For an application that we built, we are using a simple statistical model for word prediction (like Google Autocomplete) to guide search.
It uses a sequence of ngrams gathered from a large corpus of relevant text documents. By considering the previous N-1 words, it suggests the 5 most likely "next words" in descending order of probability, using Katz back-off.
We would like to extend this to predict phrases (multiple words) instead of a single word. However, when we are predicting a phrase, we would prefer not to display its prefixes.
For example, consider the input the cat.
In this case we would like to make predictions like the cat in the hat, but not the cat in & not the cat in the.
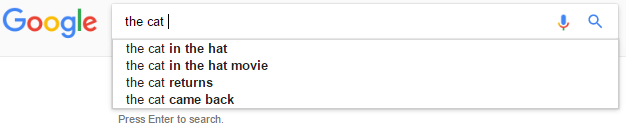
Assumptions:
We do not have access to past search statistics
We do not have tagged text data (for instance, we do not know the parts of speech)
What is a typical way to make these kinds of multi-word predictions? We've tried multiplicative and additive weighting of longer phrases, but our weights are arbitrary and overfit to our tests.