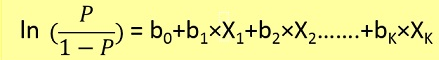Just to add on the previous answers.
Linear regression
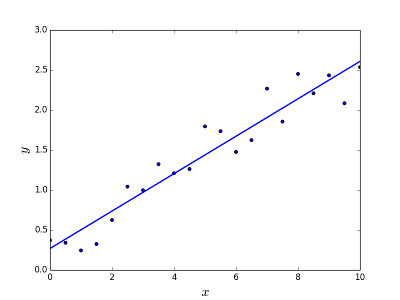
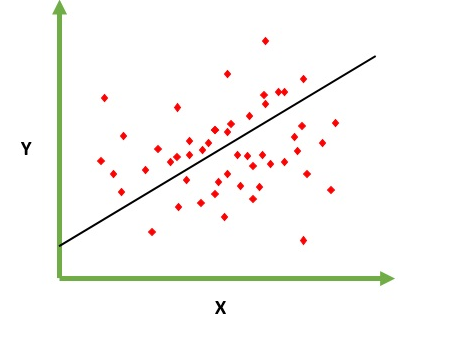
Is meant to resolve the problem of predicting/estimating the output value for a given element X (say f(x)). The result of the prediction is a continuous function where the values may be positive or negative. In this case you normally have an input dataset with lots of examples and the output value for each one of them. The goal is to be able to fit a model to this data set so you are able to predict that output for new different/never seen elements. Following is the classical example of fitting a line to set of points, but in general linear regression could be used to fit more complex models (using higher polynomial degrees):
![enter image description here]()
Resolving the problem
Linear regression can be solved in two different ways:
- Normal equation (direct way to solve the problem)
- Gradient descent (Iterative approach)
Logistic regression
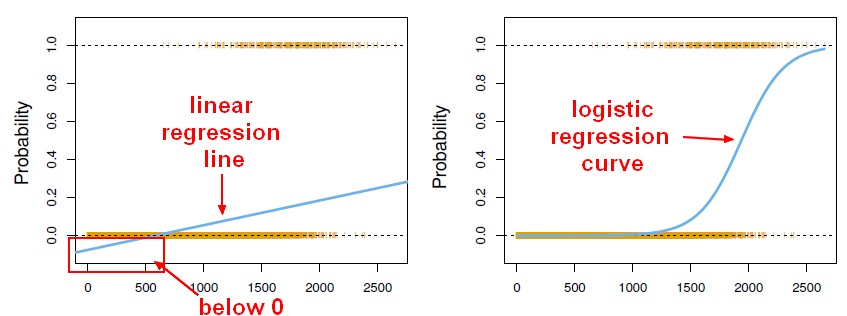
Is meant to resolve classification problems where given an element you have to classify the same in N categories. Typical examples are, for example, given a mail to classify it as spam or not, or given a vehicle find to which category it belongs (car, truck, van, etc ..). That's basically the output is a finite set of discrete values.
Resolving the problem
Logistic regression problems could be resolved only by using Gradient descent. The formulation in general is very similar to linear regression the only difference is the usage of different hypothesis function. In linear regression the hypothesis has the form:
h(x) = theta_0 + theta_1*x_1 + theta_2*x_2 ..
where theta is the model we are trying to fit and [1, x_1, x_2, ..] is the input vector. In logistic regression the hypothesis function is different:
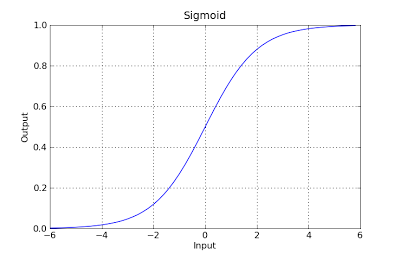
g(x) = 1 / (1 + e^-x)
![enter image description here]()
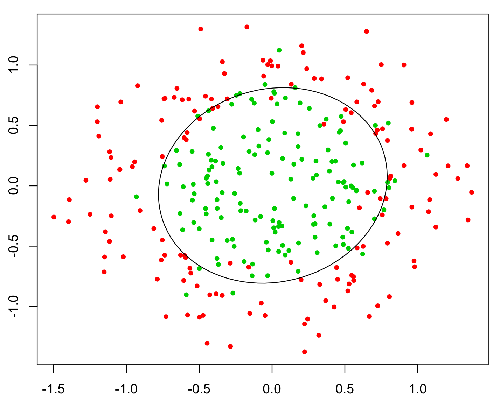
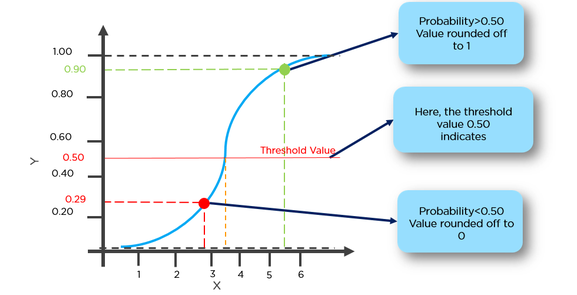
This function has a nice property, basically it maps any value to the range [0,1] which is appropiate to handle propababilities during the classificatin. For example in case of a binary classification g(X) could be interpreted as the probability to belong to the positive class. In this case normally you have different classes that are separated with a decision boundary which basically a curve that decides the separation between the different classes. Following is an example of dataset separated in two classes.
![enter image description here]()
You can also use the below code to generate the linear regression
curve
q_df = details_df
# q_df = pd.get_dummies(q_df)
q_df = pd.get_dummies(q_df, columns=[
"1",
"2",
"3",
"4",
"5",
"6",
"7",
"8",
"9"
])
q_1_df = q_df["1"]
q_df = q_df.drop(["2", "3", "4", "5"], axis=1)
(import statsmodels.api as sm)
x = sm.add_constant(q_df)
train_x, test_x, train_y, test_y = sklearn.model_selection.train_test_split(
x, q3_rechange_delay_df, test_size=0.2, random_state=123 )
lmod = sm.OLS(train_y, train_x).fit() lmod.summary()
lmod.predict()[:10]
lmod.get_prediction().summary_frame()[:10]
sm.qqplot(lmod.resid,line="q") plt.title("Q-Q plot of Standardized
Residuals") plt.show()