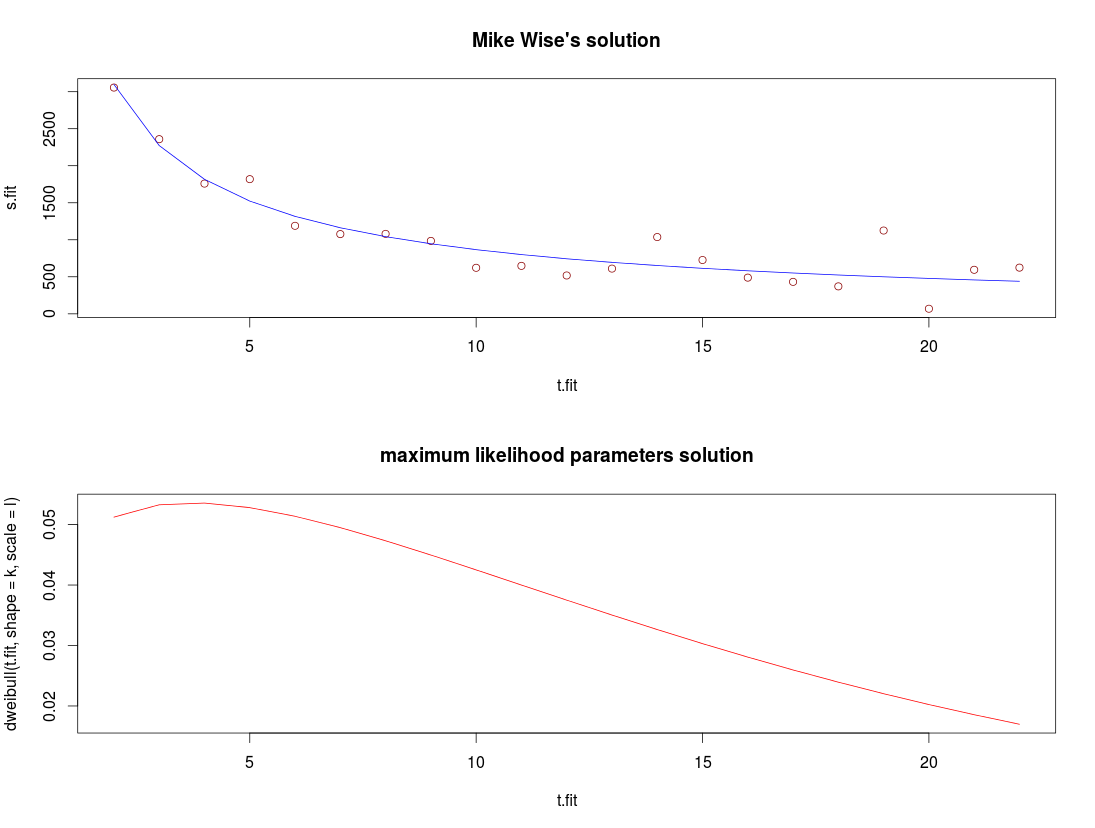
I have frequency values changing with the time (x axis units), as presented on the picture below. After some normalization these values may be seen as data points of a density function for some distribution.
Q: Assuming that these frequency points are from Weibull distribution T, how can I fit best Weibull density function to the points so as to infer the distribution T parameters from it?
sample <- c(7787,3056,2359,1759,1819,1189,1077,1080,985,622,648,518,
611,1037,727,489,432,371,1125,69,595,624)
plot(1:length(sample), sample, type = "l")
points(1:length(sample), sample)

Update.
To prevent from being misunderstood, I would like to add little more explanation. By saying I have frequency values changing with the time (x axis units) I mean I have data which says that I have:
- 7787 realizations of value 1
- 3056 realizations of value 2
- 2359 realizations of value 3 ... etc.
Some way towards my goal (incorrect one, as I think) would be to create a set of these realizations:
# Loop to simulate values
set.values <- c()
for(i in 1:length(sample)){
set.values <<- c(set.values, rep(i, times = sample[i]))
}
hist(set.values)
lines(1:length(sample), sample)
points(1:length(sample), sample)

and use fitdistr on the set.values:
f2 <- fitdistr(set.values, 'weibull')
f2
Why I think it is incorrect way and why I am looking for a better solution in R?
in the distribution fitting approach presented above it is assumed that
set.valuesis a complete set of my realisations from the distributionTin my original question I know the points from the first part of the density curve - I do not know its tail and I want to estimate the tail (and the whole density function)

 Here is a better attempt, like before it uses
Here is a better attempt, like before it uses 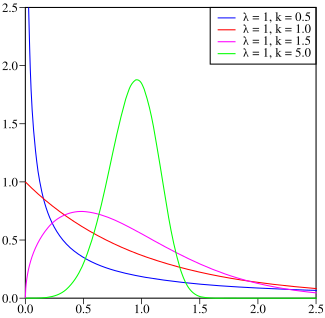{kind=link}
{kind=link}
T. Maybe it is reasonalbe to assume that first part (part between 1. and 2. points in the histogram above) is linear and the latter part - Weibull (Weibull is an asumption I was given from someone who provided me with data. I wouldn't bet my life for this but I am inclined to assume the same.) – Boothe