This was a nice challenge!
The problem is not related to R language. We'll have the same result in any language if we just try to post some data to the download script. We have to deal with some kind of security “pattern” here. The site restricts users from retrieving the files urls and it asks them to fill forms with data in order to provide those links. If a browser can retrieve these links, then we can too by writing the proper HTTP calls. Thing is, we need to know exactly which calls we have to make. In order to find that, we need to see the individual calls the site does whenever someone clicks to download. Here is what I found a few calls before a successful 302 AJDownload.jsp POST call:
![Http requests]()
We can see it clearly, if we look at the AJDocumentation.jsp source, it makes these calls by using jQuery $.get:
$.get("http://ipinfo.io?token=xxxxxxxxxxxxxx", function (response) {
var geodatos=encodeURIComponent(response.ip+"\t"+response.country+"\t"+response.postal+"\t"+
response.loc+"\t"+response.region+"\t"+response.city+"\t"+
response.org);
$.get("jdsStatJD.jsp?ID="+geodatos+
"&url=http%3A%2F%2Fwww.worldvaluessurvey.org%2FAJDocumentation.jsp&referer=null&cms=Documentation",
function (resp2) {
});
}, "jsonp");
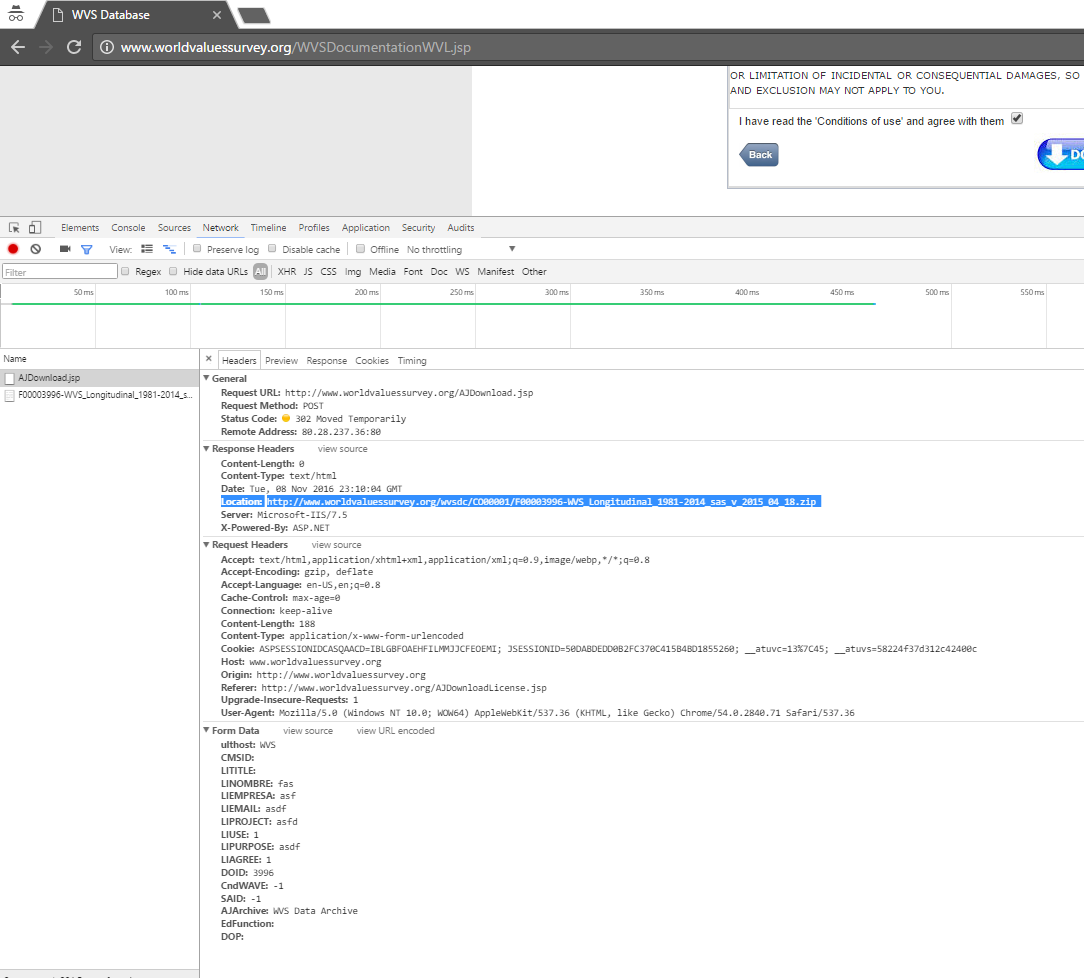
Then, a few calls below, we can see the successful POST /AJDownload.jsp with status 302 Moved Temporarily and with the wanted Location in its response headers:
![Http requests]()
HTTP/1.1 302 Moved Temporarily
Content-Length: 0
Content-Type: text/html
Location: http://www.worldvaluessurvey.org/wvsdc/CO00001/F00003724-WVS_Longitudinal_1981-2014_stata_dta_v_2015_04_18.zip
Server: Microsoft-IIS/7.5
X-Powered-By: ASP.NET
Date: Thu, 01 Dec 2016 16:24:37 GMT
So, this is the security mechanism of this site. It uses ipinfo.io to store visitor informations about their IP, Location and even the ISP organization, just before the user is about to initiate a download by clicking on a link. The script which receives these data, is the /jdsStatJD.jsp. I haven’t used ipinfo.io, nor their API key for this service (have it hidden on my screenshots) and instead I created a dummy valid sequence of data, just to validate the request. The post form data for the “protected” files are not require at all. It is possible to download the files without posting these data.
Also, the curlconverter library is not required. All we have to do, is simple GET and POST requests by using httr library. One important part I want to point out, is that in order to prevent httr POST function from following the Location header received with 302 status at our last call, we need to use the config setting config(followlocation = FALSE) which of course will prevent it from following the Location and let us fetch the Location from the headers.
OUTPUT
My R script can be run from the command line and it can accept DOID numeric values for parameters to get the file needed. For example, if we want to get the link for the file WVS_Longitudinal_1981-2014_stata_dta_v_2015_04_18, then we have to add its DOID (which is 3724) to the end of our script when calling it using the Rscript command:
Rscript wvs_fetch_downloads.r 3724
[1] "http://www.worldvaluessurvey.org/wvsdc/CO00001/F00003724-WVS_Longitudinal_1981-2014_stata_dta_v_2015_04_18.zip"
I have created an R function to get each file location you want by just passing the DOID:
getFileById <- function(fileId)
You can remove the command line argument parsing and use the function by passing the DOID directly:
#args <- commandArgs(TRUE)
#if(length(args) == 0) {
# print("No file id specified. Use './script.r ####'.")
# quit("no")
#}
#fileId <- args[1]
fileId <- "3724"
# DOID=3843 : WVS_EVS_Integrated_Dictionary_Codebook v_2014_09_22 (Excel)
# DOID=3844 : WVS_Values Surveys Integrated Dictionary_TimeSeries_v_2014-04-25 (Excel)
# DOID=3725 : WVS_Longitudinal_1981-2014_rdata_v_2015_04_18
# DOID=3996 : WVS_Longitudinal_1981-2014_sas_v_2015_04_18
# DOID=3723 : WVS_Longitudinal_1981-2014_spss_v_2015_04_18
# DOID=3724 : WVS_Longitudinal_1981-2014_stata_dta_v_2015_04_18
getFileById(fileId)
Final R working script
library(httr)
getFileById <- function(fileId) {
response <- GET(
url = "http://www.worldvaluessurvey.org/AJDocumentation.jsp?CndWAVE=-1",
add_headers(
`Accept` = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
`Accept-Encoding` = "gzip, deflate",
`Accept-Language` = "en-US,en;q=0.8",
`Cache-Control` = "max-age=0",
`Connection` = "keep-alive",
`Host` = "www.worldvaluessurvey.org",
`User-Agent` = "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0",
`Content-type` = "application/x-www-form-urlencoded",
`Referer` = "http://www.worldvaluessurvey.org/AJDownloadLicense.jsp",
`Upgrade-Insecure-Requests` = "1"))
set_cookie <- headers(response)$`set-cookie`
cookies <- strsplit(set_cookie, ';')
cookie <- cookies[[1]][1]
response <- GET(
url = "http://www.worldvaluessurvey.org/jdsStatJD.jsp?ID=2.72.48.149%09IT%09undefined%0941.8902%2C12.4923%09Lazio%09Roma%09Orange%20SA%20Telecommunications%20Corporation&url=http%3A%2F%2Fwww.worldvaluessurvey.org%2FAJDocumentation.jsp&referer=null&cms=Documentation",
add_headers(
`Accept` = "*/*",
`Accept-Encoding` = "gzip, deflate",
`Accept-Language` = "en-US,en;q=0.8",
`Cache-Control` = "max-age=0",
`Connection` = "keep-alive",
`X-Requested-With` = "XMLHttpRequest",
`Host` = "www.worldvaluessurvey.org",
`User-Agent` = "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0",
`Content-type` = "application/x-www-form-urlencoded",
`Referer` = "http://www.worldvaluessurvey.org/AJDocumentation.jsp?CndWAVE=-1",
`Cookie` = cookie))
post_data <- list(
ulthost = "WVS",
CMSID = "",
CndWAVE = "-1",
SAID = "-1",
DOID = fileId,
AJArchive = "WVS Data Archive",
EdFunction = "",
DOP = "",
PUB = "")
response <- POST(
url = "http://www.worldvaluessurvey.org/AJDownload.jsp",
config(followlocation = FALSE),
add_headers(
`Accept` = "*/*",
`Accept-Encoding` = "gzip, deflate",
`Accept-Language` = "en-US,en;q=0.8",
`Cache-Control` = "max-age=0",
`Connection` = "keep-alive",
`Host` = "www.worldvaluessurvey.org",
`User-Agent` = "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0",
`Content-type` = "application/x-www-form-urlencoded",
`Referer` = "http://www.worldvaluessurvey.org/AJDocumentation.jsp?CndWAVE=-1",
`Cookie` = cookie),
body = post_data,
encode = "form")
location <- headers(response)$location
location
}
args <- commandArgs(TRUE)
if(length(args) == 0) {
print("No file id specified. Use './script.r ####'.")
quit("no")
}
fileId <- args[1]
# DOID=3843 : WVS_EVS_Integrated_Dictionary_Codebook v_2014_09_22 (Excel)
# DOID=3844 : WVS_Values Surveys Integrated Dictionary_TimeSeries_v_2014-04-25 (Excel)
# DOID=3725 : WVS_Longitudinal_1981-2014_rdata_v_2015_04_18
# DOID=3996 : WVS_Longitudinal_1981-2014_sas_v_2015_04_18
# DOID=3723 : WVS_Longitudinal_1981-2014_spss_v_2015_04_18
# DOID=3724 : WVS_Longitudinal_1981-2014_stata_dta_v_2015_04_18
getFileById(fileId)