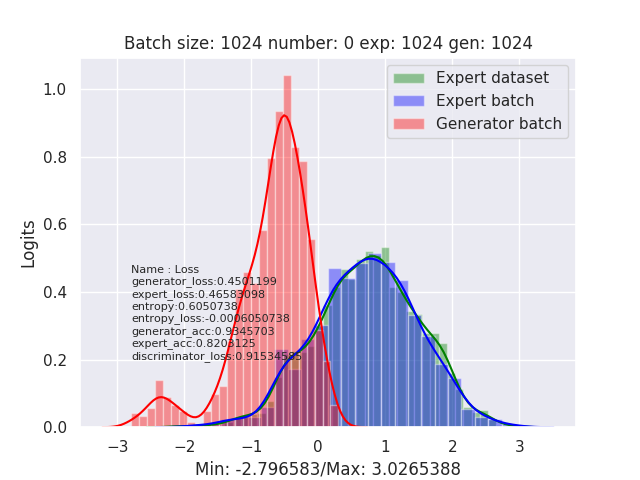
I'm currently training a WGAN in keras with (approx) Wasserstein loss as below:
def wasserstein_loss(y_true, y_pred):
return K.mean(y_true * y_pred)
However, this loss can obviously be negative, which is weird to me.
I trained the WGAN for 200 epochs and got the critic Wasserstein loss training curve below.
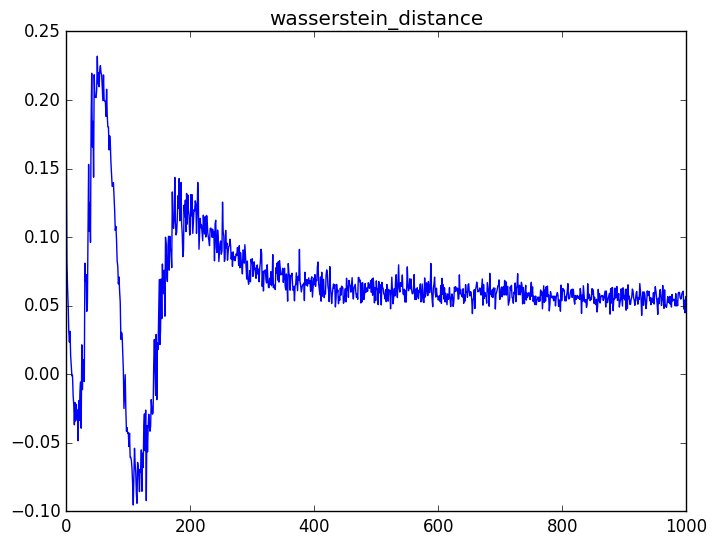
The above loss is calculated by
d_loss_valid = critic.train_on_batch(real, np.ones((batch_size, 1)))
d_loss_fake = critic.train_on_batch(fake, -np.ones((batch_size, 1)))
d_loss, _ = 0.5*np.add(d_loss_valid, d_loss_fake)
The resulting generated sample quality is great, so I think I trained the WGAN correctly. However I still cannot understand why the Wasserstein loss can be negative and the model still works. According to the original WGAN paper, Wasserstein loss can be used as a performance indicator for GAN, so how should we interpret it? Am I misunderstand anything?