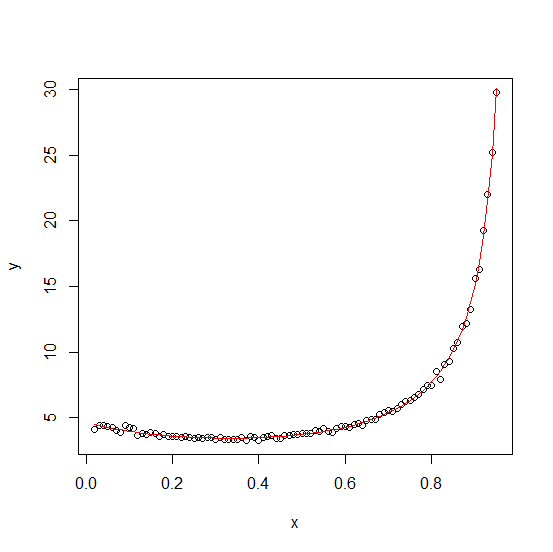
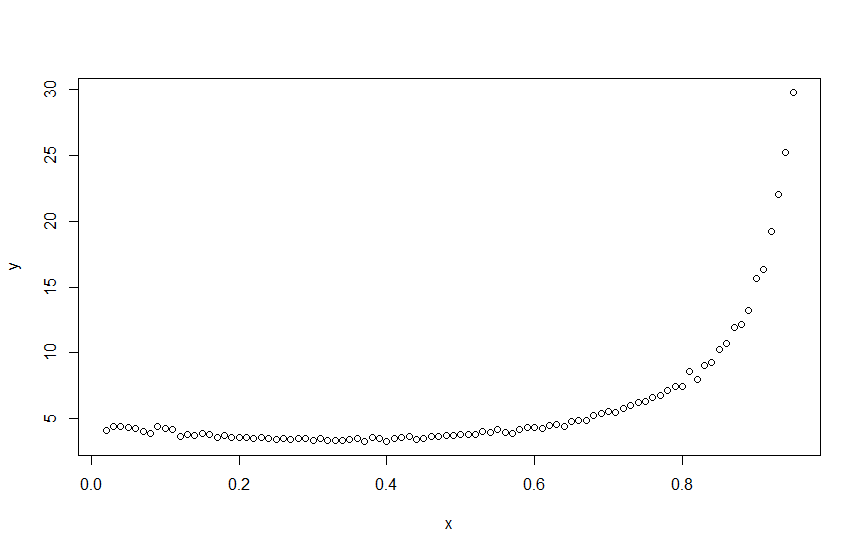
I am trying to fit a polynomial to my dataset, which looks like that (full dataset is at the end of the post):
The theory predicts that the formulation of the curve is:
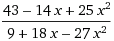
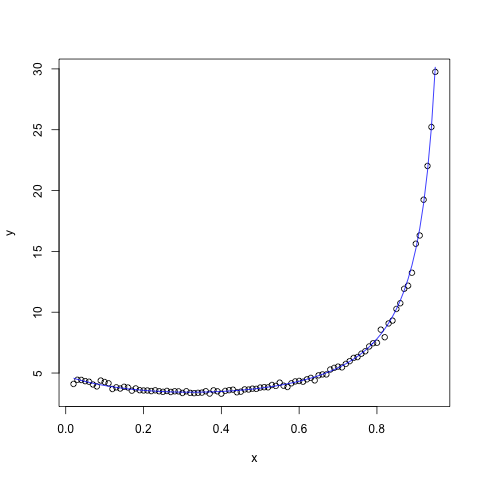
which looks like this (for x between 0 and 1):
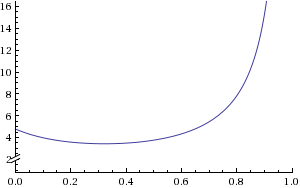
When I try to make a linear model in R by doing:
mod <- lm(y ~ poly(x, 2, raw=TRUE)/poly(x, 2))
I get the following curve:
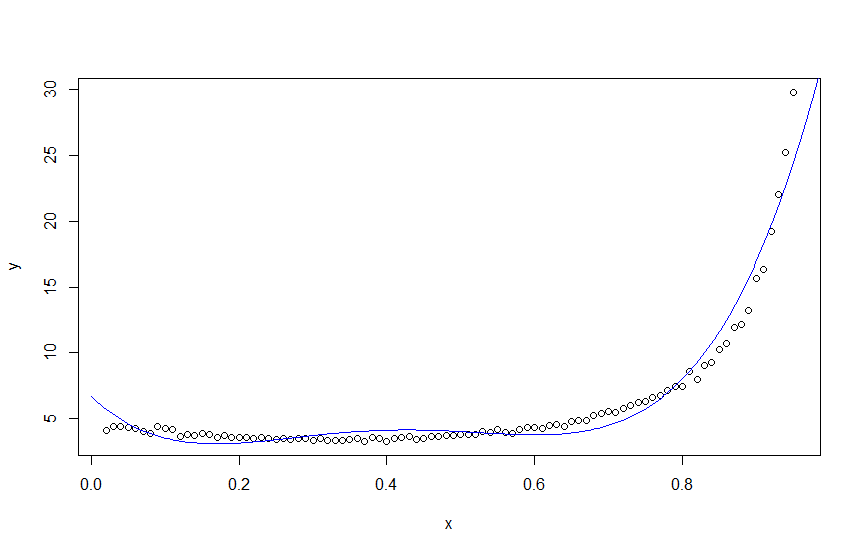
Which is much different from what I would expect. Have you got any idea how to fit a new curve from this data so that it would be similar to the one, which theory predicts? Also, it should have only one minimum.
Full dataset:
Vector of x values:
x <- c(0.02, 0.03, 0.04, 0.05, 0.06, 0.07, 0.08, 0.09, 0.10, 0.11, 0.12,
0.13, 0.14, 0.15, 0.16, 0.17, 0.18, 0.19, 0.20, 0.21, 0.22, 0.23, 0.24, 0.25,
0.26, 0.27, 0.28, 0.29, 0.30, 0.31, 0.32, 0.33, 0.34, 0.35, 0.36, 0.37, 0.38,
0.39, 0.40, 0.41, 0.42, 0.43, 0.44, 0.45, 0.46, 0.47, 0.48, 0.49, 0.50, 0.51,
0.52, 0.53, 0.54, 0.55, 0.56, 0.57, 0.58, 0.59, 0.60, 0.61, 0.62, 0.63, 0.64,
0.65, 0.66, 0.67, 0.68, 0.69, 0.70, 0.71, 0.72, 0.73, 0.74, 0.75, 0.76, 0.77,
0.78, 0.79, 0.80, 0.81, 0.82, 0.83, 0.84, 0.85, 0.86, 0.87, 0.88, 0.89, 0.90,
0.91, 0.92, 0.93, 0.94, 0.95)
Vector of y values:
y <- c(4.104, 4.444, 4.432, 4.334, 4.285, 4.058, 3.901, 4.382,
4.258, 4.158, 3.688, 3.826, 3.724, 3.867, 3.811, 3.550, 3.736, 3.591,
3.566, 3.566, 3.518, 3.581, 3.505, 3.454, 3.529, 3.444, 3.501, 3.493,
3.362, 3.504, 3.365, 3.348, 3.371, 3.389, 3.506, 3.310, 3.578, 3.497,
3.302, 3.530, 3.593, 3.630, 3.420, 3.467, 3.656, 3.644, 3.715, 3.698,
3.807, 3.836, 3.826, 4.017, 3.942, 4.208, 3.959, 3.856, 4.157, 4.312,
4.349, 4.286, 4.483, 4.599, 4.395, 4.811, 4.887, 4.885, 5.286, 5.422,
5.527, 5.467, 5.749, 5.980, 6.242, 6.314, 6.587, 6.790, 7.183, 7.450,
7.487, 8.566, 7.946, 9.078, 9.308, 10.267, 10.738, 11.922, 12.178, 13.243,
15.627, 16.308, 19.246, 22.022, 25.223, 29.752)