When it comes to slicing and aggregating data (by time or something else), the star schema (Kimball star) is a fairly simple, yet powerful solution. Suppose that for each click we store time (to second resolution), user’s info, the button ID, and user’s location. To enable easy slicing and dicing, I’ll start with pre-loaded lookup tables for properties of objects that rarely change -- so called dimension tables in the DW world.
![pagevisit2_model_02]()
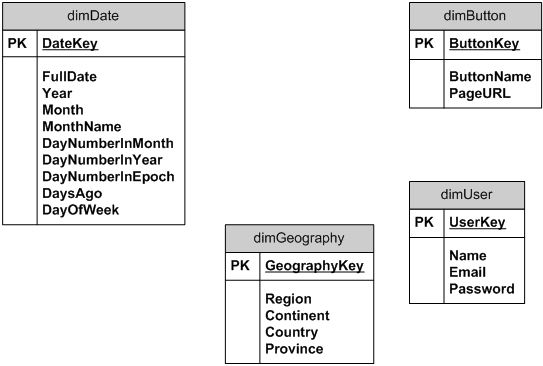
The dimDate table has one row for each day, with number of attributes (fields) that describe a specific day. The table can be pre-loaded for years in advance, and should be updated once per day if it contains fields like DaysAgo, WeeksAgo, MonthsAgo, YearsAgo; otherwise it can be “load and forget”. The dimDate allows for easy slicing per date attributes like
WHERE [YEAR] = 2009 AND DayOfWeek = 'Sunday'
For ten years of data the table has only ~3650 rows.
The dimGeography table is preloaded with geography regions of interest -- number of rows depend on “geographic resolution” required in reports, it allows for data slicing like
WHERE Continent = 'South America'
Once loaded, it is rarely changed.
For each button of the site, there is one row in the dimButton table, so a query may have
WHERE PageURL = 'http://…/somepage.php'
The dimUser table has one row per registered user, this one should be loaded with a new user info as soon as the user registers, or at least the new user info should be in the table before any other user transaction is recorded in fact tables.
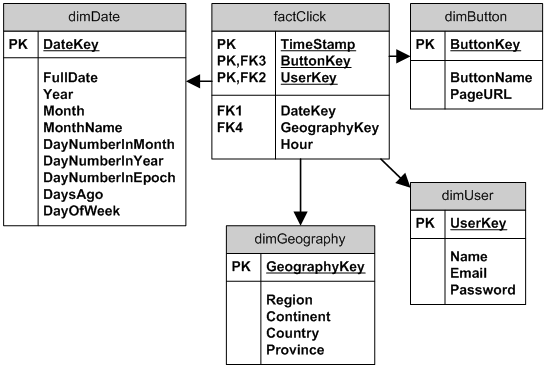
To record button clicks, I’ll add the factClick table.
![pagevisit2_model_01]()
The factClick table has one row for each click of a button from a specific user at a point in time. I have used TimeStamp (second resolution), ButtonKey and UserKey in a composite primary key to to filter-out clicks faster than one-per-second from a specific user. Note the Hour field, it contains the hour part of the TimeStamp, an integer in range 0-23 to allow for easy slicing per hour, like
WHERE [HOUR] BETWEEN 7 AND 9
So, now we have to consider:
- How to load the table? Periodically -- maybe every hour or every few minutes -- from the weblog using an ETL tool, or a low-latency solution using some kind of event-streaming process.
- How long to keep the information in the table?
Regardless of whether the table keeps information for a day only or for few years -- it should be partitioned; ConcernedOfTunbridgeW has explained partitioning in his answer, so I’ll skip it here.
Now, a few example of slicing and dicing per different attributes (including day and hour)
To simplify queries, I’ll add a view to flatten the model:
/* To simplify queries flatten the model */
CREATE VIEW vClicks
AS
SELECT *
FROM factClick AS f
JOIN dimDate AS d ON d.DateKey = f.DateKey
JOIN dimButton AS b ON b.ButtonKey = f.ButtonKey
JOIN dimUser AS u ON u.UserKey = f.UserKey
JOIN dimGeography AS g ON g.GeographyKey = f.GeographyKey
A query example
/*
Count number of times specific users clicked any button
today between 7 and 9 AM (7:00 - 9:59)
*/
SELECT [Email]
,COUNT(*) AS [Counter]
FROM vClicks
WHERE [DaysAgo] = 0
AND [Hour] BETWEEN 7 AND 9
AND [Email] IN ('[email protected]', '[email protected]')
GROUP BY [Email]
ORDER BY [Email]
Suppose that I am interested in data for User = ALL. The dimUser is a large table, so I’ll make a view without it, to speed up queries.
/*
Because dimUser can be large table it is good
to have a view without it, to speed-up queries
when user info is not required
*/
CREATE VIEW vClicksNoUsr
AS
SELECT *
FROM factClick AS f
JOIN dimDate AS d ON d.DateKey = f.DateKey
JOIN dimButton AS b ON b.ButtonKey = f.ButtonKey
JOIN dimGeography AS g ON g.GeographyKey = f.GeographyKey
A query example
/*
Count number of times a button was clicked on a specific page
today and yesterday, for each hour.
*/
SELECT [FullDate]
,[Hour]
,COUNT(*) AS [Counter]
FROM vClicksNoUsr
WHERE [DaysAgo] IN ( 0, 1 )
AND PageURL = 'http://...MyPage'
GROUP BY [FullDate], [Hour]
ORDER BY [FullDate] DESC, [Hour] DESC
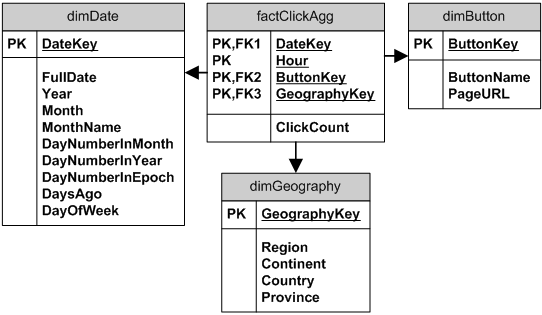
Suppose that for aggregations we do not need to keep specific user info, but are only interested in date, hour, button and geography. Each row in the factClickAgg table has a counter for each hour a specific button was clicked from a specific geography area.
![pagevisit2_model_03]()
The factClickAgg table can be loaded hourly, or even at the end of each day –- depending on requirements for reporting and analytic. For example, let’s say that the table is loaded at the end of each day (after midnight), I can use something like:
/* At the end of each day (after midnight) aggregate data. */
INSERT INTO factClickAgg
SELECT DateKey
,[Hour]
,ButtonKey
,GeographyKey
,COUNT(*) AS [ClickCount]
FROM vClicksNoUsr
WHERE [DaysAgo] = 1
GROUP BY DateKey
,[Hour]
,ButtonKey
,GeographyKey
To simplify queries, I'll create a view to flatten the model:
/* To simplify queries for aggregated data */
CREATE VIEW vClicksAggregate
AS
SELECT *
FROM factClickAgg AS f
JOIN dimDate AS d ON d.DateKey = f.DateKey
JOIN dimButton AS b ON b.ButtonKey = f.ButtonKey
JOIN dimGeography AS g ON g.GeographyKey = f.GeographyKey
Now I can query aggregated data, for example by day :
/*
Number of times a specific buttons was clicked
in year 2009, by day
*/
SELECT FullDate
,SUM(ClickCount) AS [Counter]
FROM vClicksAggregate
WHERE ButtonName = 'MyBtn_1'
AND [Year] = 2009
GROUP BY FullDate
ORDER BY FullDate
Or with a few more options
/*
Number of times specific buttons were clicked
in year 2008, on Saturdays, between 9:00 and 11:59 AM
by users from Africa
*/
SELECT SUM(ClickCount) AS [Counter]
FROM vClicksAggregate
WHERE [Year] = 2008
AND [DayOfWeek] = 'Saturday'
AND [Hour] BETWEEN 9 AND 11
AND Continent = 'Africa'
AND ButtonName IN ( 'MyBtn_1', 'MyBtn_2', 'MyBtn_3' )