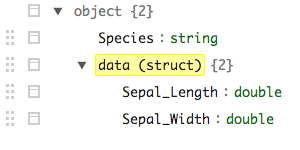
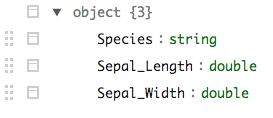
In the following example I've loaded a parquet file that contains a nested record of map objects in the meta field. sparklyr seems to do a nice job of dealing with these. However tidyr::unnest does not translate to SQL (or HQL - understandably - like LATERAL VIEW explode()) and is thus not usable. Is there a way to unnest data some other way?
tfl <- head(tf)
tfl
Source: query [?? x 10]
Database: spark connection master=yarn-client app=sparklyr local=FALSE
trkKey meta sources startTime
<chr> <list> <list> <list>
1 3juPe-k0yiMcANNMa_YiAJfJyU7WCQ3Q <S3: spark_jobj> <list [24]> <dbl [1]>
2 3juPe-k0yiAJX3ocJj1fVqru-e0syjvQ <S3: spark_jobj> <list [1]> <dbl [1]>
3 3juPe-k0yisY7UY_ufUPUo5mE1xGfmNw <S3: spark_jobj> <list [7]> <dbl [1]>
4 3juPe-k0yikXT5FhqNj87IwBw1Oy-6cw <S3: spark_jobj> <list [24]> <dbl [1]>
5 3juPe-k0yi4MMU63FEWYTNKxvDpYwsRw <S3: spark_jobj> <list [7]> <dbl [1]>
6 3juPe-k0yiFBz2uPbOQqKibCFwn7Fmlw <S3: spark_jobj> <list [19]> <dbl [1]>
# ... with 6 more variables: endTime <list>, durationInMinutes <dbl>,
# numPoints <int>, maxSpeed <dbl>, maxAltitude <dbl>, primaryKey <chr>
There is also an issue when the data is collected. E.g.,
tfl <- head(tf) %>% collect()
tfl
# A tibble: 6 × 10
trkKey meta sources startTime
<chr> <list> <list> <list>
1 3juPe-k0yiMcANNMa_YiAJfJyU7WCQ3Q <S3: spark_jobj> <list [24]> <dbl [1]>
2 3juPe-k0yiAJX3ocJj1fVqru-e0syjvQ <S3: spark_jobj> <list [1]> <dbl [1]>
3 3juPe-k0yisY7UY_ufUPUo5mE1xGfmNw <S3: spark_jobj> <list [7]> <dbl [1]>
4 3juPe-k0yikXT5FhqNj87IwBw1Oy-6cw <S3: spark_jobj> <list [24]> <dbl [1]>
5 3juPe-k0yi4MMU63FEWYTNKxvDpYwsRw <S3: spark_jobj> <list [7]> <dbl [1]>
6 3juPe-k0yiFBz2uPbOQqKibCFwn7Fmlw <S3: spark_jobj> <list [19]> <dbl [1]>
# ... with 6 more variables: endTime <list>, durationInMinutes <dbl>,
# numPoints <int>, maxSpeed <dbl>, maxAltitude <dbl>, primaryKey <chr>
tfl %>% unnest(meta)
Error: Each column must either be a list of vectors or a list of data frames [meta]
In the above, the meta file still contains spark_jobj elements instead of lists, data.frames, or even JSON strings (which is how Hive would return such data). This creates a situation where tidyr doesn't even work on the collected data.
Is there a way to get sparklyr to work more nicely with tidyr that I am missing? If not, is this planned for future sparklyr development?