I have observed that inserting data into a Memory-Optimized Table is much slower than an equivalent parallelized insert to a disk-based table on a 5-SSD stripe set.
--DDL for Memory-Optimized Table
CREATE TABLE [MYSCHEMA].[WIDE_MEMORY_TABLE]
(
[TX_ID] BIGINT NOT NULL
, [COLUMN_01] [NVARCHAR](10) NOT NULL
, [COLUMN_02] [NVARCHAR] (10) NOT NULL
--etc., about 100 columns
--at least one index is required for Memory-Optimized Tables
, INDEX IX_WIDE_MEMORY_TABLE_ENTITY_ID HASH (TX_ID) WITH (BUCKET_COUNT=10000000)
)
WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_ONLY)
--DDL for Disk-Based Table
CREATE TABLE [MYSCHEMA].[WIDE_DISK_TABLE]
(
[TX_ID] BIGINT NOT NULL
, [COLUMN_01] [NVARCHAR](10) NOT NULL
, [COLUMN_02] [NVARCHAR] (10) NOT NULL
--etc., about 100 columns
--No indexes
) ON [PRIMARY]
For this particular test, I am batching 10,000,000 rows into this table in sets of 25,000. The statement looks something like this for the Memory-Optimized Table:
--Insert to Memory-Optimized Table
INSERT INTO
WIDE_MEMORY_TABLE
(
TX_ID
, COLUMN_01
, COLUMN_02
--etc., about 100 columns
)
SELECT
S.COLUMN_01
, S.COLUMN_02
--etc., about 100 columns
FROM
[MYSCHEMA].[SOURCE_TABLE] AS S WITH(TABLOCK)
WHERE
S.TX_ID >= 1
AND S.TX_ID < 25001
OPTION (MAXDOP 4)
This process continues to load 10,000,000 rows. Each iteration just retrieves the next 25,000 rows. The SELECT performs a seek on a covering index on [MY_SCHEMA].[SOURCE_TABLE]. The query plan shows a serialized insert to BIG_MEMORY_TABLE. Each set of 25,000 rows takes around 1400ms.
If I do this to a disk-based table, hosted on a 5-SSD stripe (5,000 IOPS per disk, 200MB/sec throughput), the inserts progress much faster, averaging around 700ms. In the disk-based case, the query performs a parallel insert to [MY_SCHEMA].[WIDE_DISK_TABLE]. Note the TABLOCK hint on [MYSCHEMA].[WIDE_DISK_TABLE].
--Insert to Disk-Based Table
INSERT INTO
WIDE_DISK_TABLE WITH(TABLOCK)
(
TX_ID
, COLUMN_01
, COLUMN_02
--etc., about 100 columns
)
SELECT
S.COLUMN_01
, S.COLUMN_02
--etc., about 100 columns
FROM
[MYSCHEMA].[SOURCE_TABLE] AS S WITH(TABLOCK)
WHERE
S.TX_ID >= 1
AND S.TX_ID < 25001
OPTION (MAXDOP 4)
Granted, the disk-based table does not have an index, and the TABLOCK hint enables parallel insert, but I expect way more from an INSERT to RAM.
Any ideas?
Thanks!
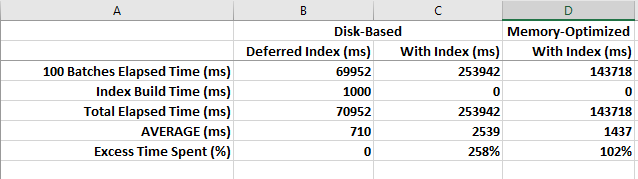
Here is a comparison of 100 batches run in 3 modes: Disk-based, with Deferred Index creation, Disk-based with Index, and Memory-Optimized with Index (at least one index is required on Memory-Optimized tables).
DURABILITY=SCHEMA_ONLYI wouldn't expect any logging anyway (though it's a while since I read up on in memory OLTP and may be wrong on that) – Ockham