I am training an object detector for my own data using Tensorflow Object Detection API. I am following the (great) tutorial by Dat Tran https://towardsdatascience.com/how-to-train-your-own-object-detector-with-tensorflows-object-detector-api-bec72ecfe1d9. I am using the provided ssd_mobilenet_v1_coco-model pre-trained model checkpoint as the starting point for the training. I have only one object class.
I exported the trained model, ran it on the evaluation data and looked at the resulted bounding boxes. The trained model worked nicely; I would say that if there was 20 objects, typically there were 13 objects with spot on predicted bounding boxes ("true positives"); 7 where the objects were not detected ("false negatives"); 2 cases where problems occur were two or more objects are close to each other: the bounding boxes get drawn between the objects in some of these cases ("false positives"<-of course, calling these "false positives" etc. is inaccurate, but this is just for me to understand the concept of precision here). There are almost no other "false positives". This seems much better result than what I was hoping to get, and while this kind of visual inspection does not give the actual mAP (which is calculated based on overlap of the predicted and tagged bounding boxes?), I would roughly estimate the mAP as something like 13/(13+2) >80%.
However, when I run the evaluation (eval.py) (on two different evaluation sets), I get the following mAP graph (0.7 smoothed):
mAP during training
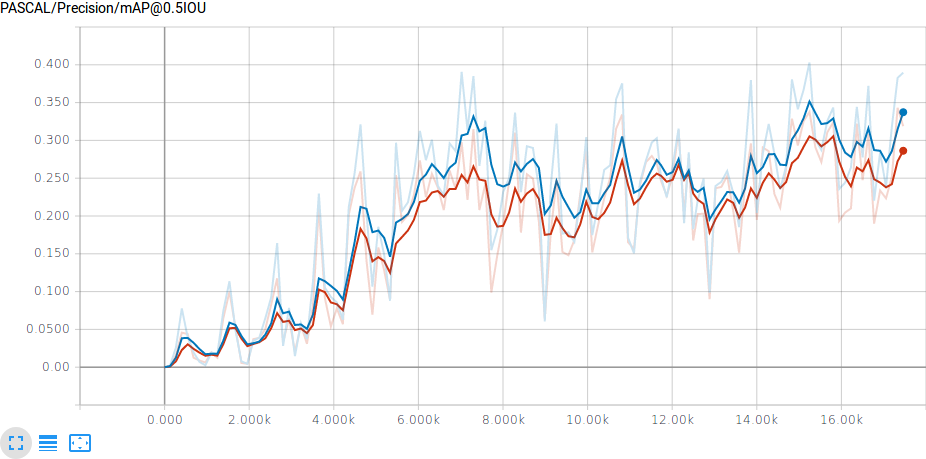{kind=link}
This would indicate a huge variation in mAP, and level of about 0.3 at the end of the training, which is way worse than what I would assume based on how well the boundary boxes are drawn when I use the exported output_inference_graph.pb on the evaluation set.
Here is the total loss graph for the training: total loss during training
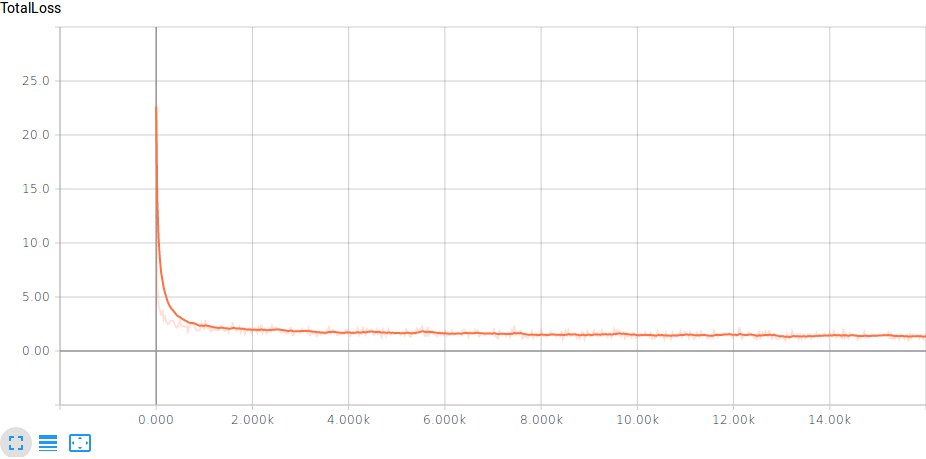{kind=link}
My training data consist of 200 images with about 20 labeled objects each (I labeled them using the labelImg app); the images are extracted from a video and the objects are small and kind of blurry. The original image size is 1200x900, so I reduced it to 600x450 for the training data. Evaluation data (which I used both as the evaluation data set for eval.pyand to visually check what the predictions look like) is similar, consists of 50 images with 20 object each, but is still in the original size (the training data is extracted from the first 30 min of the video and evaluation data from the last 30 min).
Question 1: Why is the mAP so low in evaluation when the model appears to work so well? Is it normal for the mAP graph fluctuate so much? I did not touch the default values for how many images the tensorboard uses to draw the graph (I read this question: Tensorflow object detection api validation data size and have some vague idea that there is some default value that can be changed?)
Question 2: Can this be related to different size of the training data and the evaluation data (1200x700 vs 600x450)? If so, should I resize the evaluation data, too? (I did not want to do this as my application uses the original image size, and I want to evaluate how well the model does on that data).
Question 3: Is it a problem to form the training and evaluation data from images where there are multiple tagged objects per image (i.e. surely the evaluation routine compares all the predicted bounding boxes in one image to all the tagged bounding boxes in one image, and not all the predicted boxes in one image to one tagged box which would preduce many "false false positives"?)
(Question 4: it seems to me the model training could have been stopped after around 10000 timesteps were the mAP kind of leveled out, is it now overtrained? it's kind of hard to tell when it fluctuates so much.)
I am a newbie with object detection so I very much appreciate any insight anyone can offer! :)