Your code could be simplified with the use of worksheet.add_write_handler() to detect the list and call worksheet.write_rich_string() automatically from worksheet.write without having to manually check the type. You'd think
worksheet.add_write_handler(list, xlsxwriter.worksheet.Worksheet.write_rich_string)
should work but doesn't because of some issue with the varargs for that method getting mangled (the last arg is optional styling for the whole cell). So instead the following does work
worksheet.add_write_handler(list, lambda worksheet, row, col, args: worksheet._write_rich_string(row, col, *args))
Unfortunately, this approach isn't easily compatible with pd.to_excel because it has to be set on the worksheet before the data is written and because ExcelWriter serializes lists and dicts to strings before writing (there is a note in the documentation that says this is to be compatible with CSV writers).
Subclassing pd.io.excel._xlsxwriter._XlsxWriter can work:
import xlsxwriter, pandas as pd
class RichExcelWriter(pd.io.excel._xlsxwriter._XlsxWriter):
def __init__(self, *args, **kwargs):
super(RichExcelWriter, self).__init__(*args, **kwargs)
def _value_with_fmt(self, val):
if type(val) == list:
return val, None
return super(RichExcelWriter, self)._value_with_fmt(val)
def write_cells(self, cells, sheet_name=None, startrow=0, startcol=0, freeze_panes=None):
sheet_name = self._get_sheet_name(sheet_name)
if sheet_name in self.sheets:
wks = self.sheets[sheet_name]
else:
wks = self.book.add_worksheet(sheet_name)
#add handler to the worksheet when it's created
wks.add_write_handler(list, lambda worksheet, row, col, list, style: worksheet._write_rich_string(row, col, *list))
self.sheets[sheet_name] = wks
super(RichExcelWriter, self).write_cells(cells, sheet_name, startrow, startcol, freeze_panes)
writer = RichExcelWriter('pandas_with_rich_strings_class.xlsx')
workbook = writer.book
bold = workbook.add_format({'bold': True})
italic = workbook.add_format({'italic': True})
red = workbook.add_format({'color': 'red'})
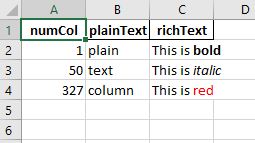
df = pd.DataFrame({
'numCol': [1, 50, 327],
'plainText': ['plain', 'text', 'column'],
'richText': [
['This is ', bold, 'bold'],
['This is ', italic, 'italic'],
['This is ', red, 'red']
]
})
df.to_excel(writer, sheet_name='Sheet1', index=False)
writer.save()
Alternately we can keep the use of xlsxwriter directly and the use the ExcelFormatter from pandas which also handles the header formatting and takes many of the same arguments that to_excel takes.
import xlsxwriter, pandas as pd
from pandas.io.formats.excel import ExcelFormatter
workbook = xlsxwriter.Workbook('pandas_with_rich_strings.xlsx')
worksheet = workbook.add_worksheet()
# Set up some formats to use.
bold = workbook.add_format({'bold': True})
italic = workbook.add_format({'italic': True})
red = workbook.add_format({'color': 'red'})
df = pd.DataFrame({
'numCol': [1, 50, 327],
'plainText': ['plain', 'text', 'column'],
'richText': [
['This is ', bold, 'bold'],
['This is ', italic, 'italic'],
['This is ', red, 'red']
]
})
worksheet.add_write_handler(list, lambda worksheet, row, col, args: worksheet.write_rich_string(row, col, *args))
cells = ExcelFormatter(df, index=False).get_formatted_cells()
for cell in cells:
worksheet.write(cell.row, cell.col ,cell.val)
workbook.close()
This produces the desired output and no need to loop over the data twice. In fact it uses the same generator that pandas would have used so it's just as efficient as pandas.to_excel() and the formatter class takes many of the same arguments.