.store(11, std::memory_order_release);
// thread 2a: modifies sync: 11 -> 12
while (sync.load(std::memory_order_relaxed) != 11);
sync.store(12, std::memory_order_relaxed);
// thread 3
while (sync.load(std::memory_order_acquire) != 12);
fp->do_something();
- The store/release in thread #1 orders
Foowith the update to 11 - thread #2a non-atomically increments the value of
syncto 12 - the synchronizes-with relationship between thread #1 and #3 is only established when #3 loads 11
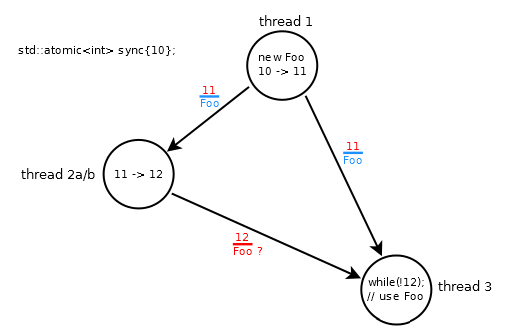
The scenario is broken because thread #3 spins until it loads 12, which may arrive out of order (wrt 11) and Foo is not ordered with 12 (due to the relaxed operations in thread #2a).
This is somewhat counter-intuitive since the modification order of sync is 10 → 11 → 12
The standard says (§ 1.10.1-6):
an atomic store-release synchronizes with a load-acquire that takes its value from the store (29.3). [ Note: Except in the specified cases, reading a later value does not necessarily ensure visibility as described below. Such a requirement would sometimes interfere with efficient implementation. —end note ]
It also says in (§ 1.10.1-5):
A release sequence headed by a release operation A on an atomic object M is a maximal contiguous subsequence of side effects in the modification order of M, where the first operation is A, and every subsequent operation
- is performed by the same thread that performed A, or
- is an atomic read-modify-write operation.
Now, thread #2a is modified to use an atomic read-modify-write operation:
// thread 2b: modifies sync: 11 -> 12
int val;
while ((val = 11) && !sync.compare_exchange_weak(val, 12, std::memory_order_relaxed));
If this release sequence is correct, Foo is synchronized with thread #3 when it loads either 11 or 12.
My questions about the use of an atomic read-modify-write are:
- Does the scenario with thread #2b constitute a correct release sequence ?
And if so:
- What are the specific properties of a read-modify-write operation that ensure this scenario is correct ?
store(11)andcompare_exchange(11, 12)constitute a release sequence? They satisfy all the requirements in the paragraph you quoted. – Goerkesync.store(12, mo_relaxed);execute and become globally visible before the spin-loop had actually loaded an11, violating causality. There can't be a control dependency as part of the implementation an atomic RMW, only a true data dependency from load to store, so it can't violate causality this way (or any other way, because of that C++ rule allowing an atomic RMW to be part of a release sequence!) – LycanthropyFoois ordered wrt 12 (I don't think it is), but that 12 is guaranteed to arrive 'after' 11 on thread #3. But even then, on a weak platform, what guarantees this ordering. If the RMW store part cannot do speculative execution, how would that impact the ordering between 11 and 12 ? – Embankwhile(load)thenstore), thestore(12)could become globally visible first (before the store that made the loop condition false), and thestore(11)could step on it. e.g. branch prediction predicts that the spin-loop ends, the store runs, then eventually the load happens and the branch condition is evaluated and found to have gone the right way. I think x86 won't do this, because it disallows LoadStore reordering, but weakly-ordered ISAs could. – LycanthropyFooonly becomes (reliably) visible when (and if) thread #3 loads 11. If it loads 12, it has become impossible to accessFoobecause it is is unordered wrt 12, and 11 is 'lost' (I referred to that scenario in the question as 'broken') – EmbankFooin #3 on loading either 11 or 12. Of course, in both scenario's, spinning to load 11 would be a bug (race condition) since nothing guarantees #3 will ever see 11, but if it did, accessingFoowould be fine. – EmbankFoois ready. A separate store doesn't have this property in C++11. – Lycanthropymo_consumeordering (loading and then dereferencing a pointer only needs a LoadLoad barrier on DEC Alpha). I guess it would also apply to storing a new value back into the shared variable, even with relaxed ordering. But like I said, in C++11 this always breaks a release sequence. C++11's memory model is as weak as Alpha. Aconsumeandreleasestore might work. – LycanthropyFoonot to be an atomic type? In some cases, non-atomicvariables aren't synchronized byatomicoperations or barriers. e.g. #40579842 shows thatatomic_thread_fencedoesn't order non-atomics, butatomic_signal_fencedoes (at least as an implementation detail on gcc). – LycanthropyFooneeds no atomicity. The question are referring may seem somewhat surprising with thethread_fencebehavior, but in that caseBis not atomic, so the compiler does not have to take inter-thread behavior into account. If you changeBtoatomic<int>, it is a different story, because then you are releasing the first store toAto become visible to another thread – Embanksignal_fence"works" whilethread_fencedidn't had me wondering if I was missing something. This clears it up some (although I should probably post a separate question about whethersignal_fencebarriering non-atomic ops in gcc is an implementation detail or required.) – Lycanthropysync=12) isn't yet retired, so it isn't yet globally visible and at the moment branch condition becomes true,sync=11store is already (globally?) visible, and so isfp = new Foo, so it seems thread 3 receives non-null pointer even in such case. – Oligoclasemo_acquireormo_consume. But on most C++ implementations on real HW there's no way loads from the future can happen in practice; it's not something that compilers can create at compile time generally. But IIRC, PowerPC's on-paper memory model is weak enough that code compiled now but run on a hypothetical / future PPC with value prediction could do that. Code compiled now withmo_acquirealready has to use enough barriers that there's no problem. – Lycanthropy