I need to non-linearly expand on each pixel value from 1 dim pixel vector with taylor series expansion of specific non-linear function (e^x or log(x) or log(1+e^x)), but my current implementation is not right to me at least based on taylor series concepts. The basic intuition behind is taking pixel array as input neurons for a CNN model where each pixel should be non-linearly expanded with taylor series expansion of non-linear function.
new update 1:
From my understanding from taylor series, taylor series is written for a function F of a variable x in terms of the value of the function F and it's derivatives in for another value of variable x0. In my problem, F is function of non-linear transformation of features (a.k.a, pixels), x is each pixel value, x0 is maclaurin series approximation at 0.
new update 2
if we use taylor series of log(1+e^x) with approximation order of 2, each pixel value will yield two new pixel by taking first and second expansion terms of taylor series.
graphic illustration
Here is the graphical illustration of the above formulation:
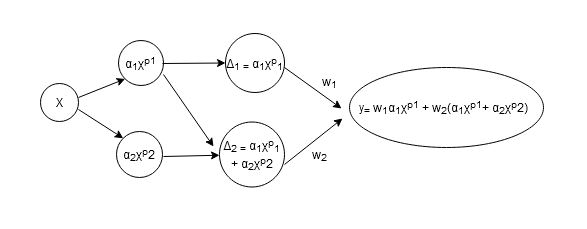
Where X is pixel array, p is approximation order of taylor series, and α is the taylor expansion coefficient.
I wanted to non-linearly expand pixel vectors with taylor series expansion of non-linear function like above illustration demonstrated.
My current attempt
This is my current attempt which is not working correctly for pixel arrays. I was thinking about how to make the same idea applicable to pixel arrays.
def taylor_func(x, approx_order=2):
x_ = x[..., None]
x_ = tf.tile(x_, multiples=[1, 1, approx_order+ 1])
pows = tf.range(0, approx_order + 1, dtype=tf.float32)
x_p = tf.pow(x_, pows)
x_p_ = x_p[..., None]
return x_p_
x = Input(shape=(4,4,3))
x_new = Lambda(lambda x: taylor_func(x, max_pow))(x)
my new updated attempt:
x_input= Input(shape=(32, 32,3))
def maclurin_exp(x, powers=2):
out= 0
for k in range(powers):
out+= ((-1)**k) * (x ** (2*k)) / (math.factorial(2 * k))
return res
x_input_new = Lambda(lambda x: maclurin_exp(x, max_pow))(x_input)
This attempt doesn't yield what the above mathematical formulation describes. I bet I missed something while doing the expansion. Can anyone point me on how to make this correct? Any better idea?
goal
I wanted to take pixel vector and make non-linearly distributed or expanded with taylor series expansion of certain non-linear function. Is there any possible way to do this? any thoughts? thanks
NbyMwith pixel valuesx[i]by a concatenated array of a sizepNbyMwith blocks of elements of a formx[i]**k, withk=1...p, andpas a truncation power of Taylor series? – LathropFof a variablexin terms of the value of the functionFand it's derivatives in for another value of variablex0. So it is unclear to me what is the function and what is the variable when you sayexpand pixel vector with Taylor series expansion. Does the function represent the value of the pixel, while the variable are its coordinates in a 2D array (discrete values)? – Lathropfunction is Taylor expansion of non-linear function. Consider a simple power 2 truncated Taylor series, as it is in your original postF(x) = F(x0) + F'(x0)*(x-x0) + 0.5*F''(x0)*(x-x0)**2. WhatF,xandx0are here? Ifxis the original image, then whatx0is? – Lathropx2 = tf.pow(x, 2)followed byx_tot = tf.concat([x, x2], axis = -2)and use that as an input. But I do not think that there is any benefit in it, as non-linear transforms in activation function tend to give you powers of your inputs. – Lathrop