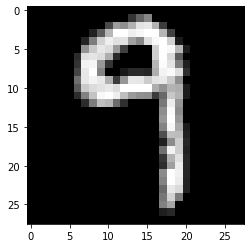
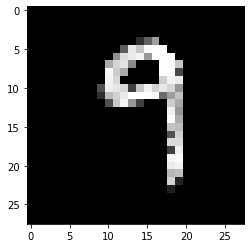
I've built a neural network with keras using the mnist dataset and now I'm trying to use it on photos of actual handwritten digits. Of course I don't expect the results to be perfect but the results I currently get have a lot of room for improvement.
For starters I test it with some photos of individual digits written in my clearest handwriting. They are square and they have the same dimensions and color as the images in the mnist dataset. They are saved in a folder called individual_test like this for example: 7(2)_digit.jpg.
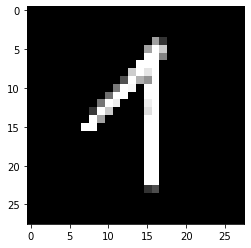
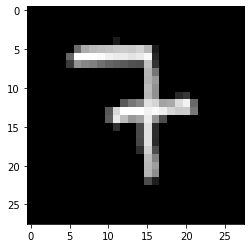
The network often is terribly sure of the wrong result which I'll give you an example for:
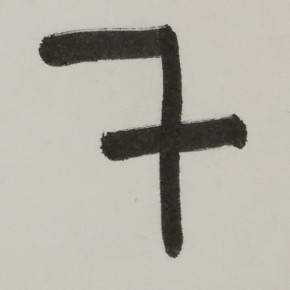
The results I get for this picture are the following:
result: 3 . probabilities: [1.9963557196245318e-10, 7.241294497362105e-07, 0.02658148668706417, 0.9726449251174927, 2.5416460047722467e-08, 2.6078915027483163e-08, 0.00019745019380934536, 4.8302300825753264e-08, 0.0005754049634560943, 2.8358477788259506e-09]
So the network is 97% sure this is a 3 and this picture is by far not the only case. Out of 38 pictures only 16 were correctly recognised. What shocks me is the fact that the network is so sure of its result although it couldn't be farther from the correct result.
EDIT
After adding a threshold to prepare_image (img = cv2.threshold(img, 0.1, 1, cv2.THRESH_BINARY_INV)[1]) the performance has slightly improved. It now gets 19 out of 38 pictures right but for some images including the one shown above it still is pretty sure of the wrong result. This is what I get now:
result: 3 . probabilities: [1.0909866760000497e-11, 1.1584616004256532e-06, 0.27739930152893066, 0.7221096158027649, 1.900260038212309e-08, 6.555900711191498e-08, 4.479645940591581e-05, 6.455550760620099e-07, 0.0004443934594746679, 1.0013242457418414e-09]
So it now is only 72% sure of its result which is better but still ...
What can I do to improve the performance? Can I prepare my images better? Or should I add my own images to the training data? And if so, how would I do such a thing?
EDIT
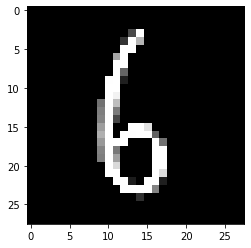
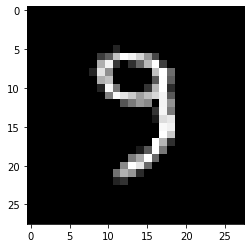
This is what the picture displayed above looks like after applying prepare_image to it:
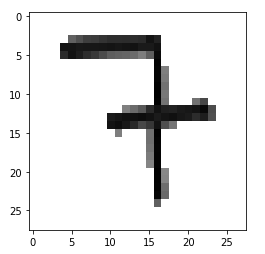
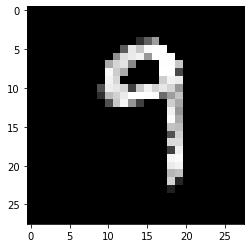
After using threshold this is what the same picture looks like:
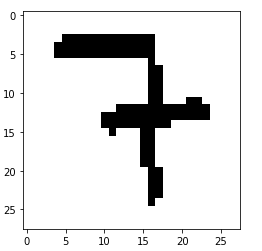
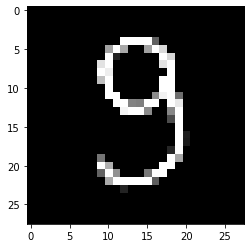
In comparison: This is one of the pictures provided by the mnist dataset:
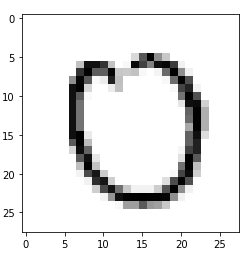
They look fairly similar to me. How can I improve this?
Here's my code (including threshold):
# import keras and the MNIST dataset
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from keras.utils import np_utils
# numpy is necessary since keras uses numpy arrays
import numpy as np
# imports for pictures
import matplotlib.pyplot as plt
import PIL
import cv2
# imports for tests
import random
import os
class mnist_network():
def __init__(self):
""" load data, create and train model """
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# flatten 28*28 images to a 784 vector for each image
num_pixels = X_train.shape[1] * X_train.shape[2]
X_train = X_train.reshape((X_train.shape[0], num_pixels)).astype('float32')
X_test = X_test.reshape((X_test.shape[0], num_pixels)).astype('float32')
# normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
# create model
self.model = Sequential()
self.model.add(Dense(num_pixels, input_dim=num_pixels, kernel_initializer='normal', activation='relu'))
self.model.add(Dense(num_classes, kernel_initializer='normal', activation='softmax'))
# Compile model
self.model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# train the model
self.model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200, verbose=2)
self.train_img = X_train
self.train_res = y_train
self.test_img = X_test
self.test_res = y_test
def predict_result(self, img, show = False):
""" predicts the number in a picture (vector) """
assert type(img) == np.ndarray and img.shape == (784,)
if show:
img = img.reshape((28, 28))
# show the picture
plt.imshow(img, cmap='Greys')
plt.show()
img = img.reshape(img.shape[0] * img.shape[1])
num_pixels = img.shape[0]
# the actual number
res_number = np.argmax(self.model.predict(img.reshape(-1,num_pixels)), axis = 1)
# the probabilities
res_probabilities = self.model.predict(img.reshape(-1,num_pixels))
return (res_number[0], res_probabilities.tolist()[0]) # we only need the first element since they only have one
def prepare_image(self, img, show = False):
""" prepares the partial images used in partial_img_rec by transforming them
into numpy arrays that the network will be able to process """
# convert to greyscale
img = img.convert("L")
# rescale image to 28 *28 dimension
img = img.resize((28,28), PIL.Image.ANTIALIAS)
# inverse colors since the training images have a black background
#img = PIL.ImageOps.invert(img)
# transform to vector
img = np.asarray(img, "float32")
img = img / 255.
img[img < 0.5] = 0.
img = cv2.threshold(img, 0.1, 1, cv2.THRESH_BINARY_INV)[1]
if show:
plt.imshow(img, cmap = "Greys")
# flatten image to 28*28 = 784 vector
num_pixels = img.shape[0] * img.shape[1]
img = img.reshape(num_pixels)
return img
def partial_img_rec(self, image, upper_left, lower_right, results=[], show = False):
""" partial is a part of an image """
left_x, left_y = upper_left
right_x, right_y = lower_right
print("current test part: ", upper_left, lower_right)
print("results: ", results)
# condition to stop recursion: we've reached the full width of the picture
width, height = image.size
if right_x > width:
return results
partial = image.crop((left_x, left_y, right_x, right_y))
if show:
partial.show()
partial = self.prepare_image(partial)
step = height // 10
# is there a number in this part of the image?
res, prop = self.predict_result(partial)
print("result: ", res, ". probabilities: ", prop)
# only count this result if the network is at least 50% sure
if prop[res] >= 0.5:
results.append(res)
# step is 80% of the partial image's size (which is equivalent to the original image's height)
step = int(height * 0.8)
print("found valid result")
else:
# if there is no number found we take smaller steps
step = height // 20
print("step: ", step)
# recursive call with modified positions ( move on step variables )
return self.partial_img_rec(image, (left_x + step, left_y), (right_x + step, right_y), results = results)
def individual_digits(self, img):
""" uses partial_img_rec to predict individual digits in square images """
assert type(img) == PIL.JpegImagePlugin.JpegImageFile or type(img) == PIL.PngImagePlugin.PngImageFile or type(img) == PIL.Image.Image
return self.partial_img_rec(img, (0,0), (img.size[0], img.size[1]), results=[])
def test_individual_digits(self):
""" test partial_img_rec with some individual digits (shape: square)
saved in the folder 'individual_test' following the pattern 'number_digit.jpg' """
cnt_right, cnt_wrong = 0,0
folder_content = os.listdir(".\individual_test")
for imageName in folder_content:
# image file must be a jpg or png
assert imageName[-4:] == ".jpg" or imageName[-4:] == ".png"
correct_res = int(imageName[0])
image = PIL.Image.open(".\\individual_test\\" + imageName).convert("L")
# only square images in this test
if image.size[0] != image.size[1]:
print(imageName, " has the wrong proportions: ", image.size,". It has to be a square.")
continue
predicted_res = self.individual_digits(image)
if predicted_res == []:
print("No prediction possible for ", imageName)
else:
predicted_res = predicted_res[0]
if predicted_res != correct_res:
print("error in partial_img-rec! Predicted ", predicted_res, ". The correct result would have been ", correct_res)
cnt_wrong += 1
else:
cnt_right += 1
print("correctly predicted ",imageName)
print(cnt_right, " out of ", cnt_right + cnt_wrong," digits were correctly recognised. The success rate is therefore ", (cnt_right / (cnt_right + cnt_wrong)) * 100," %.")
def multiple_digits(self, img):
""" takes as input an image without unnecessary whitespace surrounding the digits """
#assert type(img) == myImage
width, height = img.size
# start with the first square part of the image
res_list = self.partial_img_rec(img, (0,0),(height ,height), results = [])
res_str = ""
for elem in res_list:
res_str += str(elem)
return res_str
def test_multiple_digits(self):
""" tests the function 'multiple_digits' using some images saved in the folder 'multi_test'.
These images contain multiple handwritten digits without much whitespac surrounding them.
The correct solutions are saved in the files' names followed by the characte '_'. """
cnt_right, cnt_wrong = 0,0
folder_content = os.listdir(".\multi_test")
for imageName in folder_content:
# image file must be a jpg or png
assert imageName[-4:] == ".jpg" or imageName[-4:] == ".png"
image = PIL.Image.open(".\\multi_test\\" + imageName).convert("L")
correct_res = imageName.split("_")[0]
predicted_res = self.multiple_digits(image)
if correct_res == predicted_res:
cnt_right += 1
else:
cnt_wrong += 1
print("Error in multiple_digits! The network predicted ", predicted_res, " but the correct result would have been ", correct_res)
print("The network predicted correctly ", cnt_right, " out of ", cnt_right + cnt_wrong, " pictures. That's a success rate of ", cnt_right / (cnt_right + cnt_wrong) * 100, "%.")
network = mnist_network()
# this is the image shown above
result = network.individual_digits(PIL.Image.open(".\individual_test\\7(2)_digit.jpg"))