How do we increase the speed of this query?
We have approximately 100 consumers within the span of 1-2 minutes executing the following query. Each one of these runs represents 1 run of a consumption function.
TableQuery<T> treanslationsQuery = new TableQuery<T>()
.Where(
TableQuery.CombineFilters(
TableQuery.GenerateFilterCondition("PartitionKey", QueryComparisons.Equal, sourceDestinationPartitionKey)
, TableOperators.Or,
TableQuery.GenerateFilterCondition("PartitionKey", QueryComparisons.Equal, anySourceDestinationPartitionKey)
)
);
This query will yield approximately 5000 results.
Full code:
public static async Task<IEnumerable<T>> ExecuteQueryAsync<T>(this CloudTable table, TableQuery<T> query) where T : ITableEntity, new()
{
var items = new List<T>();
TableContinuationToken token = null;
do
{
TableQuerySegment<T> seg = await table.ExecuteQuerySegmentedAsync(query, token);
token = seg.ContinuationToken;
items.AddRange(seg);
} while (token != null);
return items;
}
public static IEnumerable<Translation> Get<T>(string sourceParty, string destinationParty, string wildcardSourceParty, string tableName) where T : ITableEntity, new()
{
var acc = CloudStorageAccount.Parse(Environment.GetEnvironmentVariable("conn"));
var tableClient = acc.CreateCloudTableClient();
var table = tableClient.GetTableReference(Environment.GetEnvironmentVariable("TableCache"));
var sourceDestinationPartitionKey = $"{sourceParty.ToLowerTrim()}-{destinationParty.ToLowerTrim()}";
var anySourceDestinationPartitionKey = $"{wildcardSourceParty}-{destinationParty.ToLowerTrim()}";
TableQuery<T> treanslationsQuery = new TableQuery<T>()
.Where(
TableQuery.CombineFilters(
TableQuery.GenerateFilterCondition("PartitionKey", QueryComparisons.Equal, sourceDestinationPartitionKey)
, TableOperators.Or,
TableQuery.GenerateFilterCondition("PartitionKey", QueryComparisons.Equal, anySourceDestinationPartitionKey)
)
);
var over1000Results = table.ExecuteQueryAsync(treanslationsQuery).Result.Cast<Translation>();
return over1000Results.Where(x => x.expireAt > DateTime.Now)
.Where(x => x.effectiveAt < DateTime.Now);
}
During these executions, when there are 100 consumers, as you can see the requests will cluster and form spikes:
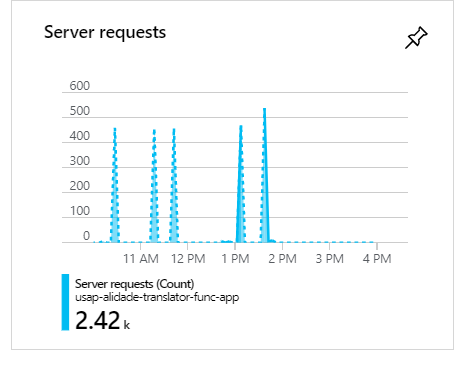
During these spikes, the requests often take over 1 minute:
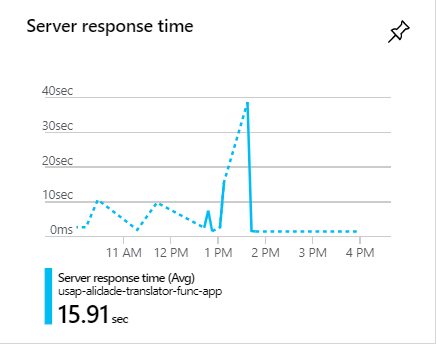
How do we increase the speed of this query?